







动物姿态识别训练指南:基于YOLOv8-pose的关键点检测模型

类别
以下是您提供内容的中文翻译:
关键点配置
kpt_shape: [39, 3]
含义:
- 39个关键点
- 每个关键点3个维度(x坐标,y坐标,可见性)
flip_idx: [0, 1, 2, 4, 3, 10, 11, 12, 13, 14, 5, 6, 7, 8, 9, 15, 16, 17, 18, 19, 20, 21, 22, 23, 27, 28, 29, 24, 25, 26, 33, 34, 35, 30, 31, 32, 36, 38, 37]
含义:
- 定义图像水平翻转时关键点的对称对应关系(例如:左眼关键点会对应到右眼)
动物类别列表
0: 羚羊
1: 灰熊
2: 虎鲸
3: 海狸
4: 斑点狗
5: 波斯猫
6: 马
7: 德国牧羊犬
8: 蓝鲸
9: 暹罗猫
10: 臭鼬
11: 鼹鼠
12: 老虎
13: 河马
14: 豹
15: 驼鹿
16: 蜘蛛猴
17: 座头鲸
18: 大象
19: 大猩猩
20: 牛
21: 狐狸
22: 绵羊
23: 海豹
24: 黑猩猩
25: 仓鼠
26: 松鼠
27: 犀牛
28: 兔子
29: 蝙蝠
30: 长颈鹿
31: 狼
32: 吉娃娃犬
33: 老鼠
34: 鼬鼠
35: 水獭
36: 水牛
37: 斑马
38: 大熊猫
39: 鹿
40: 短尾猫
41: 猪
42: 狮子
43: 老鼠
44: 北极熊
45: 柯利牧羊犬
46: 海象
47: 浣熊
48: 奶牛
49: 海豚
翻译说明:
