







 本文介绍了一种基于自然语言处理的空间关系抽取技术,包括语料预处理、依存关系获取及空间关系三元组的抽取方法。
本文介绍了一种基于自然语言处理的空间关系抽取技术,包括语料预处理、依存关系获取及空间关系三元组的抽取方法。
0.引入
空间关系是指存在于实体之间的具有空间特征的关系,如方位关系、距离关系、拓扑关系、层次关系等。空间关系在自然语言描述中一般具有三个部分或者两个层次。三个部分是从认知学的角度出发的将其分为射体、界标和方位词,其中:
- 射体是空间关系中的主体成分。
- 方位词是用来描述实体之间的空间方向和位置关系的,通常与其前面的名词构成句子中的处所格。
- 界标则为射体的方位提供了参照物依据。
例如S1:杯子在桌子上。S1 中包含空间表达式(在,上,桌子)。
则杯子为射体,桌子为界标,上为方位词。
获取空间关系就需要找出句子中的空间表达式。首先要对原始语料进行预处理。然后抽取其中的空间关系。
1.语料预处理
1.1. 获得句子分词后的依存关系
基于哈工大的自然语言处理技术,使用它的API对句子进行分词,并得到它的依存关系。
用户通过指定API参数来获取对应的结果,语言云服务的API参数集链接如下:
http://www.ltp-cloud.com/document/
在语言云中,所有的API访问都是通过HTTP请求的方式。并且需要从api.ltp-cloud.com域进行访问。语言云只支持GET和POST方式的HTTP请求。用户通过在HTTP请求中指定参数来获取对应的结果。
举个例子,对“房顶上落着一只小鸟”这句话做依存句法分析。
这句话的依存关系的句子视图如下:
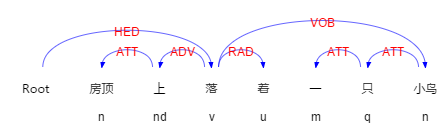
图1-1例句的依存关系
返回xml格式的结果。GET请求及返回结果示例:
GET http ://api.ltp-cloud.com/analysis/?api_key=U1H0S1Z1CkcUtrLouJvyHVNSOWkY9ycmAVahcduW&text=房顶上落着一只小鸟&pattern=all&format=xml

图1-2 例句的xml标准结果
-
这句话的XML标准结果如下:结点标签分别为 xml4nlp, note, doc, para, sent, word,arg 共七种结点标签:
1、xml4nlp 为根结点,无任何属性值;
2、note 为标记结点,具有的属性分别为:sent, word, pos, ne, parser, srl;分别代表分句,分词,词性标注,命名实体识别,依存句法分析,词义消歧,语义角色标注;值为”n”,表明未做,值为”y”则表示完成,如pos=”y”,表示已经完成了词性标注;
3、doc 为篇章结点,以段落为单位包含文本内容;无任何属性值;
4、para 为段落结点,需含id 属性,其值从0 开始;
5、sent 为句子结点,需含属性为id,cont;id 为段落中句子序号,其值从0 开始;cont 为句子内容;
6、word 为分词结点,需含属性为id, cont;id 为句子中的词的序号,其值从0 开始,cont为分词内容;可选属性为 pos, ne, parent, relate , semparent,semrelate;pos 的内容为词性标注内容;ne 为命名实体内容;parent 与 relate 成对出现,parent 为依存句法分析的父亲结点id 号,relate 为相对应的关系;semparent 与 semrelate 成对出现,semparent 为语义依存分析的父亲结点id 号,semrelate 为相对应的关系;
7、arg 为语义角色信息结点,任何一个谓词都会带有若干个该结点;其属性为id, type, beg,end;id 为序号,从0 开始;type 代表角色名称;beg 为开始的词序号,end 为结束的序号;
各结点及属性的逻辑关系说明如下:
-
1、各结点层次关系可以从图中清楚获得,凡带有id 属性的结点是可以包含多个;
2、如果sent=”n”即未完成分句,则不应包含sent 及其下结点;
3、如果sent=”y” word=”n”即完成分句,未完成分词,则不应包含word 及其下结点;
4、其它情况均是在sent=”y” word=”y”的情况下:
-
(1)如果 pos=”y” 则分词结点中必须包含pos 属性;
(2)如果 ne=”y” 则分词结点中必须包含ne 属性;
(3)如果 parser=”y” 则分词结点中必须包含parent 及relate 属性;
(4)如果 semparser=”y” 则分词结点中必须包含semparent 及semrelate 属性;
(5)如果 srl=”y” 则凡是谓词(predicate)的分词会包含若干个arg 结点;
在XML格式的分析中,用户可以通过指定参数pattern=ws | pos | ner | dp | sdp | srl | all 来指名分析任务并获取对应的XML结果。
-
(1)如果 pos=”y” 则分词结点中必须包含pos 属性;
-
1、各结点层次关系可以从图中清楚获得,凡带有id 属性的结点是可以包含多个;
1.2. 把依存关系保存为XML文件
将依存关系以XML格式的字符串的形式把保存到XML文件。
例“房顶上落着一只小鸟”这句话的依存关系的XML格式如图所示:

