







本次Lab实验基于MIT OCW来做的,这个是著名的MIT开放课程,MIT 6.830主要是实现数据库设计的,这是底层逻辑设计,主要使用Java、数据结构与算法来完成数据库中的B+树、堆、增删改查等一系列操作。是非常具有意义的课程,具有更好理解数据库底层设计。关于更多的MIT OCW内容请查看前言内容。
如果你是想走后端开发、大数据方向、传统数仓等有关数据库内容方向的,此Lab将会让你成长很多!所以此实验(一共6个Lab)需要一遍两遍三遍甚至是秋招春招的时候再拿出来看。
如果你是大神,请直接学习MIT 6.824 Lab (Go语言完成)前言附路线与校招推荐.
本次MIT 6.830我也是课余抽时间才完成的,所以时间线我也做好了拉半年之久长线的准备了(主要我这个Lab三个部分也花了我不少时间)不得不提的是,MIT Lab全部是英文,很多的资源也都是英文,在国内也有很好的讲解,分别如下:
Mit6.830-SimpleDB-Lab1-学习笔记
前言
MIT OCW主要是MIT为了更好的学习展示的学习平台,全部立足于自学,没有任何老师,但是相当不错的课件、测试、实验等内容。
这是本实验的课程部分:MIT 6.830这是需要完成的代码部分:Lab地址
在MIT 还有几个非常有名的Lab,这里就给大家参考:
MIT 6.006 :INTRODUCTION TO ALGORITHMS(算法导论)
MIT 6.824 : DISTRIBUTED COMPUTER SYSTEMS ENGINEERING (分布式系统)
MIT 6.828:OPERATING SYSTEM ENGINEERING(操作系统,主要任务是实现一个xv6操作系统)
这里面顶级著名的Lab属MIT 6.824莫属了,这是知乎大佬的学习分享:
如何的才能更好地学习 MIT6.824 分布式系统课程? - TianbingJ的回答 - 知乎
https://www.zhihu.com/question/29597104/answer/880513931
评论有人这样回复:

希望各位大神可以试试看!
环境搭建
直接git clone 上面的github地址;
不用去读上面的环境搭建,你可以使用IDEA进行导入项目(记住,需要导入相应的包情况)需要测试的时候直接见下图:
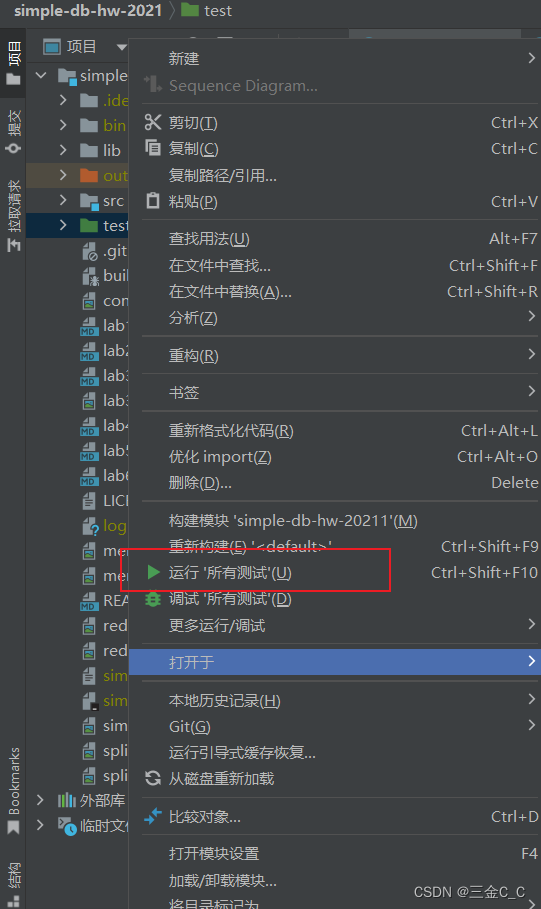
Exercise 1
Tuples: 元祖
TupleDesc:元祖描述
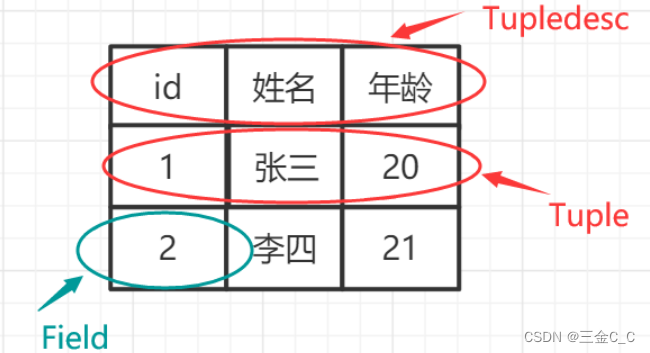
Tuples 在数据库是基础,指一张表的行记录。Tuple被很多数据结构方法所构造(堆、B-树),表示的是TupleDesc的对象。Tuple对象由Type对象构成。
TupleDesc
该文件所在包src/simple/storage/TupleDesc
TupleDesc是用来描述Tuple,简单来说就是属性列的集合。
首先该类有4个私有属性:
private final Type[] types;//type的数组列
private final String[] names;
在此类中定义一个类帮助组织各字段的信息,什么意思呢,以上表来说就是一个字段属性,例如:id (他的字段属性是String)。注意static类是内部类的意思
//静态内部类
//静态内部类只能访问外部类的静态成员 (非静态不可访问)
public static class TDItem implements Serializable {
private static final long serialVersionUID = 1L;
/**
* The type of the field
* */
public final Type fieldType;
/**
* The name of the field
* */
public final String fieldName;
public TDItem(Type t, String n) {
this.fieldName = n;
this.fieldType = t;
}
public String toString() {
return fieldName + "(" + fieldType + ")";
}
}
