







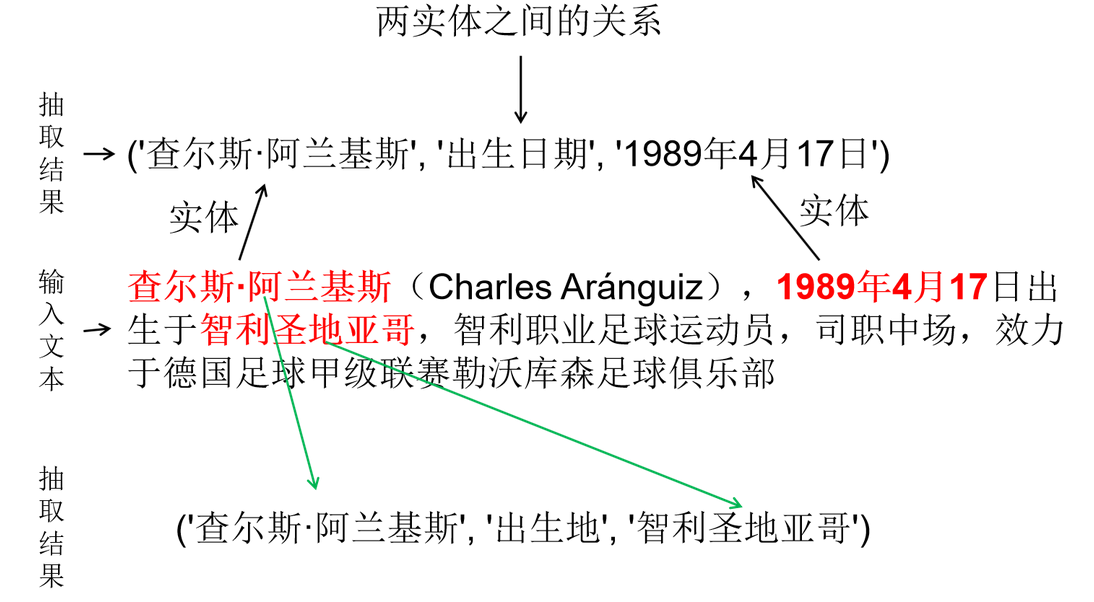
关系抽取介绍
关系抽取概念字1988年在MUL大会上提出,是信息抽取的基本任务之一,目的是为了识别出文本实体中的目标关系。
知识图是语义关联的实体,它将人们对物理世界的认知转化为计算机能够义结构化方式理解的语义信息。
关系抽取通过识别实体之间的关系来提取实体之间的语义关系。在现实世界中,关系提取要比实体提取复杂的多,自然句子的形式也多种多样,
所以关系的提取比实体提取困难的多。
关系抽取主要分为两个任务
-
关系分类
- 基于预先给定的关系,对实体进行分类匹配。
-
开发关系抽取
- 直接从文本中抽取结构化文本关系
- 对文本关系映射到知识库的规范关系
关系抽取发展也主要分为三个阶段,基于规则、基于机器学习和基于深度学习,其中机器学习又包括监督学习、无监督学习、半监督学习。
深度学习主要是监督学习和远程监督学习。下面分别介绍,三种框架的经典算法。
基于规则的关系抽取算法
通过手写规则来匹配文本,实现关系抽取,主要分为两种:
基于触发词(基于模式)
假设X和Y表示公司类型,可使用如下模板表示收购(ACQUISITION)关系。当满足下述模板,则表示两个实体指称在这个句子中具有收购(ACQUISITION)关系。
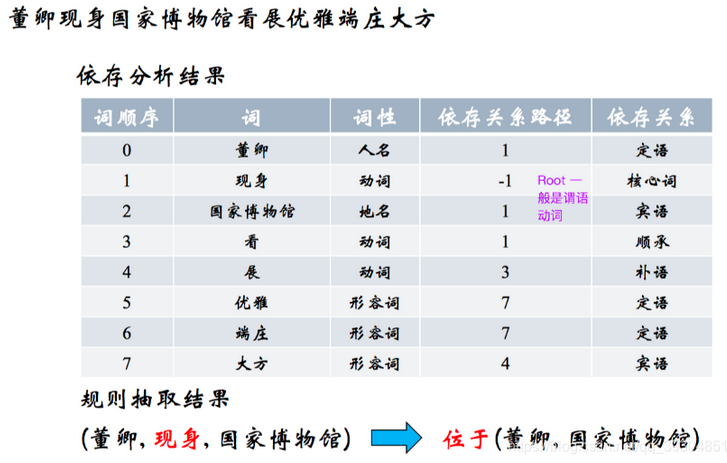
基于依存关系(语法树)
以动词为起点构建规则,对节点上的词性和边的依存关系进行限定。

基于规则的关系抽取缺点
-
优点
- 人工规则有高准确度
- 可以针对特定的垂直领域
- 在小规模数据集上哈桑容易实现。
-
缺点
- 低召回率
- 特定领域需要专家构建,费时费力。
- 难以维护
- 每天关系需要人工构建
- 鲁棒性差
基于机器学习的RE方法
根据数据是否标注:可以分为监督学习、半监督学习、和无监督学习。
监督学习
监督学习从训练数据中研究模型,并预测测试数据关系类型,输入时的自然语句,输出为预定义的关系集。
