







让Googel找到他们
由于单页应用的所有HTML都由JavaScript生成,所以需要使用不同的方法。而爬虫不会执行JS
提供详细的日志信息:网站流量、用户行为和错误信息。而单页应用把用户交互逻辑移到了客户端,所以需要使用另外的方法。
提升响应时间的一种方法是使用CDN来提供静态文件和数据的服务。另外一种方法是使用HTTP缓存和服务器缓存。
9.1 单页应用针对搜索引擎的优化
Google等搜索引擎为单页应用创建了一套机制,不但索引动态页面,还特别针对爬虫,对页面进行了优化。
Google是如何爬取单页应用的:当Googlebot尝试为单页应用建立索引的时候,它在HTML中所看到的只有一个空容器,所以没什么东西好索引的,没链接可爬取,然后它就会为该网站建立索引。
然而搜索引擎已经认可了单页应用的重要性,并提供了工具,允许开发人员向爬虫提供搜索信息,这比爬取传统网站的效果还要好。
要让单页应用可爬取,首先服务器要能区分请求是有爬虫发起的还是用户使用浏览器发起的,并相应地进行响应。当访问者是使用浏览器的用户时,则正常地响应,但对于爬虫,则返回优化后的页面,显示给爬虫的正是我们希望的易于爬虫读取的格式。
9.2 云和第三方服务
三种重要的服务,即站点分析、客户端日志和CDN,对于开发单页应用尤其重要。
站点分析:对于传统网站,开发人员已经逐渐地依赖像Google Analytics和New Relic这样的工具,它们可以提供关于用户如何使用网站的详细分析,会找出应用程序或者业务性能(网站促成销售的效率如何)的所有瓶颈。对单页应用使用相同的工具完全有效,只是方法稍微优点不同。
Google Analytic提供了很简单的方法来获取统计数据,单页应用的流行程度以及单页应用各种各样的状态,还有网站的流量是从何而来的。可以在传统网站中使用Google Analytics,在每张HTML页面中粘一段JavaScript代码,做些小修改,对页面进行分类。单页应用也可以使用这种方法,不过这样就只能得到初始加载页面的统计数据。为了能够在单页应用中全面利用Google Analytics,有两种方法可以使用。
(1)使用Google Event跟踪哈希值的变化:Google早就意识到需要记录页面和对页面进行分类的事件。在传统网站中,JavaScript代码片段会调用_gaq对象的_trackPageView方法。可以传递自定义变量,设置代码片段所在页面的信息。该调用通过请求一张图片并在请求url的后面传递参数,会把信息发送给Google。服务器会使用这些参数,处理页面浏览的信息。使用Google Event的时候会调用_gap对象的另外一个方法:它会调用_trackEvent方法并带上一些参数。然后_trackEvent加载一张图片,在图片url的最后会带上一些参数,Google会使用这些参数来处理这个事件的信息。
创建和使用事件跟踪的步骤很简单:
- 到Google Analytics网站上为自己的网站创建事件跟踪。
- 调用_trackEvent方法
- 查看报告
(2)使用Node.js在服务端进行记录。 由于JavaScript可以在服务器上使用,似乎可以修改Google Analytics的代码,用在服务器上。node-googleanlytics和nodealytics项目。
记录客户端错误:
第三方客户端记录服务,如Errorception。
手动记录客户端错误:
使用window.onerror事件处理程序来捕获错误
把代码放在try/catch语块中,把捕获到的错误信息发送给后端。
内容分发网络:用来尽可能快地传输静态文件的网络。Node.js特别不适合用来传输大的静态内容文件,因为这种用法不能利用Node.js的异步本质。使用包含prefork模块的Apache更适合。
使用分布全球的CDN的另外一个好处是,内容由离我们最近的服务器提供,从而使得传输文件花费的时间大大缩短。
9.3 缓存和缓存破坏
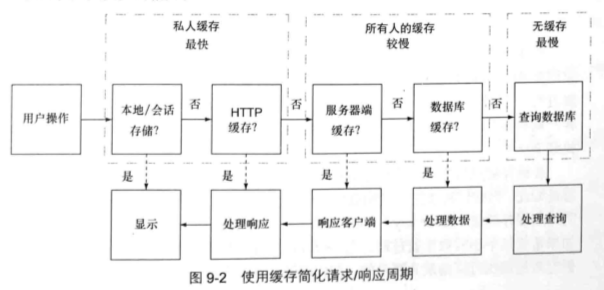
在进行缓存的时候,考虑数据的新鲜度是至关重要的。我们不希望把过期的数据提供给应用的用户,但同时又希望尽可能快地对请求进行响应。
缓存时机:
- Web存储把字符串保存在客户端,应用程序可以访问,可以使用它来保存处理好的HTML,HTML是根据服务器上的数据生成的。
- HTTP缓存是客户端缓存,它把服务器的响应保存在客户端。为了能正确地控制这种缓存,有很多细节要学习,但在学习完并实现了之后,我们能得到很多免费的缓存。
- Memcached和Redis的服务器缓存,经常用于缓存处理过的服务器响应。这是缓存的重要形式,可以为不同的用户保存数据,这样如果一个用户请求了一些信息,下一次其他人请求相同的信息时,它已经被缓存了,节省了一次查找数据库的时间。
- 数据库缓存,或者叫查询缓存,是数据库用来缓存查询结果的,如果它被打开了,后续相同的查询就会返回缓存的数据,而不是重新去收集数据。
lib/cache.js















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