有了字段信息还不够,需要使用迭代器进行读取。下面这个方法注意是返回迭代器,是将一个表field的字段读取到迭代器中,你可以想成字符串数组的感觉。上面是单个,这边就是全部读取一行的信息。
注意Java的这种写法,return new Interator 很明显的模板写法了。也很容易知道这个方法就是将类写成迭代器的意思。
这里复习一下Iterator的构造方法,从下面的override写法能看出来这是一个接口(为什么,因为没有继承啊)。其中三个方法是非常重要,分别是hasNext() next (后继),remove()
public Iterator<TDItem> iterator() {
// some code goes here
return new Iterator<TDItem>() {
private int idx = -1;
@Override
public boolean hasNext() {
//判断是否有后继
return idx + 1 < types.length;
}
@Override
public TDItem next() {
//有后继那么就返回TDIterm类
if(++idx == types.length) {
throw new NoSuchElementException();
} else {
return new TDItem(types[idx],names[idx]);
}
}
@Override
public void remove() {
}
};
}
下面便是TupleDesc构造方法了。我们想怎么构造TupleDesc需要哪些元素呢?很明显,这就是我们在数据库中建表命令,试想如下:
create table(
name1 varchar(20),
name2 varchar(20)
)
所以我们最低要求就是需要两个构造条件,分别是name与type。
这里构造方法就是使用数组列来构造表的字段。
public TupleDesc(Type[] typeAr, String[] fieldAr) {
// some code goes here
types = new Type[typeAr.length];
for(int i=0;i<typeAr.length;i++) {
types[i] = typeAr[i];
}
names = new String[typeAr.length];
for(int i=0;i<fieldAr.length;i++) {
names[i] = fieldAr[i];
}
}
剩余的构造方法这里就不再赘述了。
很明显,这就是调用前面的构造方法,使用this来进行构造。(说真的,这个构造方法我确实忘了)
public TupleDesc(Type[] typeAr) {
// some code goes here
this(typeAr,new String[0]);
}
//这个就是回fields的数量长度
public int numFields() {
// some code goes here
return types.length;
}
接下来我们前期字段处理、构造方法,那我们是不是要开始做值的处理了呢?
这一步就是返回field的索引值:就是输入name值然后返回该字段属性所在的Index.同时这里也可以做好getsize()
public int fieldNameToIndex(String name) throws NoSuchElementException {
// some code goes here
if(null != name ) {
for(int i=0;i<names.length;i++) {
if(name.equals(names[i])) {
return i;
}
}
}
throw new NoSuchElementException("Unknown Field");
}
public int getSize() {
// some code goes here
int size = 0;
for(int i=0;i<types.length;i++) {
size += types[i].getLen();
}
return size;
}
下面就是比较难的方法了:合并TupleDesc。那么我们想该如何合并两张表呢?