由于关系抽取任务中向量都是来自非结构化数据,所以需要对文本的不同层次语言进行形式化,对于文本的处理主要有两类:
特征向量法和核函数法。
基于特征向量法
主要从上下文信息、词性、句法中提取一系列特征向量,然后通过分类算法,如:
- Naive Bayes
- SVM
- ME最大熵模型
所谓特征向量也就是一个实例的向量表示 x x x, x i x^i xi就是n维特征向量的第i个元素.
基于核函数
通过核函数计算两个实体之间的相似性,来训练分类模型,核心在于如何设计核函数。

监督学习方法的准确率和标注数据的质量、数量成正比,且不能拓展新的关系,受限于训练语料库,也不适合在开放领域进行关系抽取,因此学术界开始转向半监督和无监督的学习方法。
半监督学习——Boostrap和Snowball
半监督学习又称为弱监督学习,利用模型的假设,对少量的数据进行标注,在不足的条件下,提高模型在标记样本中的泛化能力。未标记的数据为Corpus text
在论述Snowball之前,先看Boost strap,他是介于监督学习和半监督学习的算法。
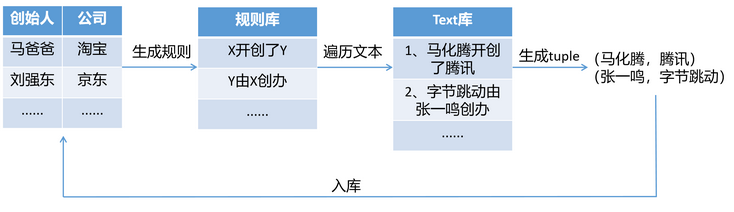
Boost strap
根据已指导标记数据的seed库,生成规则,在利用该规则在text中进行遍历,生成新的规则,新规则入库中,作为标记的数据进行重新遍历,
缺陷就是如果生成的规则不准确,这个错误的规则会在库中不断增大,导致正确率逐渐降低。
Snowball
snowball在2000年被提出,提供了一种从文本文档生成模式和提取元组的新技术,此外,snowball还介绍了一种策略,用于评估在提取过程的每次迭代中生成的模式和元组的质量,只有那些被认为“足够可靠”的元组和模式才会被雪球保留,用于系统的后续迭代。
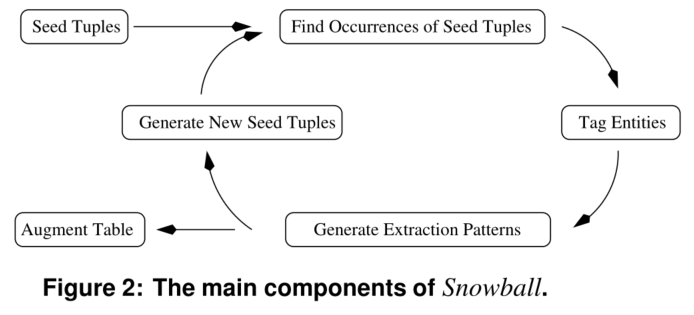
算法主要四个步骤:
Step1:生成模式
定义规则:五元组构成(L,实体1,M,实体2,R) 其中
L
M
R
LMR
LMR是向量。
给定文本按照L + 实体1 + M + 实体2 + R的模板生成规则。

