







YOLOv11垃圾分类检测模型训练指南
一、YOLOv11简介
YOLOv11是YOLO(You Only Look Once)系列目标检测算法的最新演进版本,继承了YOLO家族实时高效的特性,同时在精度和速度上都有显著提升。对于垃圾分类检测任务,YOLOv11能够准确识别各种垃圾类型并分类到可回收物、有害垃圾、厨余垃圾和其他垃圾四大类别。
二、训练环境准备
类别
硬件要求
- GPU:推荐NVIDIA RTX 3060及以上,显存8GB以上
- CPU:Intel i7或AMD Ryzen 7及以上
- 内存:16GB及以上
- 存储空间:至少50GB可用空间
软件环境
- 操作系统:Ubuntu 20.04/Windows 10/11
- Python 3.8或以上版本
- CUDA 11.3及以上
- cuDNN 8.2及以上
- PyTorch 1.10或以上版本
安装依赖
pip install torch torchvision torchaudio
pip install opencv-python matplotlib tqdm pandas seaborn
pip install ultralytics # YOLOv11官方库
三、数据集准备
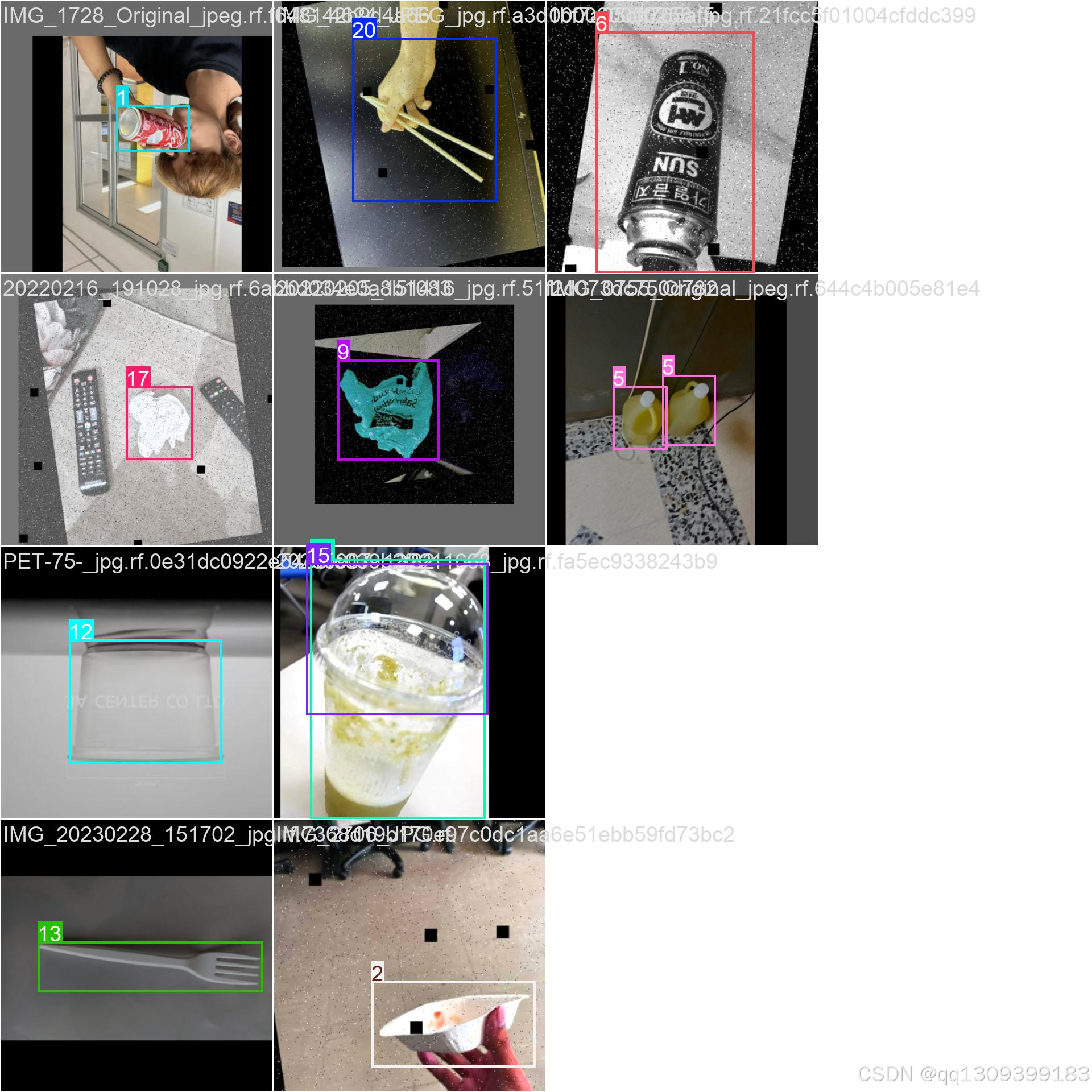
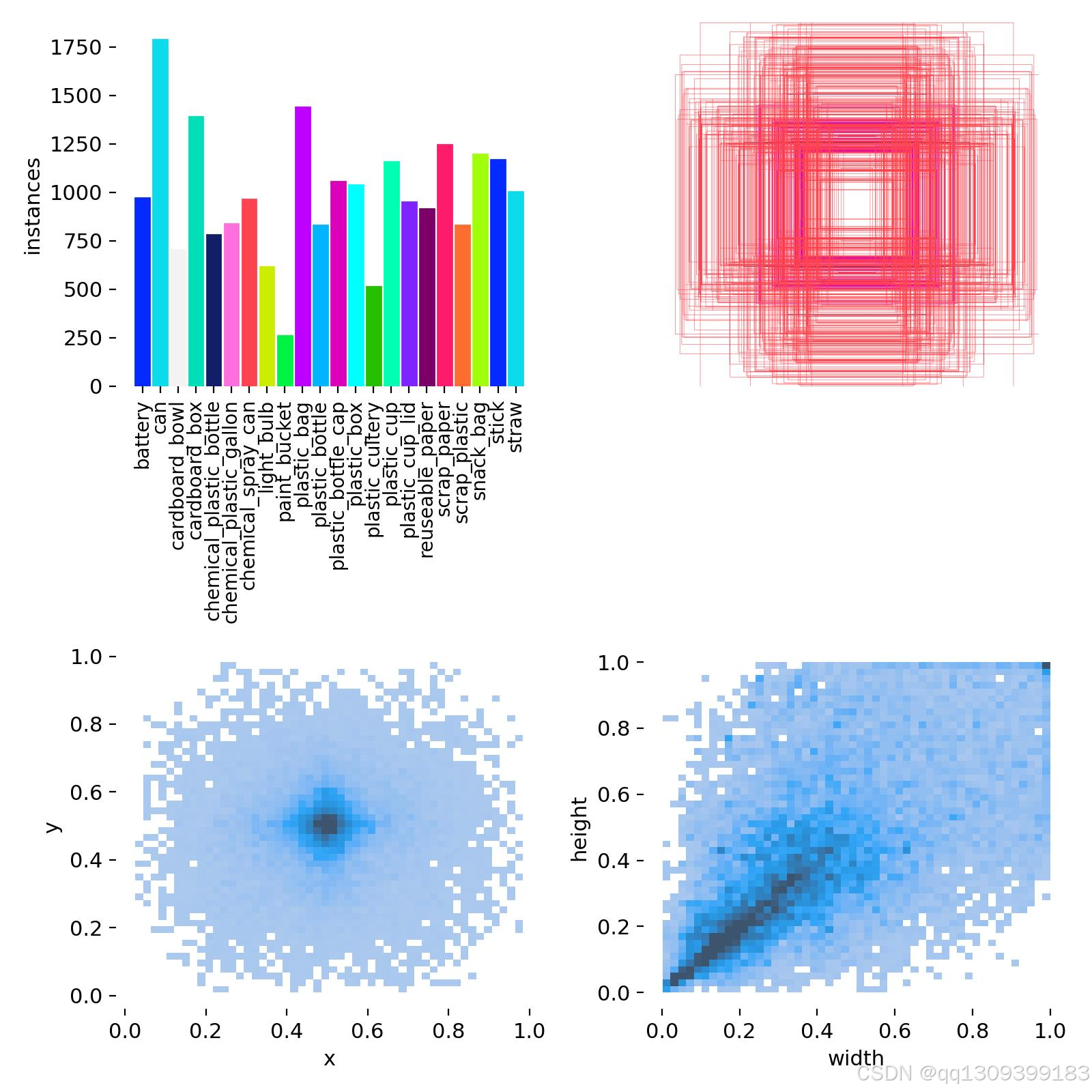
1. 数据收集
- 收集包含各类垃圾的图像,每类至少500-1000张
- 确保图像包含不同角度、光照条件和背景
- 可使用的公开数据集:
- TrashNet
- 中国垃圾分类数据集
- TACO (Trash Annotations in Context)
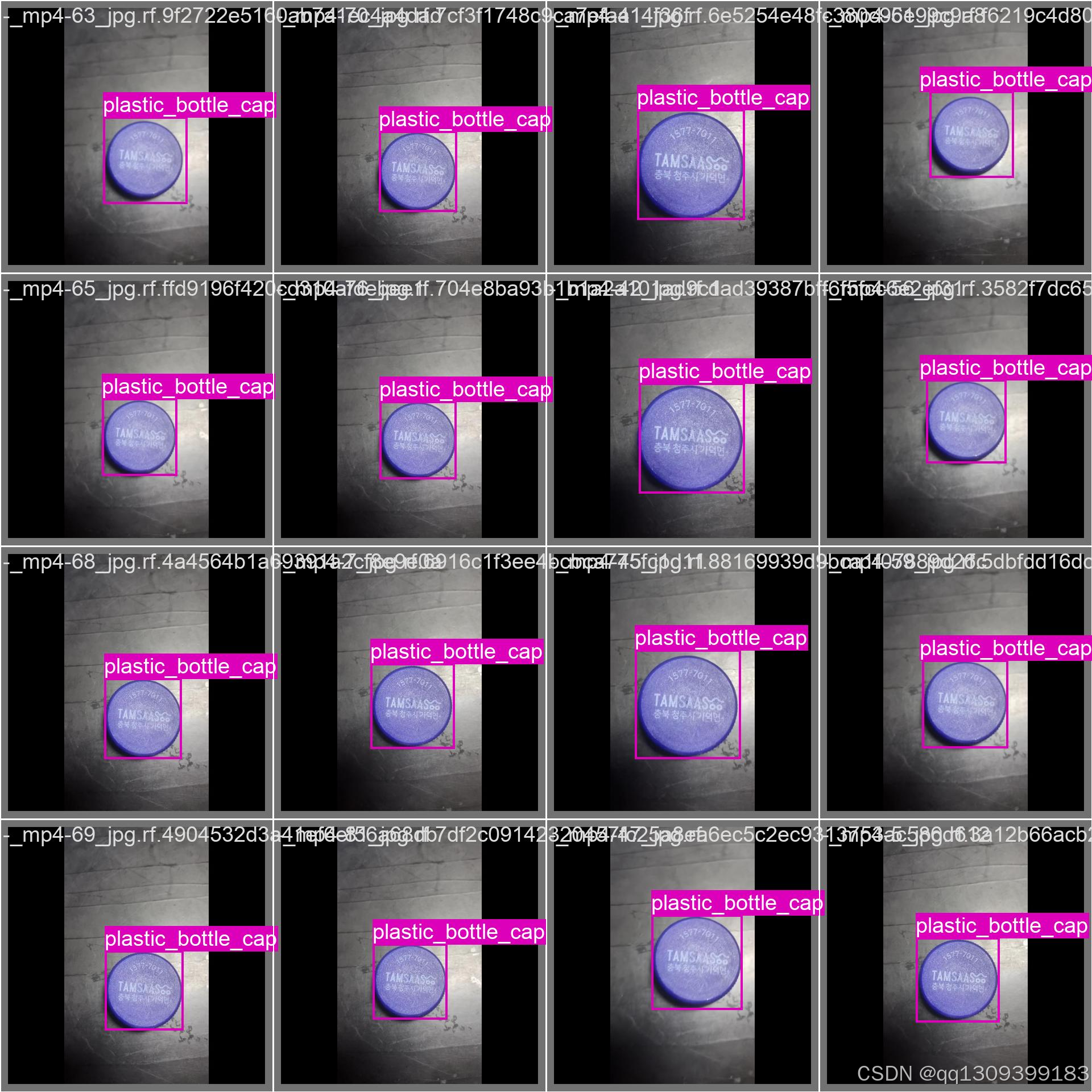
2. 数据标注
- 使用LabelImg或CVAT等工具进行标注
- 标注格式为YOLO格式(.txt文件)
- 类别定义示例:
0 可回收物 1 有害垃圾 2 厨余垃圾 3 其他垃圾
3. 数据集结构
dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
四、模型训练步骤
1. 配置文件准备
创建data.yaml文件:
train: dataset/images/train
val: dataset/images/val
4. 训练参数说明