图 1-3 例句依存关系的XML
1.3解析XML文件获得每个词的属性
使用dom4j解析XML文件,获得节点下各属性值(如上图红框内所示)。创建一个实体类Word,成员变量对应着XML文件中节点的各属性。把解析得到的每个词的属性值作为Word实例保存到一个List里面。

图 1-4 节点属性
2.空间关系三元组抽取
通过语料预处理得到的一个短句中所有词的词性、依存关系和句子的句法结构等信息,根据这些信息再加上我们的认知常识来识别出空间关系三元组。
先根据一个短句中的方位词个数来确定短句中至少有多少个三元组,之后对于每一个方位词,去确定其界标和射体,如果存在多个射体,那么复制方位词和界标,增添三元组的数量。
例:“小明和奥巴马在屋子后面的桥上钓鱼。”
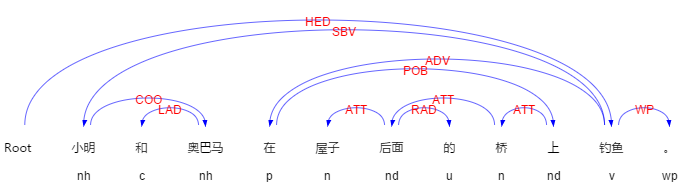
图2- 1例句的句法分析和词性标注
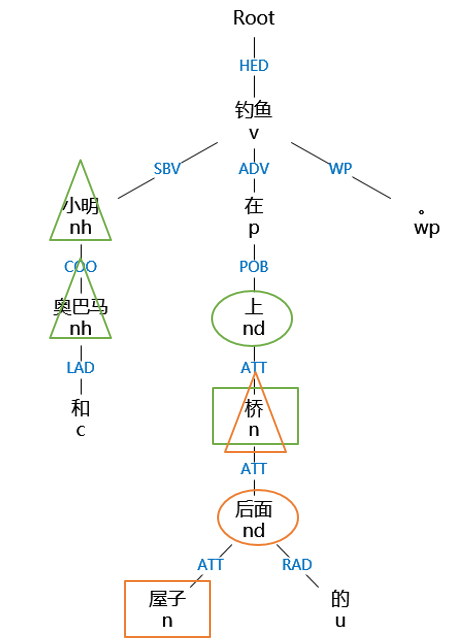
图2-2 例句的句法分析树
如上图,例句中识别出的方位词为“后面”和“上”,方位词的个数为2,则可确定至少有两个三元组,根据依存关系为ATT(定中关系)的方位词的子节点,确定界标分别为“屋子”和“桥”,之后再根据方位词来找到三元组中的射体(具体的方法下面做介绍),因为有一个三元组的射体为“小明”和“奥巴马”,所以要将“小明”的界标和方位词复制给“奥巴马”,然后将新的三元组增添到结果三元组列表中。
2.1方位词的识别
通过遍历一个短句中所有的词,找出其中词性为“nd”(direction noun)的词来作为方位词。
哈工大的语言技术平台的分词系统中有一百余种固定的方位词,比如“东北面”、“前后”等,所以短句中方位词的识别比较精确,不会存在方位词分开识别的情况。