Step2:生成tuple

然后,每个候选tuple都有许多帮助生成它的模式,每个模式都有相应的匹配程度。snowball使用这些信息以及关于模式选择性的信息来决定将哪些候选元组实际添加到它正在构建的表中。
Step3:评估模式和tuple
通过计算模式的置信度来决定该模式是否被选择,反之错误的模式产生更多错误的元组。同样的,错误的元组也可能生成无关的模式,通过不断迭代产生更多错误的tuple,(as the name(Snowball) implies).如果一个元组是由多个高得分的模式所产生的,它的置信度就会高。

无监督学习——聚类
监督学习和半监督学习都需要提前确定关系的类型,事实上,在大规模语料库中,人们往往无法预测所有类型的实体关系,
一些研究者试图基于聚类的思想来解决这一问题。
无监督关系提取是由Hasegawa等人在2004年的ACL会议上首次提出的,随后的大多数方法都是在Hasegawa的基础上改进的。结果表明,聚类方法在关系提取中是非常可行的。
首先,他们通过爬虫获取新闻文本,然后根据文章的来源开始分类。然后,根据句子的语义结构,提取出满足一系列约束条件的基本模式聚类实体,将这些实体按照基本模型进行映射,形成次级聚类,使每个次级聚类包含的实体之间的关系相同。
无监督方法通常需要大规模语料库作为支持,利用语料库的冗余度**,挖掘可能的关系模式集,确定关系名称**,该方法的不足之处在于关联名称难以准确描述**,低频关联的召回率低**
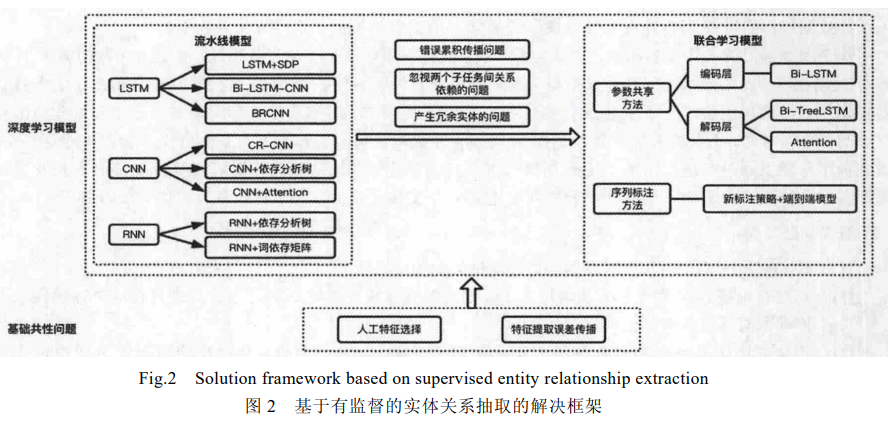
基于深度学习的RE方法
基于深度学习的关系抽取方法,主要是有监督学习和远程监督学习,其中有监督学习主要有pipeline和Joint。
- 流水线:NER串联RE,在实体识别完成的基础上直接进行实体之间关系的抽取
- 联合学习:基于神经网络端到端模型,同时完成实体的识别和实体间关系的抽取
- 远程监督方法:缺少人工标注数据集,比有监督多一步远程对齐知识库给无标签数据打标的过程。而构建关系抽取模型模型的部分,与有监督领域的流水线方法差别不大。