这就是类似我们在数据库中的连接运算符,相同的列只保留一个,不相同的列继续成一个新的表。那么首先这肯定是需要返回一个TupleDesc ,然后我们就开始合并了。但是这里的合并并没有做去重工作就是简单的组合。
public static TupleDesc merge(TupleDesc td1, TupleDesc td2) {
// some code goes here
Type[] types = new Type[td1.types.length+td2.types.length];
String[] names = new String[td1.names.length+td2.names.length];
int idx = 0;
for (int i=0;i<td1.types.length;i++) {
types[idx] = td1.types[i];
names[idx++] = td1.names[i];
}
for (int i=0;i<td2.types.length;i++) {
types[idx] = td2.types[i];
names[idx++] = td2.names[i];
}
return new TupleDesc(types,names);
}
下面就是一个对并工作了。我们需要对并什么呢?很明显就是对比TupleDesc,但是我们采取的是Object传参的方法,然后通过instanceof方法来进行比较。
public boolean equals(Object o) {
// some code goes here
//对比是不是TupleDesc对象,不是的话直接返回false
if(!(o instanceof TupleDesc)) {
return false;
}else {
//强制转换为TupleDesc
TupleDesc other = (TupleDesc) o;
//对比字段数量
if(this.numFields() != other.numFields()) {
return false;
}else {
int n = this.numFields();
for(int i=0;i<n;i++) {
//如果此时此对象的name是空 (注意是this)
if(null == this.getFieldName(i)) {
if (null != other.getFieldName(i)) {
return false;
}
} else if (this.getFieldName(i).equals(other.getFieldName(i))) {
return false;
} else if (this.getFieldType(i) != other.getFieldType(i)) {
return false;
}
}
return true;
}
}
// return true;
}
最后一个就是常规的toString部分了:
比较新颖的做法,就是使用StringBuilder(想想为什么不用String,那当然是String是不可变的呀)
public String toString() {
// some code goes here
StringBuilder sb = new StringBuilder();
int n = this.numFields();
sb.append(getFieldType(0));
sb.append("("+this.getFieldName(0)+")");
for(int i=1;i<n;i++) {
sb.append(","+getFieldType(i));
sb.append("("+this.getFieldName(i)+")");
}
return sb.toString();
}
Tuple
根据前言的说明,Tuple是一行的值,说得专业点就是元组。
首先是私有属性部分:
private TupleDesc td; //类似于表的属性列
private Field[] fields; //单个数据
private RecordId rid; //记录的id部分
构造方法是如何构造的呢?我们想要构造元组,那么TupleDesc肯定少不了。(为什么?,看下面的数据库插入写法)
# 简单写法:
insert into tablename values()
# 正规写法:
insert into tablename(name1,name2,name3) values('','','')
那么从上面我就可以看出插入值,需要字段名和构造的value。
如上代码就出来了:
public Tuple(TupleDesc td) {
// some code goes here
this.td = td;
fields = new Field[td.numFields()]; //预留字段的长度值
}
对于下面的get方法set方法就不再书写,非常简单。
那这个也有toString()方法,这个方法就是返回一行的值,当然了,值就是fields啦
public String toString() {
// some code goes here
//throw new UnsupportedOperationException("Implement this");
StringBuilder sb = new StringBuilder();
sb.append(fields[0].toString());
for(int i=1;i<fields.length;i++) {
sb.append("\t"+fields[i].toString());
}
return sb.toString();
}
关于field的迭代器:
根据上面我们所写的内容:很明显这就是在构造一个迭代器,比较我们都用[]这个符号了,那么迭代器就是必不可少的了。
还是接口(当然了这就是内部类了)
public Iterator<Field> fields()
{
// some code goes here
return new Iterator<Field>() {
private int idx = -1;
@Override
public boolean hasNext() {
return idx+1 < fields.length;
}
@Override
public Field next() {
if(++idx == fields.length) {
throw new NoSuchElementException();
} else {
return fields[idx];
}
}
@Override
public void remove() {
}
};
}
Catalog
Catalog是什么呢?目录。数据库包含很多张表,每张表有一个TupleDesc,以及这个TupleDesc规范下的很多个Tuple。Catalog管理着数据库中的所有表。调用数据库的Catalog需要调用。
Catalog记录着所有的表和他们的相关属性。
私有属性:
后面的key我们容易理解,但是前面的Integer是什么呢?这里规定的就是tableid。
private final Map<Integer,String> names;
private final Map<Integer,DbFile> dbfiles;
private final Map<Integer,String> pkeyFields;
构造器方法,很明显就是对上面私有属性的new
public Catalog() {
// some code goes here
names = new HashMap<Integer, String>();
dbfiles = new HashMap<Integer, DbFile>();
pkeyFields = new HashMap<Integer, String>();
}
添加表的内容到Catalog。我们想添加表需要哪些信息呢?首先就是表名字,其次就是物理文件与主键字段:
public void addTable(DbFile file, String name, String pkeyField) {
// some code goes here
int tableid = file.getId();
// 迭代哈希不会忘了吧(doge)
for(Integer id: names.keySet()) {
if(names.get(id).equals(name)) {
if( id != tableid) {
names.remove(id);
dbfiles.remove(id);
pkeyFields.remove(id);
}
break;
}
}
names.put(tableid,name);
dbfiles.put(tableid,file);
pkeyFields.put(tableid,pkeyField);
}
得到tableid,就是我们之前的Integer,使用get方法获取:
public int getTableId(String name) throws NoSuchElementException {
// some code goes here
for(Integer id: names.keySet()) {
if(names.get(id).equals(name)) {
return id;
}
}
throw new NoSuchElementException();
}
tableid有了,还需要一个getTupleDesc(这里就是用dbfile的get方法了)
public TupleDesc getTupleDesc(int tableid) throws NoSuchElementException {
// some code goes here
if(dbfiles.containsKey(tableid)) {
return dbfiles.get(tableid).getTupleDesc();
}
throw new NoSuchElementException();
}
后面就是简单的get方法了,这里就不再多谈。
下面将进入Catalog类的重点部分:
加载属性 loadSchema:
这一部分的代码非常难以理解,我将逐行解释相应的内容。
public void loadSchema(String catalogFile) {
String line = "";
String baseFolder=new File(new File(catalogFile).getAbsolutePath()).getParent();
try {
//读入流部分
BufferedReader br = new BufferedReader(new FileReader(catalogFile));
while ((line = br.readLine()) != null) {
//assume line is of the format name (field type, field type, ...)
