







训练YOLOv8模型,特别是针对牙科图像分割任务,需要遵循一系列步骤以确保模型能够准确地学习和泛化。以下是详细的训练指南,包括环境设置、数据准备、模型配置、训练过程以及评估与优化。
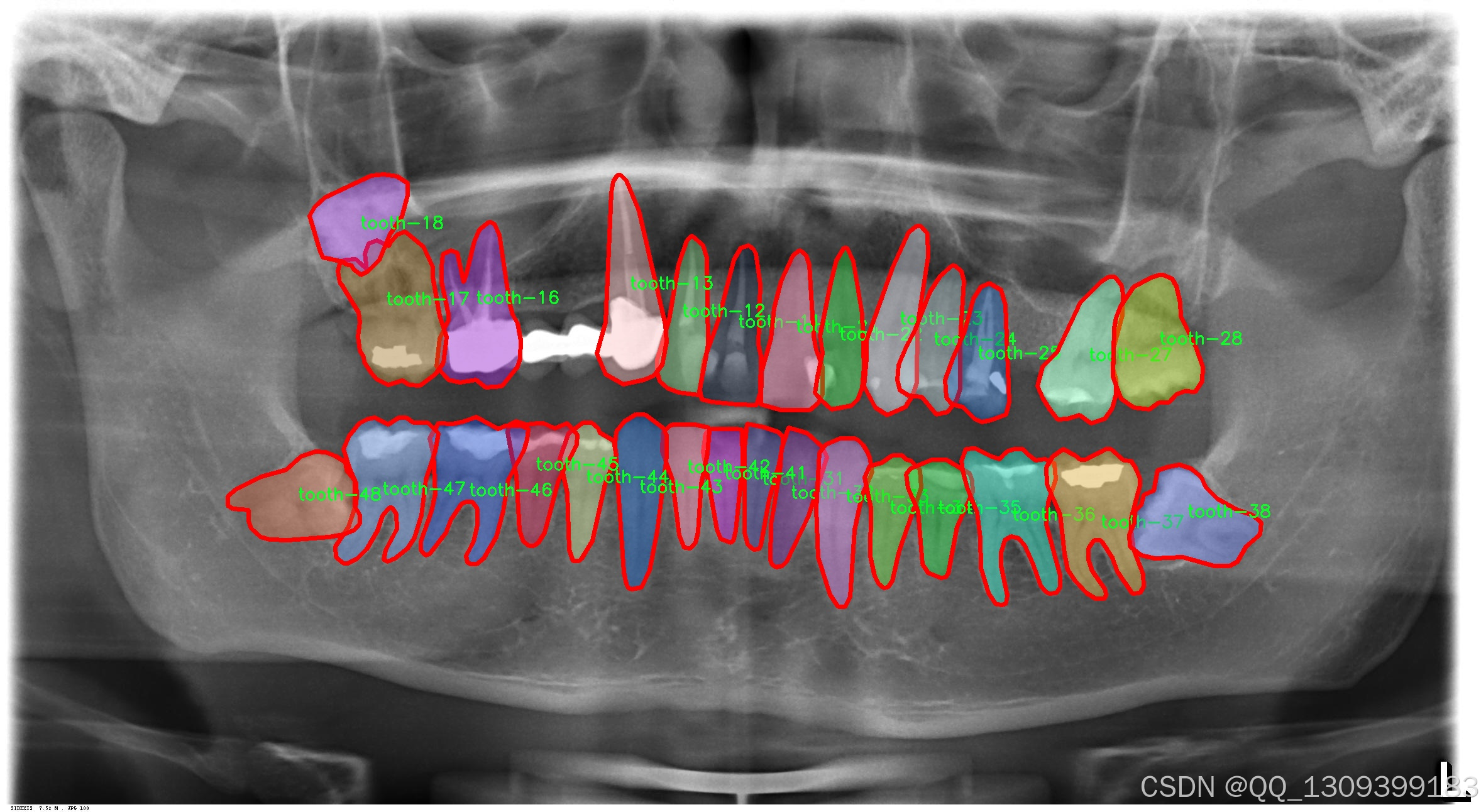
1. 环境搭建
首先,确保您的开发环境中已安装必要的依赖库和工具。对于YOLOv8,通常建议使用Python 3.8+和PyTorch作为深度学习框架。您可以参考官方文档或GitHub仓库中的安装说明来安装YOLOv8的特定版本和支持库。
# 创建并激活虚拟环境(可选)
conda create -n yolov8 python=3.8
conda activate yolov8
# 安装PyTorch和其他依赖项
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113 # 如果您使用GPU
pip install -r requirements.txt # 根据项目需求安装其他依赖项
2. 数据准备
数据集获取与预处理
- 下载Odontoai数据集:如果数据集不是公开可用的,您可能需要根据提供的教程自行收集和标注数据。
- 格式转换:确保数据集符合YOLOv8的要求,如图片和标签文件的位置和命名规则。