基于DL的RE任务框架如下:
1、获取有标签数据:有监督方法通过人工标记获取有标签数据集,远程监督方法通过自动对齐远程知识库获取有标签数据集;
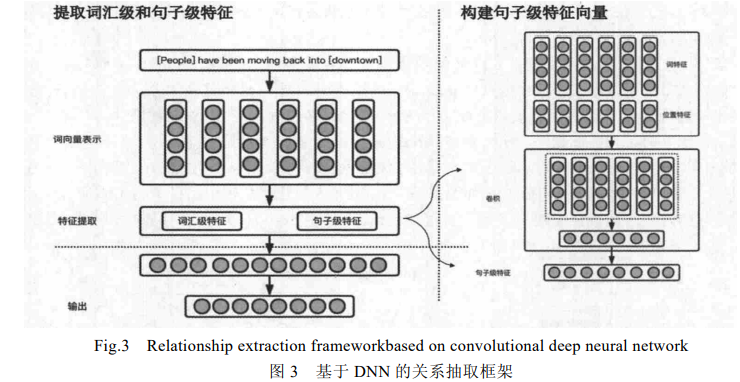
2、构建词向量表示:将有标签句子分词,将每个词语编码成计算机可以接受的词向量,并求出每个词语与句子中实体对的相对位置,作为这个词语的位置向量,将词向量与位置向量组合作为这个词语的最终向量表示;
3、 进行特征提取:将句子中每一个词语的向量表示输入神经网络中,利用神经网络模型提取句子特征,进而训练一个特征提取器;
4、关系分类:测试时根据预先定义好的关系种类,将特征提取出的向量放入非线性层进行分类,提取最终的实体对关系;
5、评估分类性能:最后,对关系分类结果进行评估;
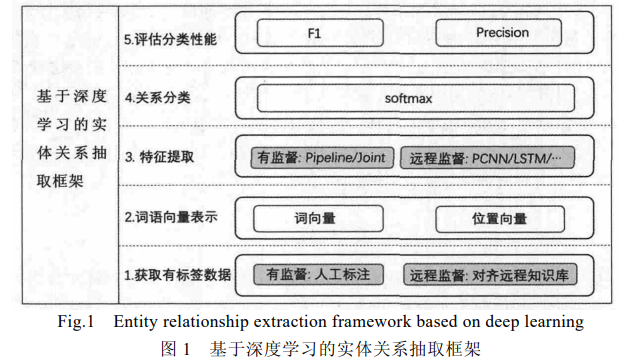
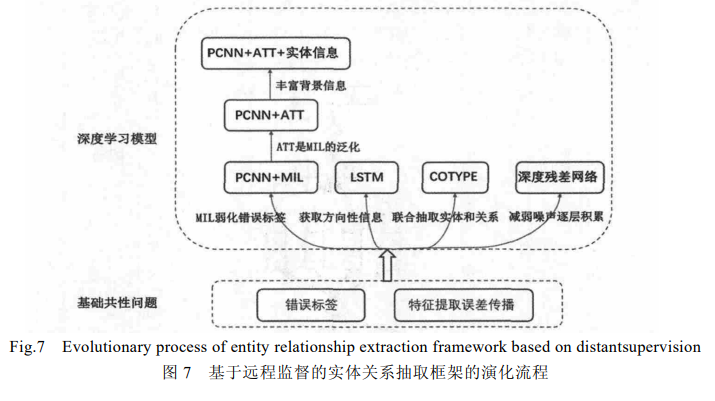
监督实体关系抽取框架演化流程:
监督学习——流水线(Pipeline)
As the name implies,流水线就是将NER和RE两个任务串联起来进行,在NER的基础上进行RE。首先,针对已经标注好目标实体对的句子进行关系抽取,最后**把存在实体关系的三元组作为预测结果输出。**主要是基于 RNN,CNN,LSTM 及其改进模型的网络结构。
基于RNN关系抽取
RNN 在处理单元之间既有内部的反馈连接又有前馈连接,可以利用其内部的记忆来处理任意时序的序列信息,具有学习任意长度的各种短语和句子的组合向量表示的能力,已成功应用在多种 NLP 任务中。
基于CNN的关系抽取
CNN 的基本结构包括两层:其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等,减少了网络中自由参数的个数.由于同一特征映射面上的神经元权值相同,所以** CNN 网络可以并行学习**.
