







与图像识别不同,在自然语言处理中输入的往往是一段语音或者一段文字,输入数据的长短是不确定的,并且它与上下文有很密切的关系,所以常用的是循环神经网络(recurrent neural network,RNN)模型
11.1 模型的选择
使用不同输入和不同数据时,分别适用哪种模型以及如何应用
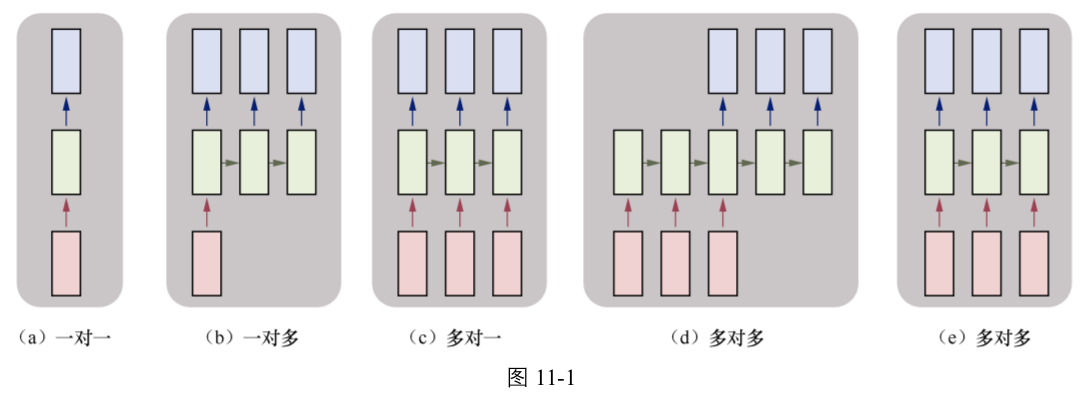
(1)一对一:没有使用RNN,如Vanilla模型,从固定大小的输入得到固定大小输出(应用在图像分类)
(2)一对多:以序列输出(应用在图片描述,输入一张图片输出一段文字序列,这种往往需要CNN和RNN相结合,也就是图像和语言结合)
(3)多对一:以序列输入(应用在情感分析,输入一段文字,然后将它分类成积极或者消极情感,如淘宝下某件商品的评论分类),如使用LSTM
(4)多对多:异步的序列输入和序列输出(应用在机器翻译,如一个RNN读取一条英文语句,然后将它以法语形式输出)。
(5)多对多:同步的序列输入和序列输出(应用在视频分类,对视频中每一帧打标记)。
因为中间RNN的状态的部分是固定的,可以多次使用,所以不需要对序列长度进行预先特定约束。参见Andrej Karpathy 的文章《The Unreasonable Effectiveness of Recurrent Neural Networks》
11.2 英文数字语音识别
数据集,构建LSTM循环神经网络,用TFLearn第三方库来训练
本节代码参本 https://github.com/pannous/tensorflow-speech-recognition/blob/master/speech2text-tflearn.py
定义输入数据并预处理数据:用到梅尔频率倒谱系数(MFCC)特征向量,一种在自动语音和说话人识别广泛使用的特征。
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import tflearn
import speech_data
import tensorflow as tf
learning_rate = 0.0001
training_iters = 300000
batch_size = 64
width = 20 # MFCC特征
height = 80 # 最大发音长度
classes = 10 # 数字类别
# 对语音做分帧、取对数、逆变换等操作后,生成的MFCC就代表这个语音的特征
batch = word_batch = speech_data.mfcc_batch_generator(batch_size) #生成每一批MFCC语音
X, Y = next(batch)
trainX, trainY = X, Y
testX, testY = X, Y
# 定义网络模型
net = tflearn.input_data([None, width, height])
net = tflearn.lstm(net, 128, dropout=0.8)
net = tflearn.fully_connected(net, classes, activation='softmax')
net = tflearn.regression(net, optimizer='adam', learning_rate=learning_rate, loss='categorical_crossentropy')
# 训练模型
model = tflearn.DNN(net, tensorboard_verbose=0)
while 1:
model.fit(trainX, trainY, n_epoch=10, validation_set=(testX, testY), show_metric=True, batch_size=batch_size)
_y = model.predict(X)
model.save("tflearn.lstm.model")
# 预测模型
demo_file = "5_Vicki_260.wav"
demo = speech_data.load_wav_file(speech_data.path + demo_file)
result = model.predict([demo])
result = numpy.argmax(result)
print("predicted digit for %s : result = %d "%(demo_file, result))11.3 智能聊天机器人
智能聊天机器人的商业价值有两个方面:
- 通过和用户的“语音机器人”的对话,将用户引导到对应的服务上面。
- 作为今后智能硬件和智能家居的嵌入式应用
经历了3代不同的技术:
- 基于特征工程。大量的逻辑判断