- 动物名称:采用中文常用译名,保留学名特征(如"德国牧羊犬"而非直译"德国牧羊人")
- 专业术语:
flip_idx译为"翻转索引"(计算机视觉领域常用表述)kpt_shape保留原意,注明维度含义
- 格式一致性:保持YAML格式的层级结构,便于后续配置使用
需要调整或补充其他术语翻译请随时告知。
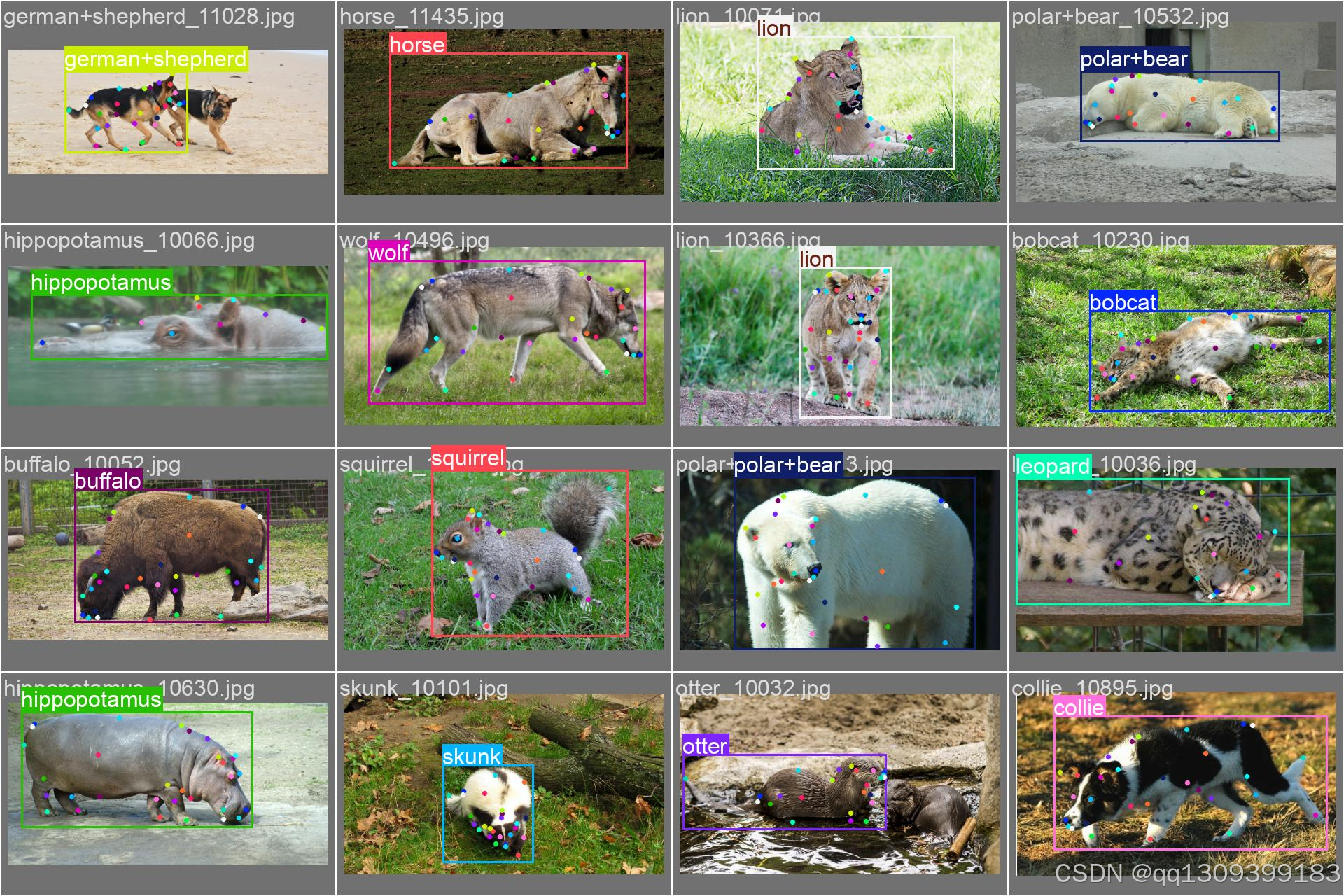
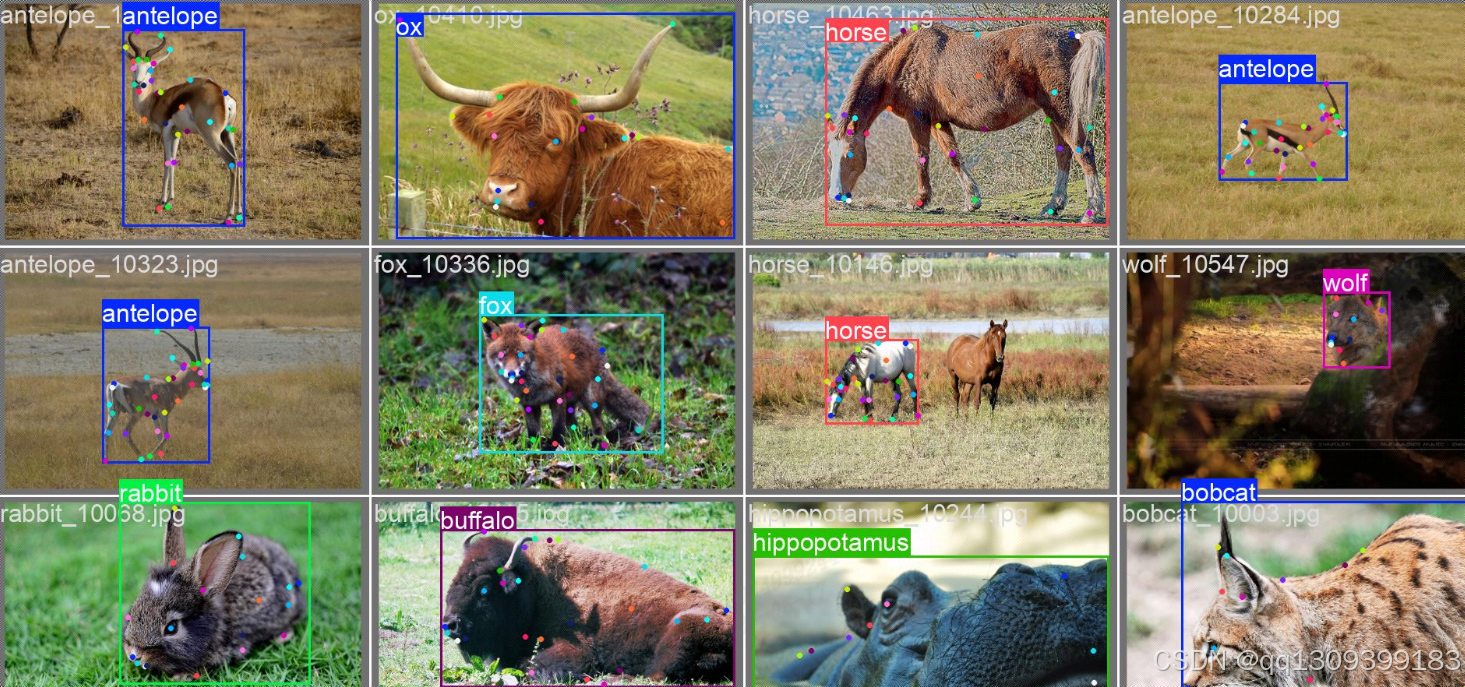
数据集分析
您的数据集包含50种不同的动物类别,每个动物有39个关键点。数据集结构如下:
- 训练集:
/home/ady/repos/KeypointDemo/yoloDataset/images/train/ - 验证集:
/home/ady/repos/KeypointDemo/yoloDataset/images/val/ - 测试集:
/home/ady/repos/KeypointDemo/yoloDataset/images/test/
关键点配置
- 关键点数量: 39个
- 每个关键点维度: 3 (x, y, visibility)
flip_idx定义了水平翻转时关键点的对应关系
YOLOv8-pose训练建议
1. 数据准备验证
确保:
- 每个图像有对应的标注文件(.txt)
- 标注格式符合YOLOv8要求:
class_id x1 y1 w h kp1_x kp1_y kp1_v ... kp39_x kp39_y kp39_v - 关键点坐标已归一化(0-1)
2. 训练配置
创建YAML配置文件(如animal_pose.yaml):