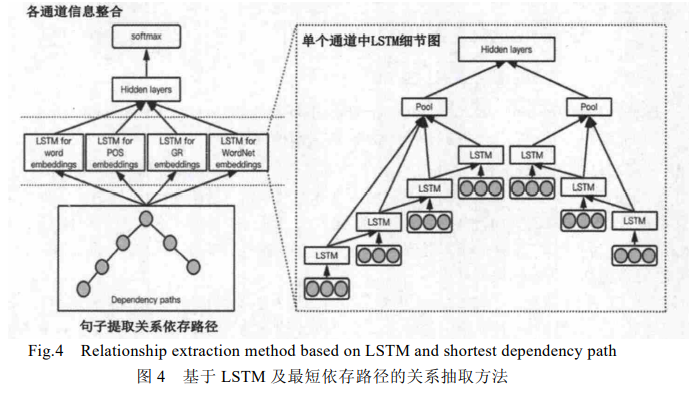
基于LSTM关系抽取
由于梯度消失、梯度爆炸的问题,传统的 RNN 在实际中很难处理长期依赖,后面时间的节点对于前面时间的节点感知力下降.而 LSTM 网络通过 3 个门控操作及细胞状态解决了这些问题,能够从语料中学习到长期依赖关系.****
流水线方法存在的问题
- 错误传播:实体识别模块的错误会影响到接下来的关系分类性能。
- 忽视了两个子任务之间存在的关系:丢失信息,影响抽取效果;
- 产生冗余信息,由于对识别出来的实体进行两两配对,然后在进行关系分类,那些没有关系的实体对就会带来多余信息,提升错误率。
监督学习——联合抽取(Joint)(End2End)
相比于流水线方法,联合学习方法能够利用实体和关系间紧密的交互信息,同时抽取实体并分类实体对的关系,很好地解决了流水线方法所存在的问题。
联合学习方法通过实体识别和关系分类联合模型,直接得到存在关系的实体三元组.因在联合学习方法中建模的对象不同,联合学习方法又可以分为参数共享方法和序列标注方法:参数共享方法分别对实体和关系进行建模,而序列标注方法则是直接对实体-关系三元组进行建模.下面分别对这两种方法进行说明。
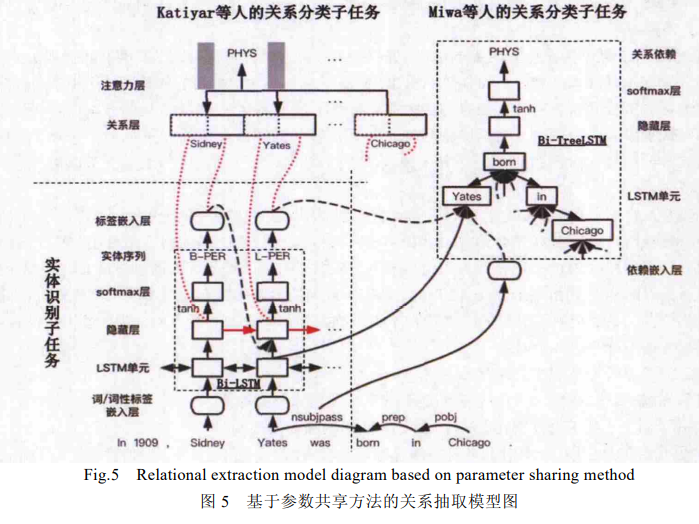
针对流水线方法中存在的错误累积传播问题和忽视两个子任务间关系依赖的问题,基于参数共享的实体关系抽取方法被提出.在此方法中,实体识别子任务和关系抽取子任务通过共享联合模型的编码层来进行联合学习,通过共享编码层,在训练时,两个子任务都会通过后向传播算法更新编码层的共享参数,以此来实现两个子任务之间的相互依赖,最终找到全局任务的最佳参数,实现性能更佳的实体关系抽取系统.在联合学习模型中,输入的句子在通过共享的编码层后**,在解码层会首先进行实体识别子任务,再利用实体识别的结果**,并对存在关系的实体对进行关系分类,最终输出实体-关系三元组.
