







一、环境搭建
1.课程官网:6.830/6.814: Database Systems
2.Github地址:simple-db-hw-2021
3.安装配置ant
二、实验概览
SimpleDB consists of:
- Classes that represent fields, tuples, and tuple schemas;(字段、元组(即记录)、模式)
- Classes that apply predicates and conditions to tuples;(描述元组)
- One or more access methods (e.g., heap files) that store relations on disk and provide a way to iterate through tuples
of those relations;(访问元组)- A collection of operator classes (e.g., select, join, insert, delete, etc.) that process tuples;(CRUD)
- A buffer pool that caches active tuples and pages in memory and handles concurrency control and transactions (neither
of which you need to worry about for this lab); and,(实现buffer pool及并发控制、事务)- A catalog that stores information about available tables and their schemas.
整个实验一共有6个lab,通过每一个lab的代码去实现一个简单的数据库,主要有:数据库的组织架构(字段、元组、模式、buffer pool等)、sql boy最爱的CRUD的实现、查询优化、事务与并发控制、崩溃与故障恢复。刚做完第一个lab,记录一下方便后面复习。
lab1主要是实现了整个数据库的整体架构,做完会对数据库是怎样组织我们平时的表会有较多的认识,当然,lab1并没有像MySQL那样去实现以B+树形式的聚簇索引来存储数据,主要还是按顺序存储,数据结构非常的简单。
lab1涉及的主要有这几个部分:Tuple(元组)、TupleDesc(table的metadata)、catalog(该数据库并没有过度区分catalog和schema,可以看成是一个schema)、BufferPool(缓冲池)、HeapPage(数据页)、HeapFile(disk上的文件)、SeqScan(全表顺序扫描),下面是各个部分的介绍与联系:
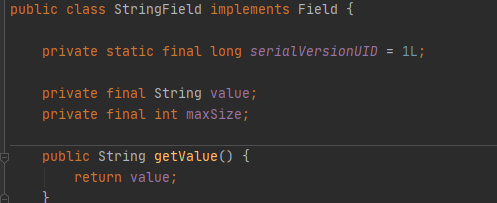
1.Tuple:元组,数据库上把一个有n列的table称作n元组,一个Tuple有多个字段。通俗来讲,一条记录就是一个元组,在该实验中体现为一个Tuple类的实例。一个Tuple由以下部分组成:a.TupleDesc:该元组的描述信息;b.fields:该记录各个字段的类型与值; c.RecordId:该记录在磁盘的位置。
2.TupleDesc:TupleDesc用来表示一个元组的描述信息,更准确来说应该是一个表的描述信息;
3.Catalog:Catalog是仅次于DataBase的抽象概念,一个DataBase可以有多个Catalog,一个Catalog有多个Schema,一个Schema有多张table,不过该数据库没有太过区分这三个概念,而在MySQL中也是用Schema来表示整个数据库包含的多张table。该lab中实现了一个Table类,并在Catalog类中使用一个HashMap来存放table id与table的映射关系。
4.BufferPool:BufferPool的基本单位是Page,每次从磁盘中(这里表现为DbFile)读取数据页到BufferPool,在数据库上的crud操作都是在Buffer Pool的Page中进行的(所以有脏页、故障恢复等)。该数据库的BufferPool默认是缓冲50个Page,每个Page的默认大小是4096bytes即4kb。lab1主要是实现getPage方法,从BufferPool中获取Page,如果获取不到,就在磁盘中获取,并保存到BufferPool中。当然,当BufferPool满了之后,需要有淘汰策略,后续的lab会实现,应该是使用LRU算法来做的。
5.HeapPage与HeapFile:HeapPage是Page接口的实现,是以顺序逻辑组织数据的一张数据页(后续会用b+树实现来替代),crud操作都是在Page上进行的。HeapPage既是BuffeerPool的基本单位也是HeapFile的基本单位。HeapFile是DbFile接口的实现,与磁盘中的文件交互,该数据中一张表的所有数据就是存到DbFile的File属性中,即一个磁盘的文件就是一张表的所有数据。
6.SeqScan:全表顺序扫描的实现,相当于select * from my_table.