- 划分数据集:将数据集划分为训练集、验证集和测试集。一个常见的比例是70%用于训练,15%用于验证,15%用于测试。
数据增强
为了提高模型的泛化能力,可以对训练数据进行多种增强操作,如随机裁剪、翻转、颜色抖动等。这可以通过编写自定义的数据加载器或利用现有的图像处理库实现。
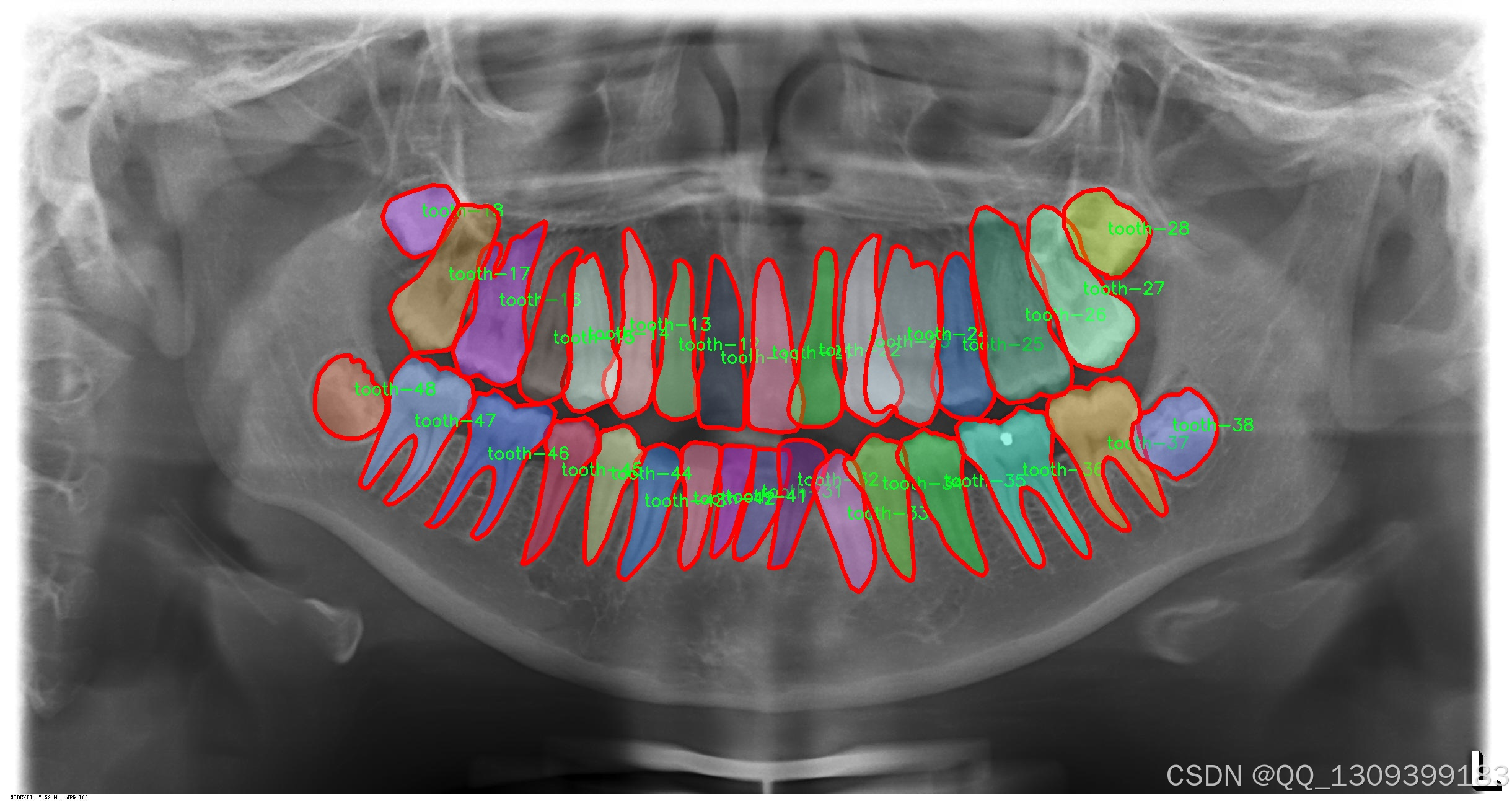
3. 模型配置
YOLOv8提供了预定义的配置文件(通常是.yaml格式),您可以根据自己的任务调整这些配置。主要修改的地方包括:
- 类别数(nc):指定牙齿类别的数量。
- 输入尺寸(imgsz):定义输入图像的大小。
- 预训练权重:如果有可用的预训练模型,可以从那里开始微调;否则,从头开始训练。
- 批量大小(batch_size):取决于您的硬件资源,较大的批量可以加快收敛但需要更多的内存。
- 学习率(lr0):初始学习率,后续会根据训练进度自动调整。
4. 训练过程
一旦所有准备工作完成,就可以启动训练过程了。训练命令通常如下所示:
python train.py --data odontoai.yaml --cfg yolov8-seg.yaml --weights yolov8x.pt --batch-size 16 --epochs 300
