






前言
在对苹果品质进行分级时经常应用到的技术是机器视觉技术,此技术在当前的应用中已经逐渐成为最关键的检测方法之一。机器视觉技术由于受到图像处理技术的支持在苹果品质品质检测方面更加科学与专业,由此在以后的技术应用与发展中越来越有发展前途。
本次毕业论文的研究研究对象是对苹果品质品质检测的方法进行考量,应用的主要研究技术与方法是数字图像处理法与机器视觉技术。在当前的发展过程中两种方式相互结合在对苹果品质品质进行筛选时的应用越来越来越广泛,此种方法检验的标准是是否具有准确性与实时性,并且能够对苹果品质的不同品质进行精准的检测与精细化的分级。
在实际的苹果品质品质检测中重点检测两个部分分别是苹果品质的内在品质与外在品质,其中外部品质检测主要检测苹果品质的尺寸大小,苹果品质品质检测以表征苹果品质的长宽范围作为检测的关键指标。在苹果品质品质检测的过程中如何把控实时性这一原则在论文中进行了充分的探讨,采取的主要工作有试着将流水线与图像处理两种方法结合搭建出相应的实验台,进一步的将苹果品质品质的分级与检测速度提升。在对苹果品质的外形按照指数进行分级,与检测时主要应用的技术是机械视觉技术,这个过程中应用的方法有边缘检测法与颜色模型转换法。
本次的设计是将研究的问题分模块进行,分别将分级视觉系统与苹果品质品质检测中的相应功能进行了模块划分,并对每项的功能进行了简单的阐述。在文中对系统标定模块进行了详细的研究与探讨,主要围绕着重点内容是求解过程、原理与进行标定时应用的方法。为了在对苹果品质外部品质检测的过程更为精确与方便,因此将检测的精度设计与标定出来。针对论文中对苹果品质像素尺寸的检测方法的需要将现有的最小外接矩形法进行升级与改变以适应本次论文的实际需求,在对样本苹果品质的尺寸大小进行详细的标定时,可以利用已经在系统模块中标记与设定好的参数。在对实际应用过程中参数的真实尺寸与实验得到的像素尺寸进行拟合,得到的拟合效果非常好,说明两者具有十分高的相关性。对全文工作进行总结以及对未来工作进行展望。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
基于机器视觉的苹果品质分级检测,对苹果依次进行了图像采集、灰度化、二值化、图像分割等操作。再通过苹果的分级标准对苹果进行分级。保证了分级结果的准确性和实用性。主要的研究内容包括:
1.以常见水果苹果为研究对象,分析了苹果品质分级的机器视觉系统设计要求,完成了机器视觉系统硬件(光照箱、摄像机、镜头、计算机)的选择和搭建。
2.根据实验环境、设备和后期处理需求的不同,首先收集所需的数据集并对其进行标注,分析适合苹果图像预处理方法,包括空间域的图像增强、频域的图像增强、图像分割以及形态学操作等。