- 基于检索库
- 基于深度学习。采用seq2seq+Attention模型,经过大量的训练,根据输入生成相应的输出。
seq2seq模型是一个翻译模型,主要是把一个序列翻译成另一个序列。它的基本思想是用两个RNNLM,组成RNN编码器-解码器。在文本处理领域,常用编码器-解码器框架
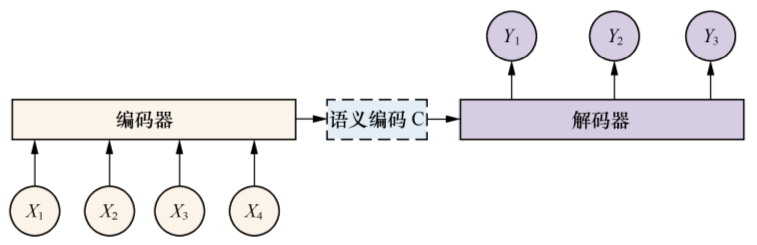
对于一个句子对<X, Y>,X由x1,x2等单词序列组成,Y也由y1, y2等单词序列组成。在句子比较短的时候,还能比较贴切,句子长是,就明显不合语义了。
在实际实现聊天系统的时候,一般编码器和解码器都采用RNN模型以及LSTM。但句子长度超过30以后,LSTM模型的效果会急剧下降,一般此时会引入Attention模型,对长句子来说能够明显提升系统效果。
Attention机制是认知心理学层面的一个概念,它是指当人在做一件事情的时候,会专注地做这件事而忽略周围的其他事。这种机制应用在聊天机器人、机器翻译等领域,就把源句子中对生成句子重要的关键词的权重提高,产生出更准确的应答。
增加了Attention模型的编码器-解码器框架,现在的中间语义编码变成了不断变化的Ci,能够生产更准确的目标Yi。
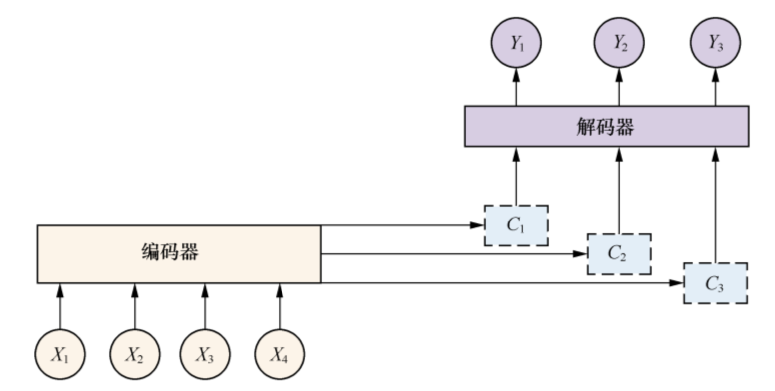
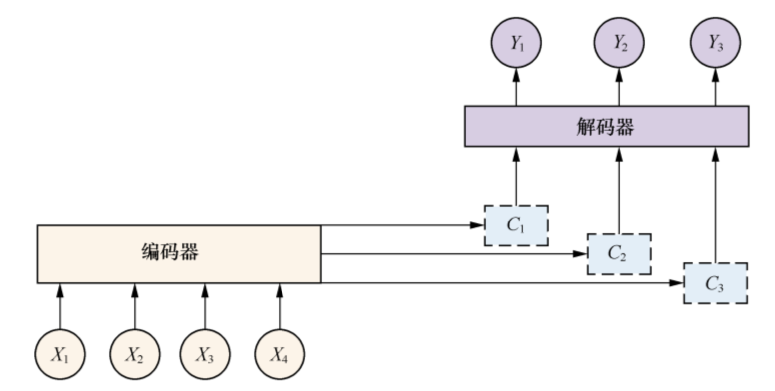
本节代码参本 https://github.com/suriyadeepan/easy_seq2seq
使用康莱尔大学的Corpus数据集(Cornell Movie Dialogs Corpus),里面含有600多部电影的对白。
处理聊天数据:
(1)先把数据集整理成“问”和“答”的文件,生成.enc(问句)和.dec(答句)文件,
- test.dec # 测试集答句
- test.enc # 测试集问句
- train.dec # 训练集答句
- train.enc # 训练集问句
(2)创建词汇表,然后把问句和答句转换成对应的id形式。词汇表的文件里面有2万个词汇,如下:
- vocab20000.dec # 答句的词汇表
- vocab20000.enc # 问句的词汇表
词汇表的内容如下:
_ PAD
_ GO
_ EOS
_ UNK
.
'
,
I
?
you
the
to
a
s
t
it
其中_GO、_EOS、_UNK、_PAD是在seq2seq模型中使用的特殊标记,用来填充标记对话:_GO标记对话开始;_EOS标记对话结束;_UNK标记未出现在词汇表中的字符,用来替换稀有词汇;_PAD是用来填充序列,保证批次中的序列有相同的长度。
转换成的ids文件如下:
- test.enc.ids20000
- train.dec.ids20000
- train.enc.ids20000
问句和答句转换成的ids文件中,每一行是一个问句或答句,每一行中的每一个id代表问句或答句中对应位置的词,格式如下:
185 4 4 4 146 131 5 1144 39 313 53 102 1176 12042 4 2020 9 2691 9
792 15 4
(3)采用编码器-解码器框架进行训练
定义训练参数,seq2seq.ini
[strings]
# 模式:train, test, serve
mode = train
train_enc = data/train.enc
train_dec = data/train.dec
test_enc = data/test.enc
test_dec = data/test.dec
# 模型文件和词汇表的存储路径
working_directory = working_dir/
[ints]
# 词汇表大小
enc_vocab_size = 20000
dec_vocab_size = 20000
# LSTM层数
num_layers = 3
# 每层大小,可以取值:128, 256, 512, 1024
layer_size = 256
max_train_data_size = 0
batch_size = 64
# 每多少次迭代存储一次模型
steps_per_checkpoint = 300
[floats]
learning_rate = 0.5
learning_rate_decay_factor = 0.99
max_gradient_norm = 5.0参本论文《Grammar as a Foreign Language》:http://arxiv.org/abs/1412.7449















 101
101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