参数共享
针对流水线方法中存在的错误累积传播问题和忽视两个子任务间关系依赖的问题,基于参数共享的实体关系抽取方法被提出.在此方法中,实体识别子任务和关系抽取子任务通过共享联合模型的编码层来进行联合学习,通过共享编码层,在训练时,两个子任务都会通过后向传播算法更新编码层的共享参数,以此来实现两个子任务之间的相互依赖**,最终找到全局任务的最佳参数,实现性能更佳的实体关系抽取系统**。
序列标注
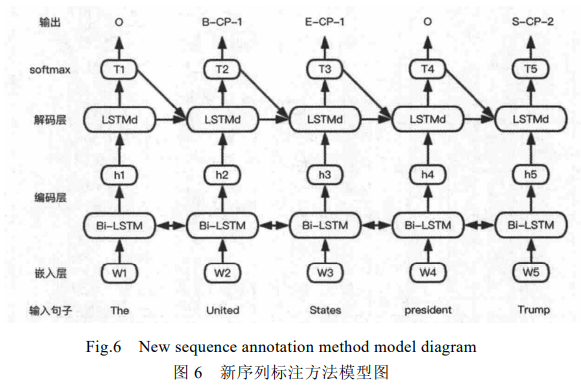
基于参数共享的实体关系抽取方法,改善了传统流水线方法中存在的错误累积传播问题和忽视两个子任务间关系依赖的问题.但因其在训练时还是需要先进行命名实体识别子任务,再根据实体预测信息对实体进行两两匹配,最后进行关系分类子任务,因其在模型实现过程中分开完成了命名实体识别和关系分类这两个子任务**,仍然会产生没有关系的实体这种冗余信息.**为了解决这个问题,基于新序列标注方法的实体、关系联合抽取方法被提出.
该方法能使用序列标注的方法同时识别出实体和关系,避免了复杂的特征工程,通过一个端到端的神经网络模型直接得到实体-关系三元组,解决了基于参数共享的实体关系抽取方法可能会带来的实体冗余的问题.新序列标注方法的模型图如图 6所示.在该端到端的神经网络模型中,对输入的句子,首先,编码层使用 Bi-LSTM来进行编码;之后,解码层再使用 LSTM 进行解码;最终,输出模型标注好的实体-关系三元组。
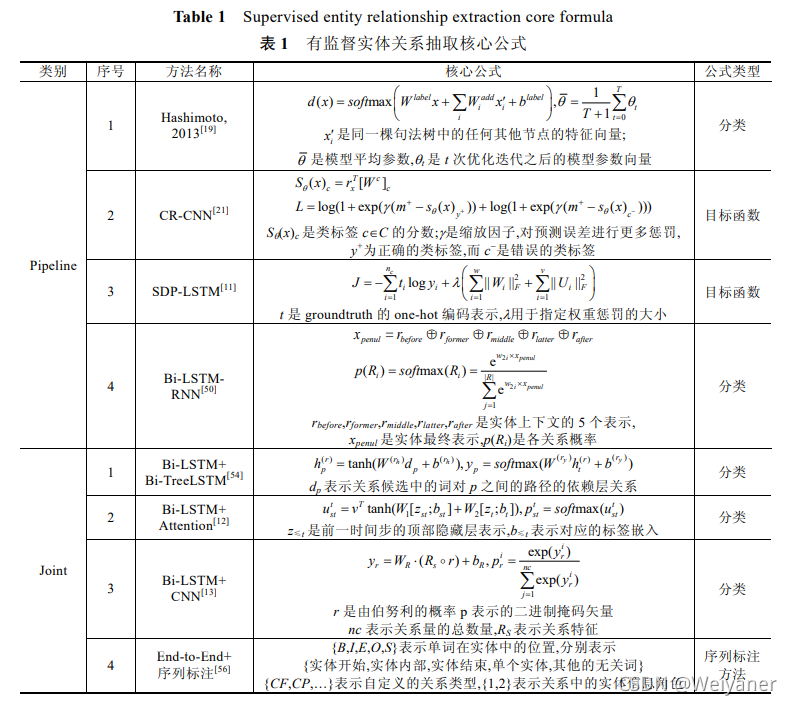