# 动物姿态识别配置
path: /home/ady/repos/KeypointDemo/yoloDataset/
train: images/train/
val: images/val/
test: images/test/
# 关键点配置
kpt_shape: [39, 3]
flip_idx: [0, 1, 2, 4, 3, 10, 11, 12, 13, 14, 5, 6, 7, 8, 9, 15, 16, 17, 18, 19, 20, 21, 22, 23, 27, 28, 29, 24, 25, 26, 33, 34, 35, 30, 31, 32, 36, 38, 37]
# 类别
names:
0: antelope
1: grizzly+bear
# ... 其他类别 ...
49: dolphin
3. 训练命令
yolo pose train data=animal_pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640 batch=16
4. 关键训练参数建议
-
模型选择:
yolov8n-pose.pt(轻量级)yolov8s-pose.pt/yolov8m-pose.pt(平衡)yolov8l-pose.pt/yolov8x-pose.pt(高精度)
-
数据增强:
- 启用翻转、旋转、缩放等增强
- 考虑动物特有的姿态变化
-
学习率:
- 初始学习率: 0.01
- 使用余弦退火调度
-
其他参数:
batch: 根据GPU内存选择(16-64)imgsz: 建议640x640patience: 设置早停
5. 自训练策略建议
-
初始训练:
- 使用预训练权重
- 训练所有层
-
困难样本挖掘:
- 在验证集上识别表现差的样本
- 加强这些样本的训练
-
模型微调:
- 冻结部分骨干网络
- 微调检测头和关键点预测层
-
测试评估:
- 使用OKS(Object Keypoint Similarity)评估关键点精度
- 分析各类别的AP(平均精度)
6. 常见问题解决
-
关键点预测不准确:
- 增加关键点损失权重
- 检查标注一致性
-
类别不平衡:
- 使用类别加权损失
- 对稀有类别过采样
-
过拟合:
- 增加数据增强
- 添加Dropout层
- 使用权重衰减
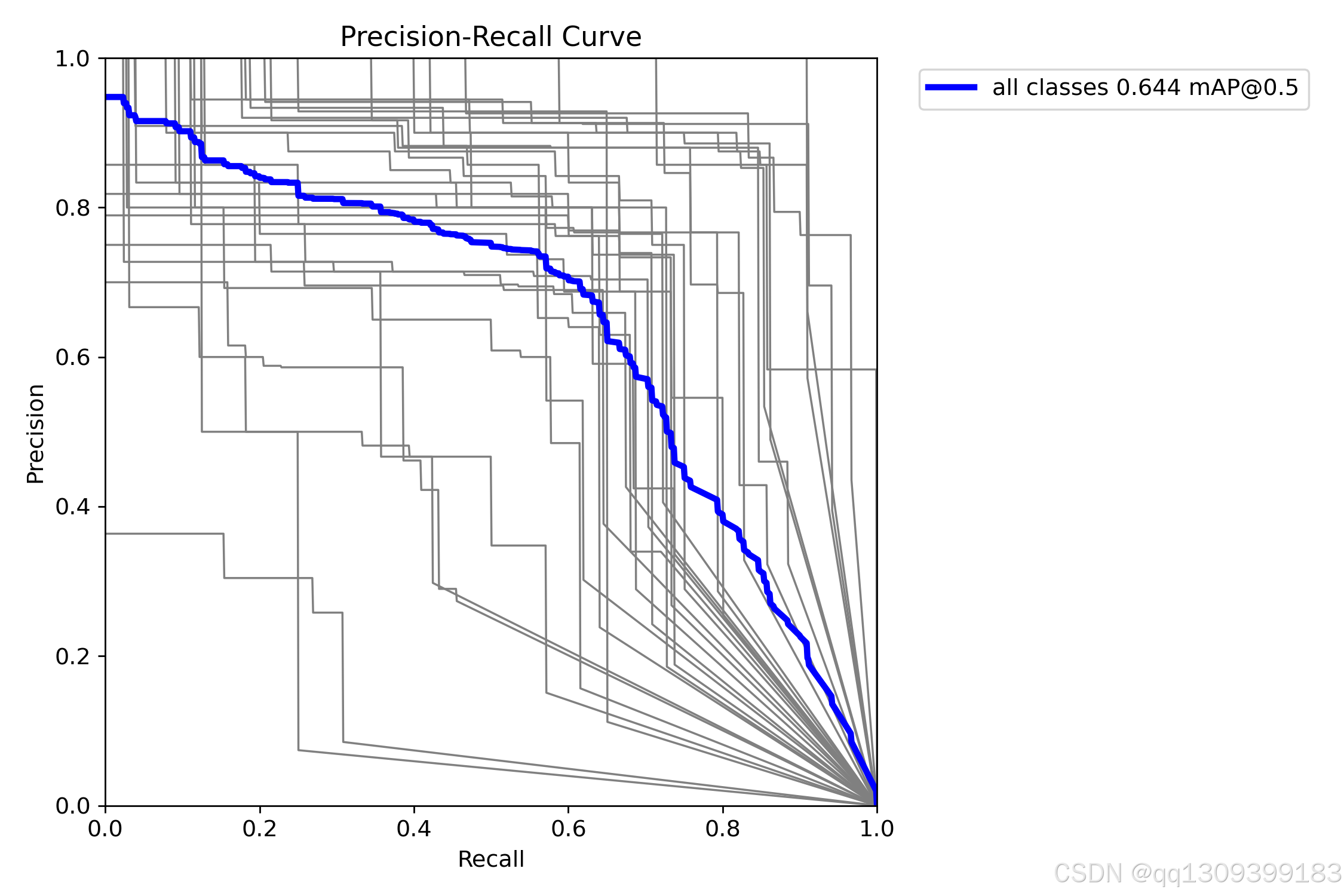
评估指标监控
训练时应关注:
- 目标检测指标: mAP@0.5, mAP@0.5:0.95
- 关键点指标: OKS, PCK(Percentage of Correct Keypoints)
- 损失曲线: box_loss, cls_loss, kpt_loss
部署建议

训练完成后:
- 导出为ONNX/TensorRT格式加速推理
- 使用Triton Inference Server部署
- 实现后处理逻辑解析关键点输出
希望这些建议对您的动物姿态识别项目有所帮助!如需更具体的指导,可以提供更多关于数据集规模和硬件配置的信息。


















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









