






项目介绍
随着社会的逐步发展,计算机网络技术对人们工作、生活影响是全面且深入的。基于计算机网络的管理系统越来越受到人们的欢迎,人们可以通过基于网络的管理系统进行实时数据信息查询、管理数据信息等,给人们的生活、工作带来便利。
在学校的日常管理工作中,学生成绩的统计分析是必不可少的,一般都是通过电子表格Excel进行简单的统计分析,不能够灵活的对大量数据进行统计分析和数据可视化。急需研究一套能够对大量考试成绩数据进行统计分析与可视化的管理系统,该管理系统采用当前流行的B/S模式以及3层架构的设计思想,通过Python技术,利用mysql数据库,实现学生、老师及管理员对学生考试成绩数据进行分析统计与可视化管理,增强对考试成绩数据更加全面直观的实时了解。
运行环境
开发语言:Python
框架:django/FALSK
Python版本:python3.7.7
数据库:mysql 5.7;一定要5.7版本;
数据库工具:Navicat11
开发软件:PyCharm
浏览器:谷歌浏览器
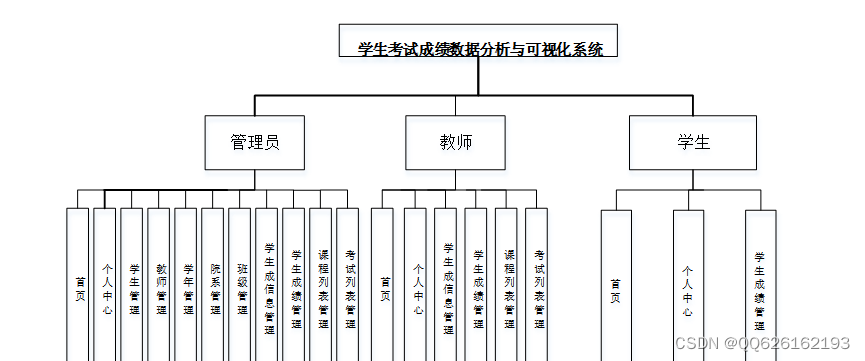
功能介绍
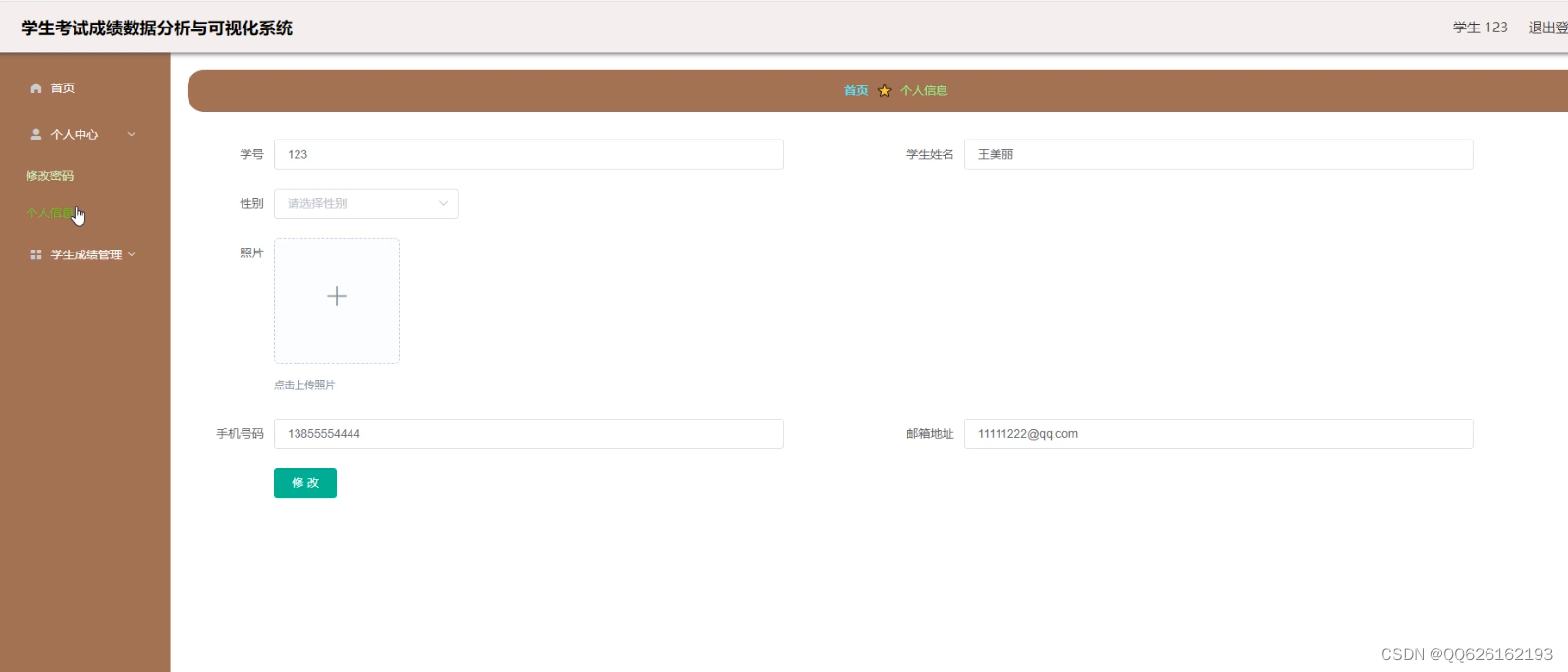
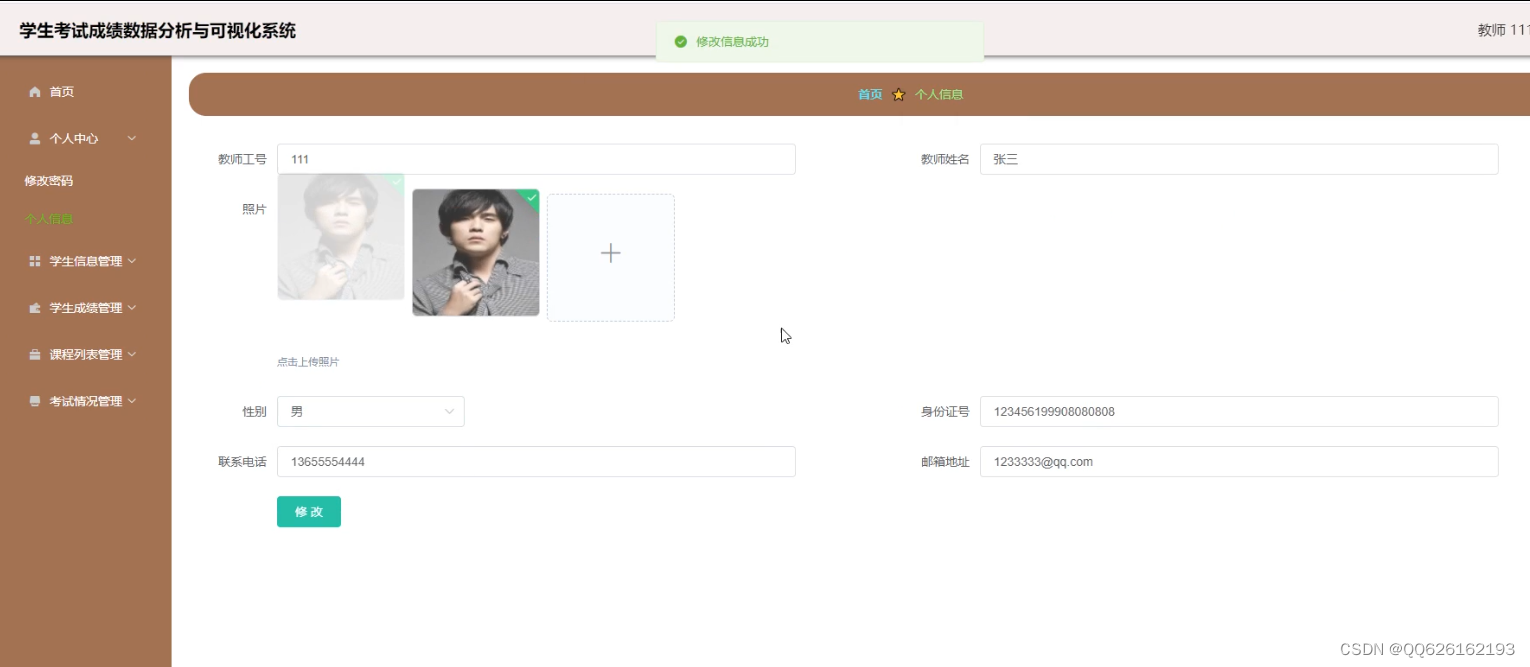
1、学生成绩系统可以操作用户的信息修改及增删改查.