这些组成部分的关系如下图所示:
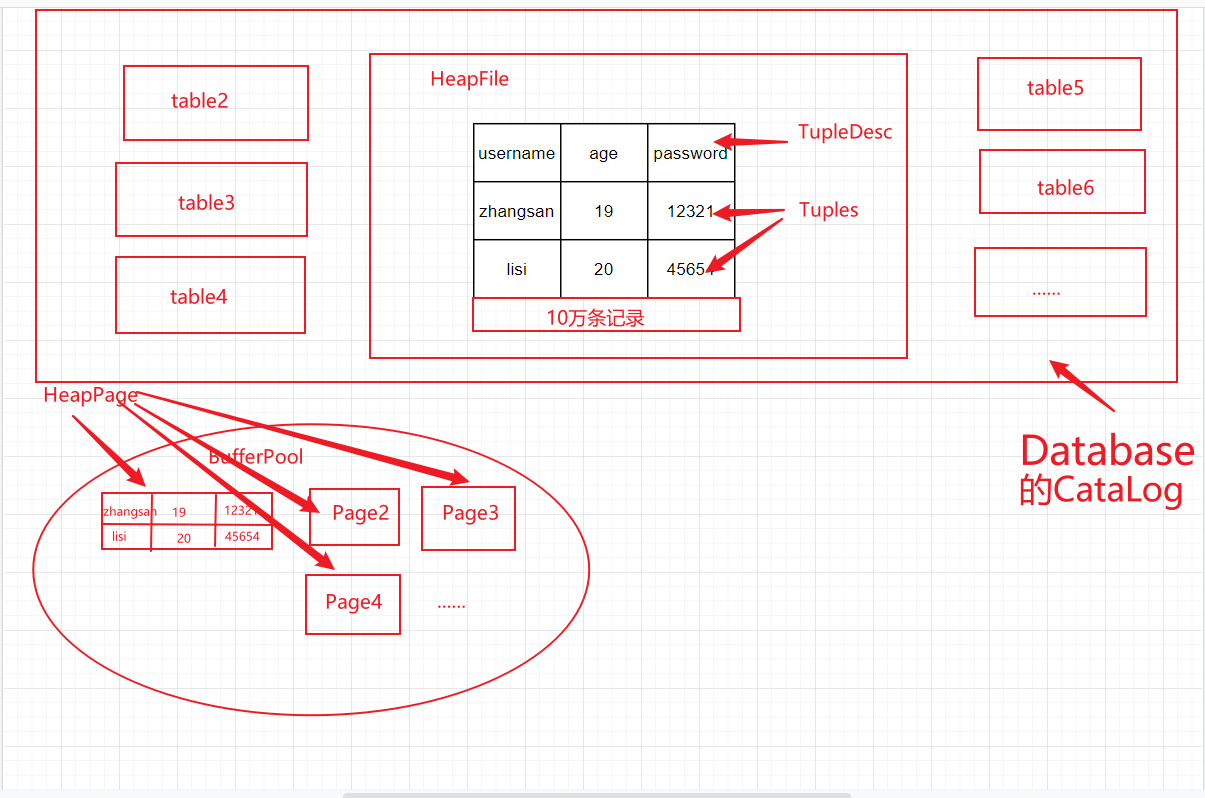
除了上述信息,该实验还提供了一个DataBase类,可以理解成一个数据库的全局信息,可以说是一个数据库的入口,主要由以下三部分组成:
catalog:存放实际的表格,而每张表格的描述信息应该放在了TupleDesc中;
BufferPool:实际进行crud操作的地方,buffer pool以page为单位从磁盘中读入。
LogFile:日志文件。
三、实验过程
Exercise1
Tuples in SimpleDB are quite basic. They consist of a collection of
Fieldobjects, one per field in theTuple.Fieldis an interface that different data types (e.g., integer, string) implement.Tupleobjects are created by the underlying access methods (e.g., heap files, or B-trees), as described in the next section. Tuples also have a type (or schema), called a tuple descriptor, represented by aTupleDescobject. This object consists of a collection ofTypeobjects, one per field in the tuple, each of which describes the type of the corresponding field.