3.确定苹果表面损伤面积和果径并将其作为输入,利用分类模型和特定的阀值确定苹果的损伤面积以及果径从而得到苹果的级别。根据检测模型的精度需求,进行参数调整和模型优化。通过训练和测试,将采集到的图像输入计算机可以完成对苹果表面损伤和果径大小的检测和识别,能够实现对苹果品质的分级。
4.通过苹果果面损伤以及果径的真实值与设定的阈值进行比较,输出苹果所属等级从而实现苹果品质分级系统。操作者可以通过选择图像实现对苹果图像进行损伤面积、果径特征的提取,并能够从图形化的界面获得苹果损伤面积、苹果果径大小的数据。对检测后的苹果图像数据进行分类、整理、汇总统计,得到苹果的等级后集中向操作者展示。
————————————————
二、功能介绍
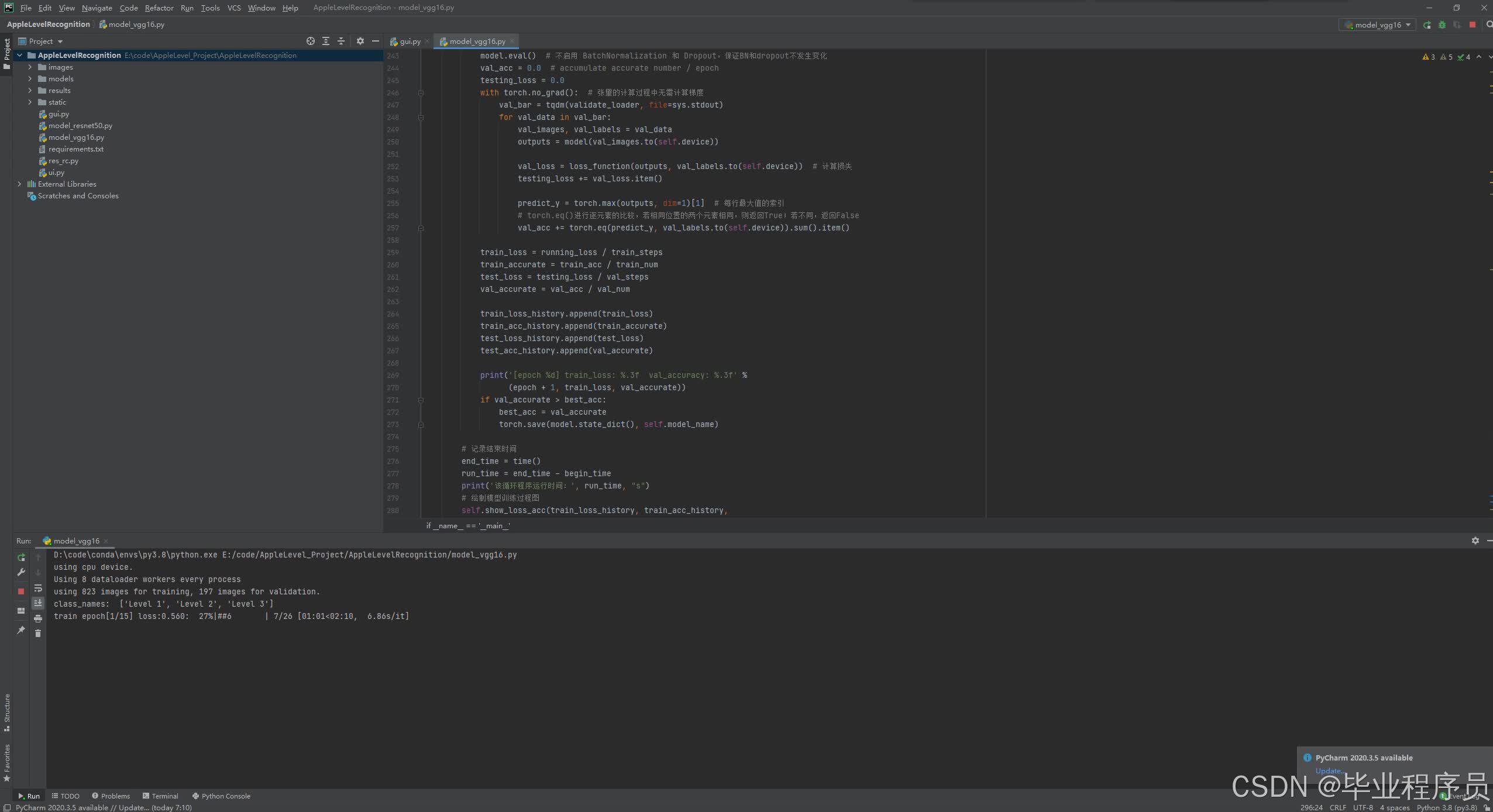
本文采用vgg16模型和自建数据集3进行苹果检测。在图像集方面,使用近千张图像进行检测,将苹果等级分为一级二级和三级,图6-1为整体结构图。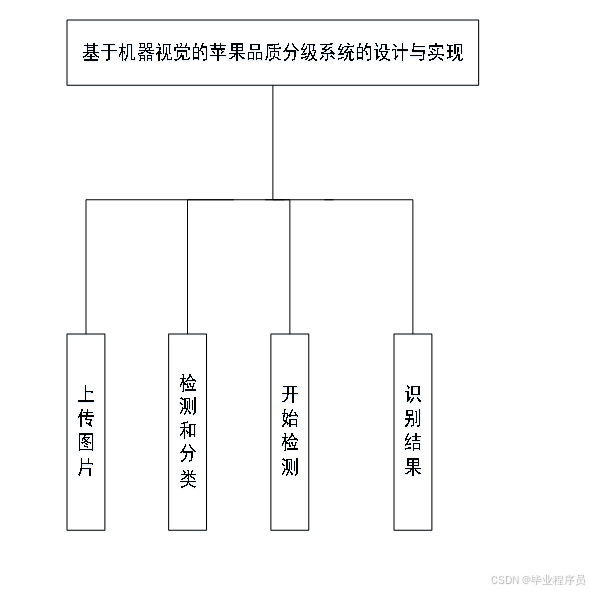
三、核心代码
部分代码:
import sys
import os
import shutil
import json
import warnings
import cv2
from PIL import Image
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.models import vgg16
from PyQt5 import QtCore
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from ui import Ui_MainWindow
warnings.filterwarnings('ignore')
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
class MyWindow(QMainWindow, Ui_MainWindow):
def __init__(self, model_path, class_name_dict):
super().__init__()
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 模型初始化
self.model = vgg16()
# 更改Vgg16模型的最后一层
self.model.classifier[-1] = nn.Linear(4096, len(class_indict), bias=True)
self.model.load_state_dict(torch.load(model_path, map_location=self.device))
# 类别
self.class_names = class_name_dict