--data:指向包含数据路径和类别信息的yaml文件。--cfg:指定模型架构的配置文件。--weights:预训练权重的路径,若无则留空。--batch-size和--epochs:设置批量大小和训练周期数。
5. 评估与优化
在每个epoch结束时,模型会在验证集上进行评估,并保存性能最好的检查点。您可以查看训练日志中的mAP(mean Average Precision)、损失值等指标来判断模型的表现。
- 超参数调整:根据初步结果,可能需要调整学习率、批量大小或其他超参数。
- 早停法(Early Stopping):当验证集上的性能不再提升时,可以提前终止训练以防止过拟合。
- 交叉验证:通过多轮次的交叉验证确保模型稳定性和泛化能力。
6. 测试与部署
训练完成后,使用测试集进一步验证模型的最终性能。如果满意,则可以将模型部署到生产环境中,为用户提供实时预测服务。
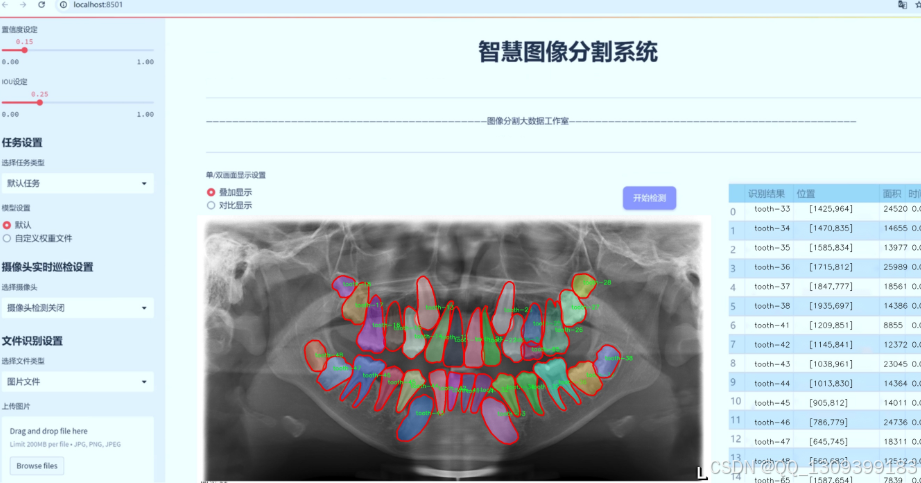
以上就是基于YOLOv8模型进行牙科图像分割任务的训练流程。希望这个指南能帮助您顺利完成模型训练,并取得理想的效果。如果您遇到任何问题或需要更具体的指导,请随时查阅相关文献或向社区寻求帮助。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









