









声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
以往很多论文里大多采用西储大学轴承数据集,今天,给大家带来一期东南大学齿轮箱数据故障诊断教程与代码,可放心往下看,小白也能一看就会!
为了防止创新点不够,本期代码采用24年新出的蛇鹫优化算法SBOA优化VMD分解,并提供了6种不同的适应度函数,从而对数据完成预处理过程。随后,基于双向门控循环单元BiGRU模型对处理好的数据集进行分类预测。之前也有推文介绍过蛇鹫优化算法,性能也是非常不错,具体可以看以下这篇:
2024年SCI最新算法-蛇鹭优化算法(SBOA)-公式原理详解与性能测评 Matlab代码免费获取
同样的,本期代码所有流程均可一键运行全部出图,包括特征提取过程与故障诊断结果,还有打印出来的损失函数曲线,不像其他程序一样需要运行很多次,非常适合新手小白!
当然,本次模型在知网上和WOS上也是完全搜不到的,不信可以看下图:
原理详解
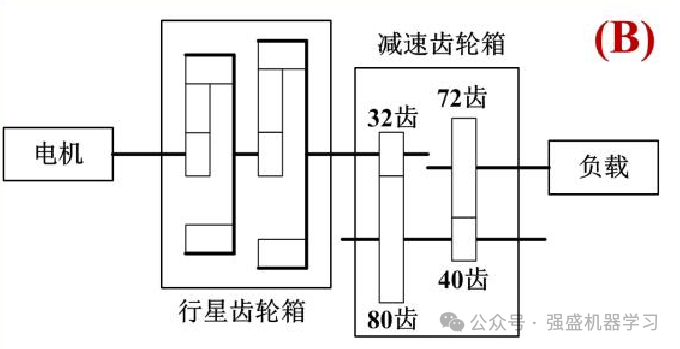
此处使用的数据是东南大学官方的齿轮箱数据!首先说一下该数据集的处理步骤以及来源:

1.数据预处理。取官方下载的东南大学齿轮箱数据集,选择以下几个文件:
Chipped_20_0:故障状态为齿轮上有裂纹
Health_20_0:健康状态
Miss_20_0:故障状态为断齿
Root_20_0:故障状态为齿轮根部裂纹
Surface_20_0:故障状态为齿面磨损
提取五个数据的第三列,设置滑动窗口w为1000,每个数据的故障样本点个数s为2048 。将所有的数据滑窗设置完毕之后,将所有的数据和类别综合到一个Excel中(此处Excel已直接整理好)。
2.特征提取。这里的特征提取主要分为3个步骤。
①首先,VMD 方法要从信号中提取丰富的特征信息, 需要选定最佳的参数组合,模态个数 k 和惩罚参数 α 都要选定在合适的区间,过大过小都会导致特征信号提取不充分。因此,需要用优化算法进行优化。
本期代码选择了一个24年新颖且性能较好的算法——蛇鹫优化算法SBOA优化VMD算法,从而选择最佳参数K和α。
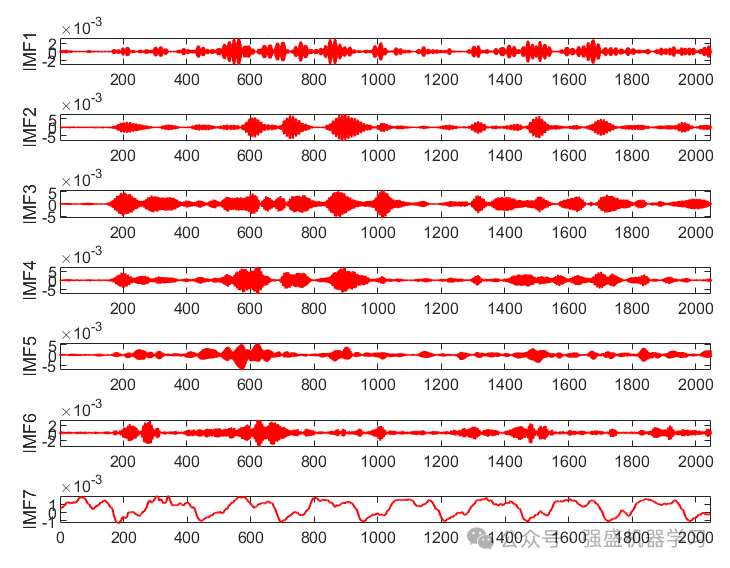
同时,需要选择合适的适应度函数,此处提供了6种适应度函数,分别为包络熵、样本熵、信息熵、排列熵、包络峭度因子或复合指标最小,大家任选其一即可。优化完后,提取每个样本的最佳IMF分量,并丢弃其他分量,因为最佳IMF分量已经包含了故障特征的丰富信息,如下图所示。