图2-3方位词识别
2.2界标的识别
将2.1中识别出的方位词添加到相应的三元组中,对于当前的每一个三元组,根据其中的方位词去识别界标,经过大量考察例句,在句法分析树中,界标是方位词的子节点,界标的依存关系是ATT(定中关系),根据这样的规则,识别出相应三元组中的界标。
例“房顶上落着一只小鸟”这句话的依存关系如图 3-2 所示:
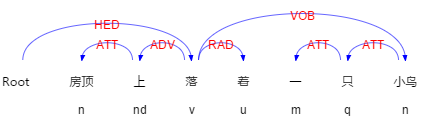
图 2-4 依存关系和词性标注
例“他站在房子前”这句话的依存关系如图 3-3 所示:
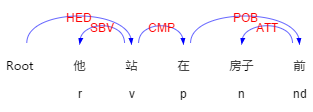
图 2-5 依存关系和词性标注
当依存关系ATT中方位词的直接依存对象不是界标的时候,比如“大象的背上有一只蚂蚁”
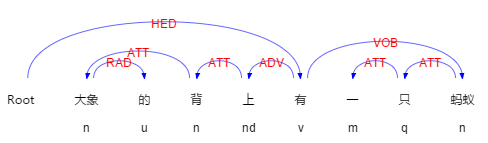
图2-6依存关系和词性标注
在上图可以看到依存关系ATT(上—>背)、(背—>大象),此时方位词“上”的直接依存对象并不是界标,但是“背”的直接依存对象是界标。,从它的义原得知“背”是部件,因此不能作为界标,确定大象是界标。
界标识别算法如下:
-
① 确定方位词子节点的依存关系 ATT。
② 在方位词依存关系 ATT 中得到方位词的直接依存对象 X1。
③ 查找 X1 是否为部件,如果不是转(4),否则转(5)
④ 确定X1为界标。结束。
⑤ 得到X1的依存关系ATT,从依存关系ATT的到X1的直接依存对象X2,更新 X1的值为X2。转③。
2.3射体识别
2.3.1简单射体识别
根据短句中方位词的重要性来对方位词进行分类,与句法分析树的根节点直接相关的方位词可以视为主要方位词;相对的,远离根节点且方位词的依存关系为ATT的方位词可以视为次要方位词。
如下图,例子“小明和奥巴马在屋子后面的桥上钓鱼。”中,三元组为(小明,桥,上)、(奥巴马,桥,上)、(桥,屋子,后面),其中“上”是主要方位词,“后面”是次要方位词。下面就根据方位词的分类来对相应的射体进行识别。
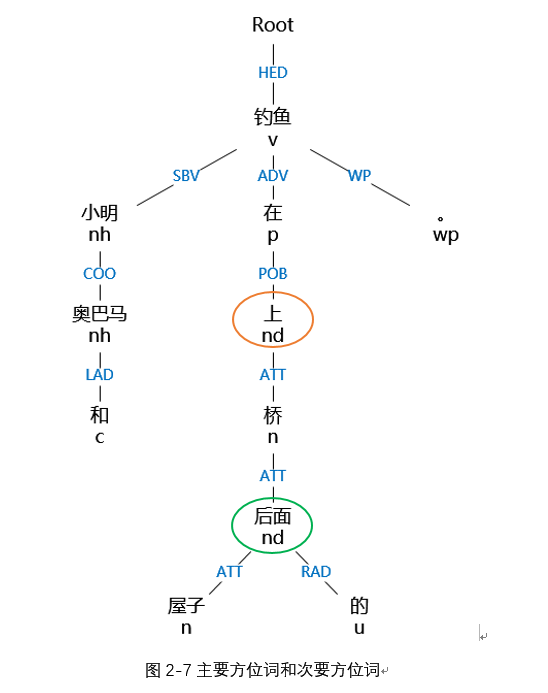
(1)方位词是主要方位词。
当方位词是主要方位词的时候,父节点的依存关系是HED(核心关系)或者父节点的父节点(或者更多)的依存关系为HED,如图3-9中的例子,“上”的父节点的父节点的依存关系是HED。
从方位词开始一层一层地向上获取节点,直到获取到依存关系为HED的节点,然后遍历找出该节点子节点中词性为名词“n”(或包含“n”)和代词“r”的节点。在上面的例子中就可以找到上的射体“小明”。
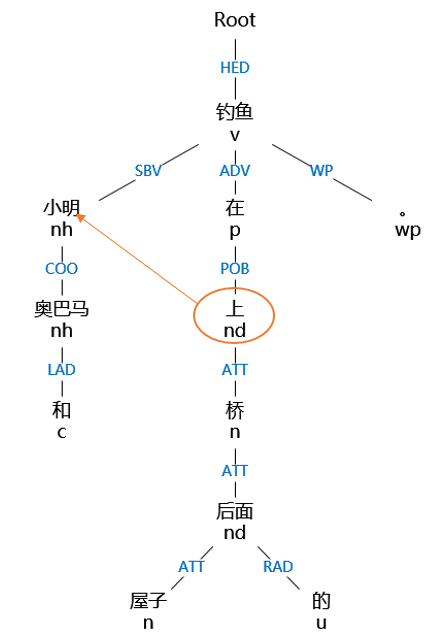
图2-8句法分析树
例“屋子前的桌子上有一个水杯”其中主要方位词“上”的射体是“水杯”。这句话的依存关系和句法分析树如图 2-8、2-9 所示:
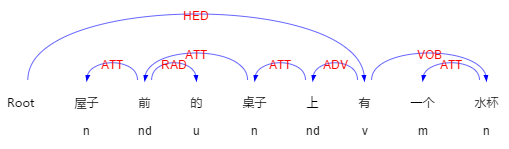
2-9依存关系
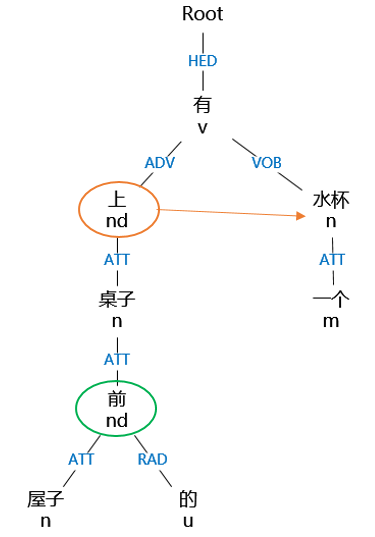
图2-10句法分析树
(2) 方位词是次要方位词。
当方位词是次要方位词的时候,方位词的依存关系是ATT(定中关系),且直接依存的对象是名词“n”(或者包含“n”的词性,比如“小明”“nh”)或者代词“r”时,可以判定这个词就是次要方位词的射体。
例子“小明和奥巴马在屋子后面的桥上钓鱼。”中,次要方位词“后面”的依存关系为ATT,直接依存的对象是“桥”词性“n”,符合上面的要求,所以“桥”就是“后面”的射体。