监督学习关系抽取的核心公式:
基于远程监督的关系抽取RE
Mintz于 2009 年首次提出将远程监督应用到关系抽取任务中,其通过数据自动对齐远程知识库来解决开放域中大量无标签数据自动标注的问题。远程监督标注数据时主要有两个问题:噪声和特征提取误差传播.
基于 PCNN 及其扩展模型的实体关系抽取
基于 LSTM 的实体关系抽取方法
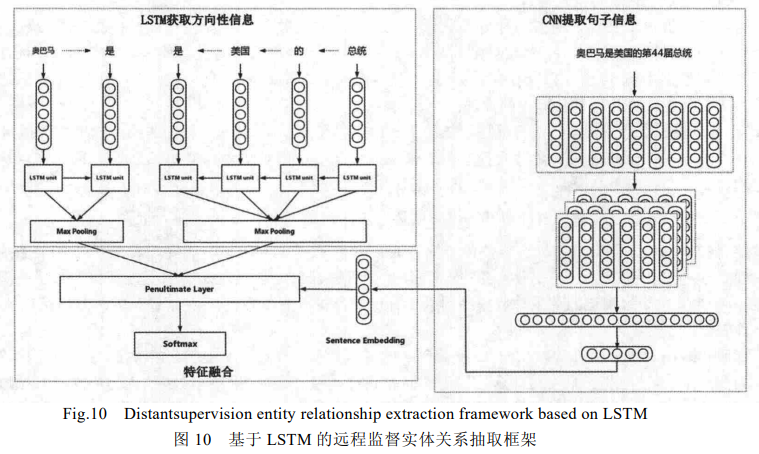
a) LSTM 网络抽取实体对方向性信息(图 10 左上部分):HE 等人首先将句子的最短依存路径(SDP)分割成两个子路径作为 LSTM 结构的输入,自动地抽取特征,以此来抽取实体对的方向性信息;
b) CNN 网络提取句子整体信息(图 10 右部分):尽管 SDP 对关系抽取非常有效,但是这并不能捕捉到句子的全部特征.针对此问题,作者将全部句子放进 CNN 网络,进而抽取句子的全部信息(sentence embedding);
c) 特征融合(图 10 左下部分):最后,将 LSTM 隐藏层单元以及 CNN 的非线性单元相融合,通过 Softmax层来标注实体对对应的关系。
基于 COTYPE 联合抽取模型的实体关系抽取方法
基于深度残差网络的实体关系抽取方法
经验
根据以上的方法,将关系抽取慢慢的都搞定。慢慢的研究自己的方法,会生成自己的论文知识,如果平台可以利用的化,争取下半年开始写作 。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