String name = line.substring(0, line.indexOf("(")).trim();
//System.out.println("TABLE NAME: " + name);
String fields = line.substring(line.indexOf("(") + 1, line.indexOf(")")).trim();
String[] els = fields.split(",");
ArrayList<String> names = new ArrayList<>();
ArrayList<Type> types = new ArrayList<>();
String primaryKey = "";
for (String e : els) {
String[] els2 = e.trim().split(" ");
names.add(els2[0].trim());
if (els2[1].trim().equalsIgnoreCase("int"))
types.add(Type.INT_TYPE);
else if (els2[1].trim().equalsIgnoreCase("string"))
types.add(Type.STRING_TYPE);
else {
System.out.println("Unknown type " + els2[1]);
System.exit(0);
}
if (els2.length == 3) {
if (els2[2].trim().equals("pk"))
primaryKey = els2[0].trim();
else {
System.out.println("Unknown annotation " + els2[2]);
System.exit(0);
}
}
}
Type[] typeAr = types.toArray(new Type[0]);
String[] namesAr = names.toArray(new String[0]);
TupleDesc t = new TupleDesc(typeAr, namesAr);
HeapFile tabHf = new HeapFile(new File(baseFolder+"/"+name + ".dat"), t);
addTable(tabHf,name,primaryKey);
System.out.println("Added table : " + name + " with schema " + t);
}
} catch (IOException e) {
e.printStackTrace();
System.exit(0);
} catch (IndexOutOfBoundsException e) {
System.out.println ("Invalid catalog entry : " + line);
System.exit(0);
}
}
BufferPool
buffer pool(在SimpleDB中是BufferPool类)负责将内存最近读过的物理页缓存下来。所有的读写操作通过buffer pool读写硬盘上不同文件,BufferPool里的numPages参数确定了读取的固定页数,在之后的lab中,需要实现淘汰机制(eviction policy)。在这个lab中,只需要实现构造器和BufferPool.getPage()方法,BufferPool应该存取最多numPages个物理页,当前lab中如果页的数量超过numPages,先不实现eviction policy,先扔出一个DbException错误。
这个方法主要不是特别重要,主要就涉及一个getPage()方法:
public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
// some code goes here
int idx = -1;
for(int i=0;i<buffer.length;i++) {
if(null == buffer[i]) {
idx = i;
}else if (pid.equals(buffer[i].getId())) {
try{
lock.acquire(tid,i,perm);
}catch (InterruptedException ex) {
throw new TransactionAbortedException();
}
return buffer[i];
}
}
if( idx < 0 ) {
evictPage();
return getPage(tid,pid,perm);
}else {
try {
lock.acquire(tid,idx,perm);
}catch (InterruptedException ex) {
throw new TransactionAbortedException();
}
return buffer[idx] = Database.getCatalog().getDatabaseFile(pid.getTableId()).readPage(pid);
}
}
测试部分
写了这么多代码,该如何测试是否写得对不对呢?利用JUnit测试模块,可以看到以下功能均通过了。
注意,在Tuple中modifyRecordId未实现,在后面实验中完成。

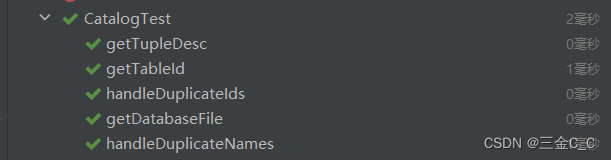
以上就是Lab1 的作业1-3了,是的,后面还有3个作业,哎别的不说了,溜之!















 2909
2909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