exercise1主要是实现Tuple与TupleDesc这两个类的构造器和主要方法,较为简单。
Tuple:包含td,rid,fields三个属性,一条记录最基本的信息,其它的就是一些构造器,getter方法和迭代器等,看着注释实现就可以了。
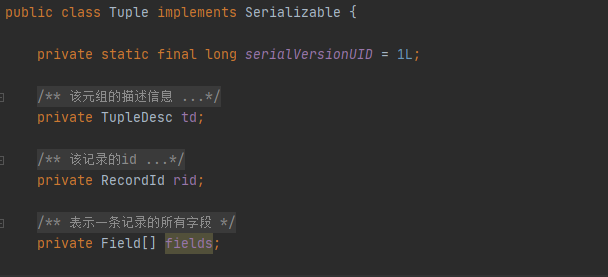
其中Field是字段的实现,点进去看可以看到主要是Type来存储字段类型
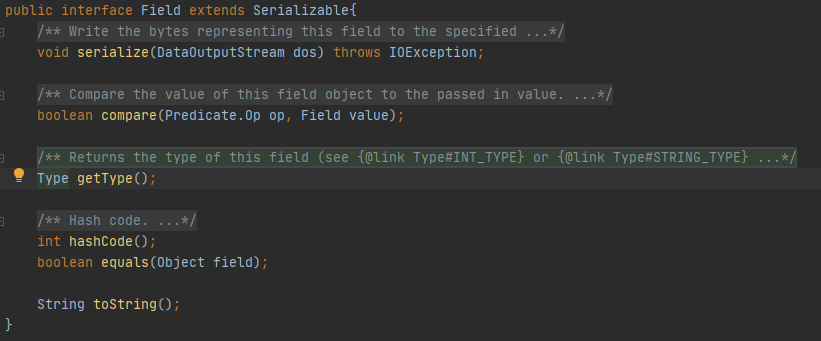
而Type是类型的枚举,该数据库支持int类型和String类型,类型信息描述都在里面,后面也可在Type中扩展数据类型:
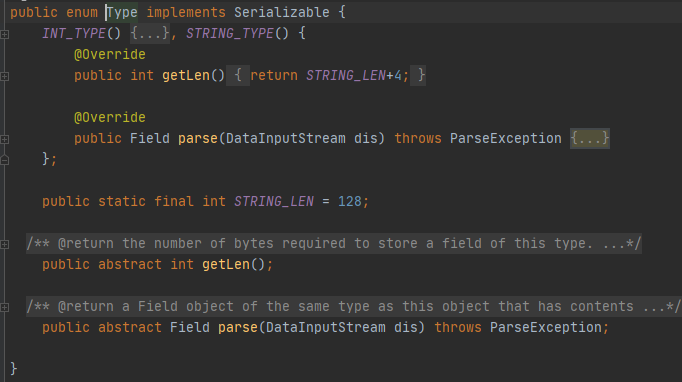
根据字段的类型,parse方法可以返回具体的Field实现类,即带有类型的Field,里面用value来存储字段值:
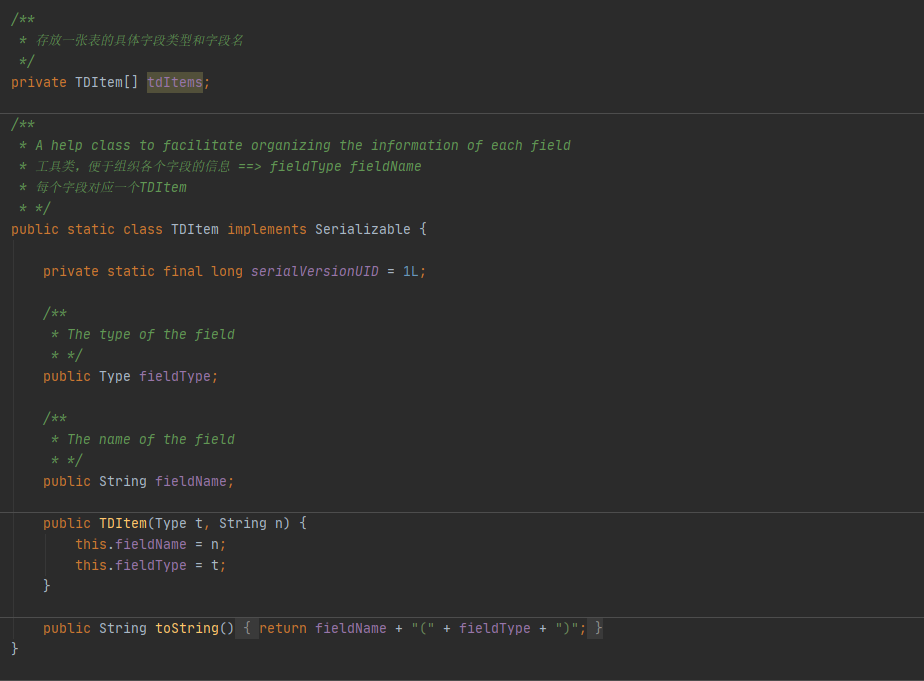
TupleDesc:TupleDesc主要是需要实现一个TDItem内部类来表示一个字段的描述信息,包括字段类型,字段名;TupleDesc中用一个TDItem数组来表示多个字段的描述信息,有了这个,后面做起来就简单很多了。
Exercise2
The catalog (class
Cat
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