self.setupUi(self)
self.setWindowFlag(QtCore.Qt.FramelessWindowHint)
self.setAttribute(QtCore.Qt.WA_TranslucentBackground)
self.pushButton_5.clicked.connect(self.change_img)
self.pushButton_6.clicked.connect(self.predict_img)
# 上传并显示图片
def change_img(self):
openfile_name = QFileDialog.getOpenFileName(self, 'chose files', '',
'Image files(*.jpg *.png *jpeg)') # 打开文件选择框选择文件
img_name = openfile_name[0] # 获取图片名称
if img_name == '':
pass
else:
target_image_name = "images/tmp_up." + img_name.split(".")[-1] # 将图片移动到当前目录
shutil.copy(img_name, target_image_name)
img_init = cv2.imread(target_image_name) # 打开图片
h, w, c = img_init.shape
scale = 300 / h
img_show = cv2.resize(img_init, (0, 0), fx=scale, fy=scale) # 将图片的大小统一调整到300的高,方便界面显示
cv2.imwrite("images/show.png", img_show)
img_init = cv2.resize(img_init, (224, 224)) # 将图片大小调整到224*224用于模型推理
cv2.imwrite('images/target.png', img_init)
self.label.setPixmap(QPixmap("images/show.png"))
self.label_2.setText('')
self.label_5.setText('')
# 预测图片
def predict_img(self):
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
img = Image.open(r'images/target.png')
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