简单射体识别算法如下:
-
① 判断方位词是否为次要方位词(依存关系是否为ATT),如果是,转②,否则转③。
② 验证父节点是否为名词或代词,如果是,那么确定射体,否则返回空值。
③ 将方位词作为当前词,判断当前词的父节点的依存关系是否为HED,如果不是,将当前词的父节点覆盖当前词,再作判断,直到满足当前词的父节点的依存关系是HED的情况。
④ 遍历句法树,抽取父节点与当前词的父节点相同的词,并验证其词性是否为名词或者代词,如果是,那么确定射体,否则,返回空值。
2.3.2复杂射体识别
当一个短句中存在多个并列的射体时,如例子“小明和奥巴马在屋子后面的桥上钓鱼。”通过2.3.1的方法我们只能识别出两个三元组(小明,桥,上),(桥,屋子,后面),对于跟“小明”并列的射体“奥巴马”并没有识别出来,所以就要在简单射体识别之后对并列的射体做处理,复制相应的界标和方位词,增添到结果三元组的列表中去。

在上图中我们可以通过遍历句法树来抽取父节点为已确定射体,依存关系为COO的节点来作为新增三元组的射体,在复制父节点射体的三元组中的界标和方位词,增添到结果三元组列表中去。
复杂射体识别算法如下:
-
① 简单射体识别。
② 遍历句法树,抽取父节点是当前处理三元组中的射体的节点,验证其依存关系是否为“COO”。
③ 复制当前处理三元组的界标和方位词到新的三元组,将该节点作为新的三元组中射体,并将新的三元组添加到结果三元组列表中。
④ 返回结果三元组
注:
1.语料预处理部分使用的是语言云API,链接为:http://www.ltp-cloud.com/document/
2.源码下载地址:https://github.com/CODERXIAOYE/Spatial-relation-extraction-based-on-the-dependency.git

















 2053
2053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









