







Style transfer系列论文之——Arbitrary Style Transfer in Real-time with Adaptive Instance Normali,ICCV, 2017
文章亮点
1.Gatys等人链接 提出的style transfer框架在生成新图片时需要迭代优化,过于耗时。尽管已经有人尝试通过乾前馈网络来快速近似来加速style transfer, 然而又带来另一个问题:网络通常与一组固定的style绑定,并不能适应任意新的style. 而这篇文章提出一个简单有效的方法可以进行实时任意style的迁移。
2.所提方法的核心是: 提出了一种新的自适应实例归一化层(Adaptive Instance normalization layer)-—用style feature的统计信息(mean和standard deviation)来对齐content feature的统计信息。
3. 所提方法效率高, 没有预定义style的限制,并且允许灵活的用户控制,例如内容样式权衡、样式插值、颜色和空间控制等。
Adaptive Instance Normalization
背后的动机与思考
Batch Normalization (BN)和Instance Normalization (IN)的介绍可以参考 链接
核心观点
1.IN实际上通过归一化feature的统计量(mean, standard deviation)执行了某种形式的style normalization。
为了验证该观点,作者设计了三个实验: (a)基于原始images分别训练 IN model和BN model, (b) 基于对比度归一化后的images分别训练IN model和BN model; ©基于style normalized之后的images分别训练IN model和BN model.
实验结果如下图:(a)和(b)的对比表明 IN优于BN并不是由于对比度归一化引起的,这也否决了另一篇文章[1]的观点(IN由于BN是因为IN对content image对比度具有不变性);(b)和©的结果表明:对image做了style normalization之后, IN与BN效果相当,这表明IN优于BN正是由于IN执行了某种style normalization。
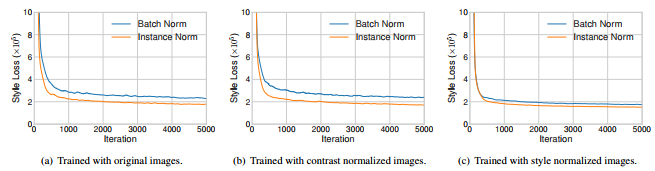
2.IN将每个Sample归一化到单个style, 而BN将一个batch的样本归一化到以某个style为中心
3.CIN成功的背后原因:不同的仿射变换参数可以将feature统计量归一化为不同的值(而不同的值实际上对应不同的style), 从而将输出image归一化为不同的style。
Adaptive Instance Normalization layer
CIN虽然很好,但它的缺点也很明显:不能适应任意新的style, 因为model绑定到了预定义的style set上,想适应新的style只能重新训练了。
基于上面的分析,作者提出了Adaptive Instance Normalization, 非常简单, simple yet effective, 如下:
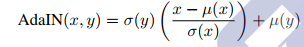
即 先对x进行Instance normalization, 然后将其对齐到目标style的统计量:
μ
,
σ
\mu, \sigma
μ,σ,其中x和y分别是content image和style image的特征表示(即pretrained model的相应输出),
{
μ
(
x
)
,
σ
(
x
)
}
\{\mu(x), \sigma(x)\}
{μ(x),σ(x)},
{
μ
(
y
)
,
σ
(
y
)
}
\{\mu(y),\sigma(y)\}
{μ(y),σ(y)}分别为x和y在执行instance normalizaion时的相关统计量。
模型整体结构
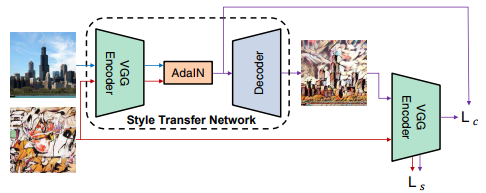
如上图所示,该模型整体上采用了Encoder-Encoder结构,具体讲:
(1)Encoder: 用于将content image/style image从image空间映射到feature空间,Encoder完全是作为一个feature exptractor并且不参与训练(fixed),作者采用了VGG19 pretrained模型的前几层作为Encoder。
(2)Decoder: 与Encoder正好相反,用于将Adaptive Instance Normalized之后的输出(feature空间)再映射回image空间,Decoder的结构与Encoder类似,只不过它是需要训练的(trainable)。
形式化定义如下:
首先content image © 与style image (s)经过Encoder (f)分别得到其特征表示:
f
(
c
)
,
f
(
s
)
f(c), f(s)
f(c),f(s), 然后通过 Adaptive Instance Normalization 执行style transfer, 输出记为
t
t
t.
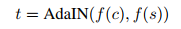
然后t通过Decoder (g)得到生成的图像
T
(
c
,
s
)
T(c,s)
T(c,s) :
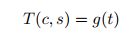
损失函数
与style transfer work 链接类似,总的损失包括:content loss和style loss, 如下:
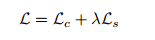
具体细节上有差异:
(1) Content loss
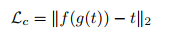
注意这里, 目标content representation没有使用 $f(c)$而是使用了$f(c)$和$f(s)$经过Adaptive Instance Normalization之后的输出$t$, 作者给出的解释是: 实验表明这样效果更好,收敛更快,实际上f(g(t))恰好不是t的reflection吗?
(2) Style loss
同样的,Style loss也没有使用传统的基于不同feature channel的Gram矩阵来计算style distance, 而是针对该方法的特点: 该方法是通过Adaptive Instance Normalization来进行style transfer的,而 Adaptive Instance Normalization实际上就是在transfer feature的统计量(mean和standard deviation), 因此利用feature的统计量就可以度量style distance, 定义如下:
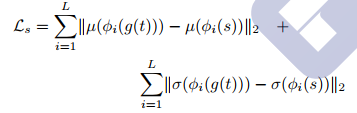
其中
ϕ
i
(
x
)
\phi_{i}(x)
ϕi(x)表示x feed进Encoder后第i层的输出响应。
注:作者也使用Gram矩阵进行实验,效果类似,为了方法的完整性、一致性,采用了上述方式。
资源
1.官方开源代码,[https: //github.com/xunhuang1995/AdaIN-style](https: //github.com/xunhuang1995/AdaIN-style)
Reference
1.Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis
2.Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization, ICCV,2017
3.A learned represen- tation for artistic style, ICLR, 2017
















 4358
4358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