self.model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(self.model(img)).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
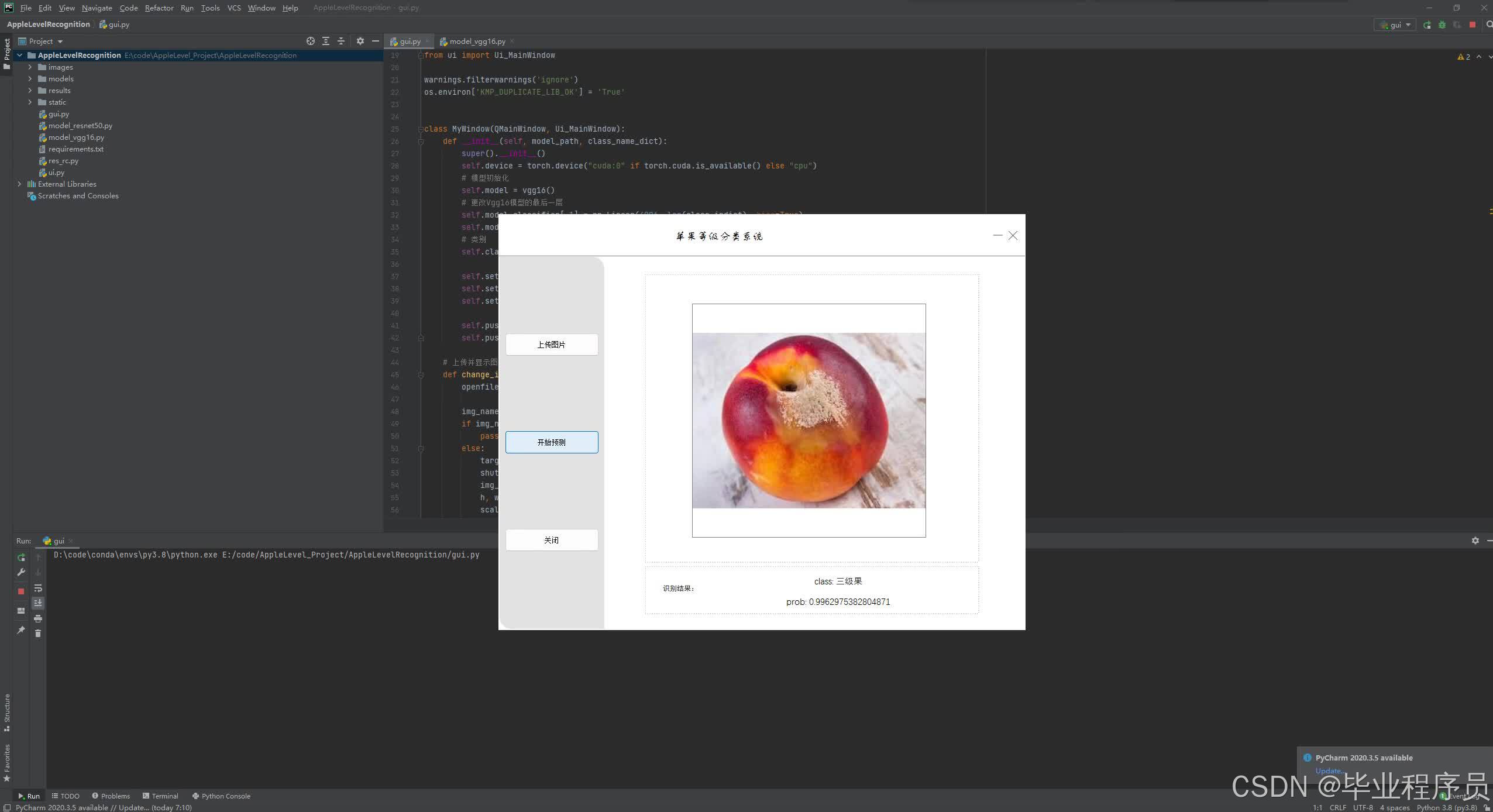
result_label = "class: {}".format(class_indict[str(predict_cla)])
result_prob = "prob: {}".format(predict[predict_cla].numpy())
self.label_2.setText(result_label) # 在界面上做显示
self.label_5.setText(result_prob) # 在界面上做显示
if __name__ == '__main__':
model_dir = "models/vgg16.pth"
json_path = 'static/json/class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
for key, value in class_indict.items():
if value == "Level 1":
class_indict[key] = '一级果'
elif value == 'Level 2':
class_indict[key] = '二级果'
elif value == 'Level 3':
class_indict[key] = '三级果'
app = QApplication(sys.argv)
my_window = MyWindow(model_dir, class_indict)
my_window.show()
sys.exit(app.exec_())
四、效果图
五、文章目录
目 录
1 绪 论 1
1.1 选题的背景 1
1.2 国内外研究现状 1
1.3 选题的目的和意义 1
1.4主要研究内容 3
2 相关技术介绍 5
2.1 卷积神经网络 5
2.2 系统开发相关技术 9
3 数据获取及预处理 14
3.1 数据集的获取及简介 14
3.2 数据预处理 17
4 模型训练与评估 18
4.1 模型选择 14
3.2 模型训练 17
4.3 模型评估 17
5 模型优化 18
5.1 优化器选择 14
5.2 效果对比分析 17
6 系统部署 19
6.1 需求分析 14
6.2 系统设计与实现 17
6.3 系统测试 17
7 总结与展望 29
7.1 总结 29
7.2 展望 29
参考文献 30
致 谢 33

















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