epochs: 训练轮数,建议100-300batch: 批次大小,根据显存调整imgsz: 输入图像尺寸device: 训练设备,'0’表示GPU 0workers: 数据加载线程数optimizer: 优化器选择lr0: 初始学习率weight_decay: 权重衰减warmup_epochs: 学习率热身轮数
五、模型评估与优化
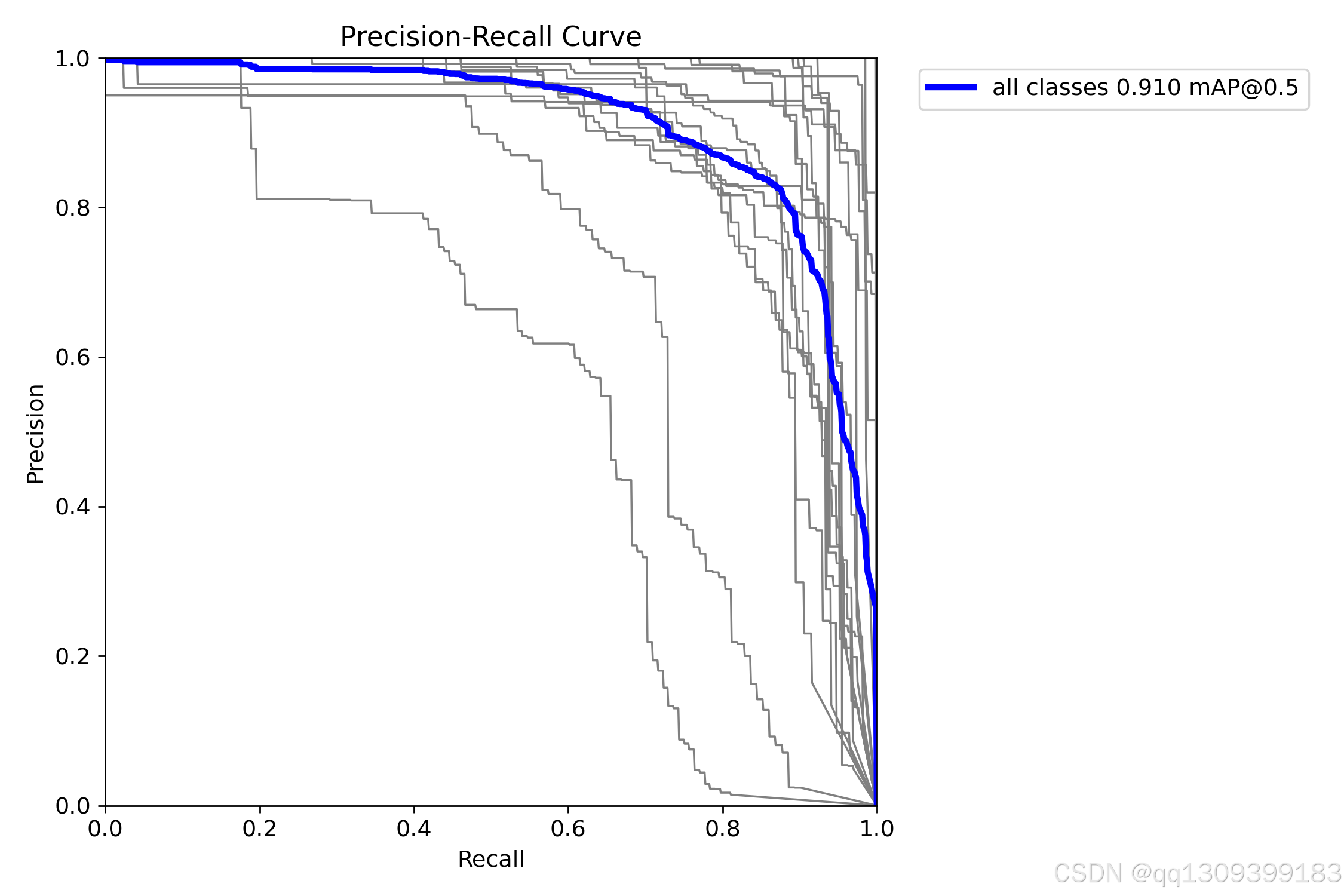
1. 评估指标
- mAP@0.5: 主要评估指标
- Precision: 精确率
- Recall: 召回率
- F1-score: 精确率和召回率的调和平均

2. 可视化训练过程
from ultralytics.utils.plots import plot_results
plot_results('runs/train/exp/results.csv')
3. 常见优化策略
-
数据增强:
- 添加旋转、翻转、色彩变换
- 使用Mosaic和MixUp增强
-
模型调整:
- 更换更大模型(yolov11m, yolov11l)
- 调整锚框(anchor)尺寸
-
超参数调优:
- 使用Optuna或Ray Tune进行自动化调参
- 调整学习率调度策略
六、模型导出与部署
1. 导出为ONNX格式
model.export(format='onnx', imgsz=[640, 640], dynamic=True)
2. 部署选项
-
Python部署:
model = YOLO('best.pt') results = model('test.jpg') -
TensorRT加速:
trtexec --onnx=model.onnx --saveEngine=model.engine -
移动端部署:
- 转换为TFLite格式
- 使用Core ML或NCNN
七、实际应用建议
-
实时检测优化:
- 对于摄像头输入,使用多线程处理
- 调整检测置信度阈值(通常0.4-0.6)
-
持续学习:
- 收集误检样本加入训练集
- 定期微调模型
-
性能平衡:
- 在速度和精度间权衡
- 根据硬件选择合适模型尺寸
通过以上步骤,您可以成功训练一个高效的YOLOv11垃圾分类检测模型。实际应用中,建议从较小模型开始,根据需求逐步升级模型规模。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