2、解决目前学生考试成绩统计分析的问题,使用计算机软件与可视化技术帮助教师对成绩进行快捷的统计分析,包括考试通过率、优秀率、平均分等各项统计
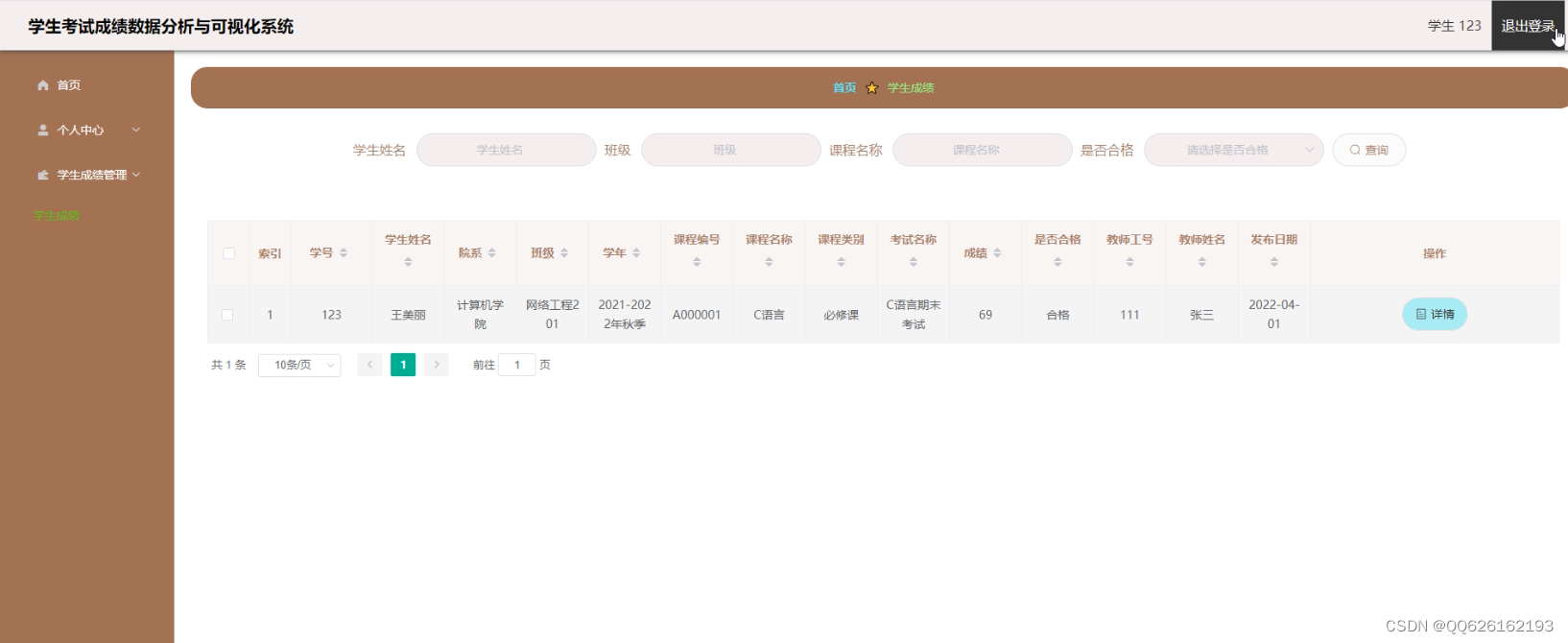
3、方便学生查询自己的考试成绩,也方便教师对学生的考试数据等进行查询。
4、通过软件系统对数据进行管理,历次考试数据都可以方便的调出,可以通过对历次考试的平均分、通过率等直观分析查看考试成绩的走向
效果图

目 录
摘 要 I
ABSTRACT II
目 录 II
第1章 绪论 1
1.1背景及意义 1
1.2 国内外研究概况 1
1.3 研究的内容 1
第2章 相关技术 3
2.1 Python简介 4
2.2 Django 框架介绍 6
2.3 B/S结构 4
2.4 MySQL数据库 4
第3章 系统分析 5
3.1 需求分析 5
3.2 系统可行性分析 5
3.2.1技术可行性:技术背景 5
3.2.2经济可行性 6
3.2.3操作可行性: 6
3.3 项目设计目标与原则 6
3.4系统流程分析 7
3.4.1操作流程 7
3.4.2添加信息流程 8
3.4.3删除信息流程 9
第4章 系统设计 11
4.1 系统体系结构 11
4.2开发流程设计系统 12
4.3 数据库设计原则 13
4.4 数据表 15
第5章 系统详细设计 19
5.1管理员功能模块 20
5.2用户功能模块 23
5.3前台功能模块 19
第6章 系统测试 25
6.1系统测试的目的 25
6.2系统测试方法 25
6.3功能测试 26
结 论 28
致 谢 29
参考文献 30















 2704
2704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