②其次,对最佳IMF分量的9个指标进行计算,分别是:均值,方差,峰值,峭度,有效值,峰值因子,脉冲因子,波形因子,裕度因子(对应特征1-9)
③最后,得到的数据是1000*9的矩阵。为了进行诊断,我们需要对每行数据打上标签,其中1-5代表不同的故障类型。
3.故障诊断。按照上述流程处理完数据集后,就是我们常见的机器学习分类数据集了。此处,我们再采用BiGRU分类模型,划分70%为训练集,30%为测试集,将数据送入网络进行训练和预测,得到最终故障诊断准确率结果。
流程介绍
上面的文字可能有些冗长,此处简单讲下故障诊断的具体步骤:
1)将采集到的数据进行融合处理,利用蛇鹫优化算法SBOA对VMD的惩罚因子以及模态分量进行参数优化,并找寻最小适应度的索引值,将两个参数以及索引值代回VMD中;
2)从六种适应度函数中选择一种,对最佳IMF分量的9个指标进行计算并打上标签,从而提取其故障特征;
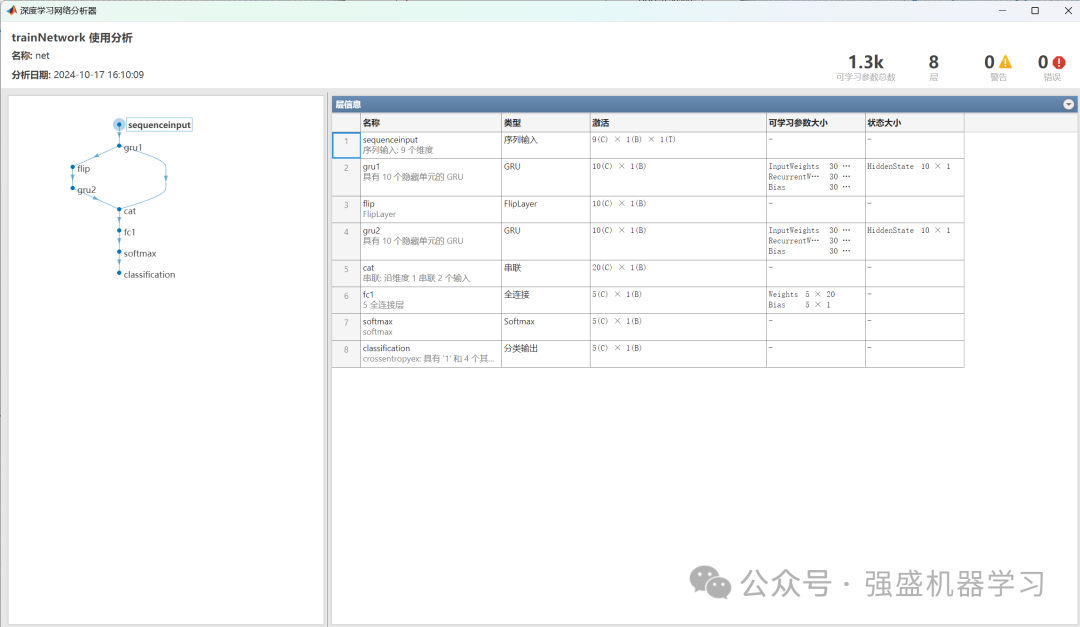
3)设置BiGRU模型参数,训练神经网络模型,完成多特征分类任务。
结果展示
此处采用的BiGRU模型,知网上用的也很少,大家也可以自行替换成想要的模型,或者加入更多的优化算法,提高分类准确率!
首先运行plotFigure文件,可画出VMD分解后的图片,包括2D分解图、3D分解图,功率谱,幅值谱等等,可完全满足大家的需求!
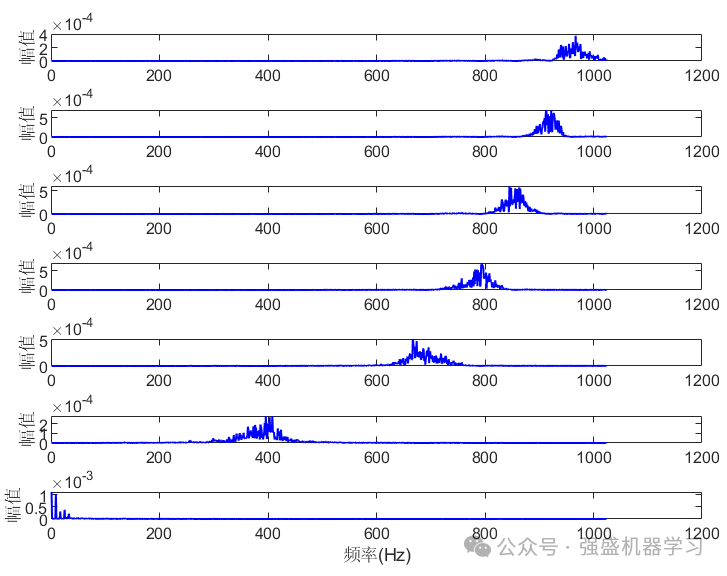
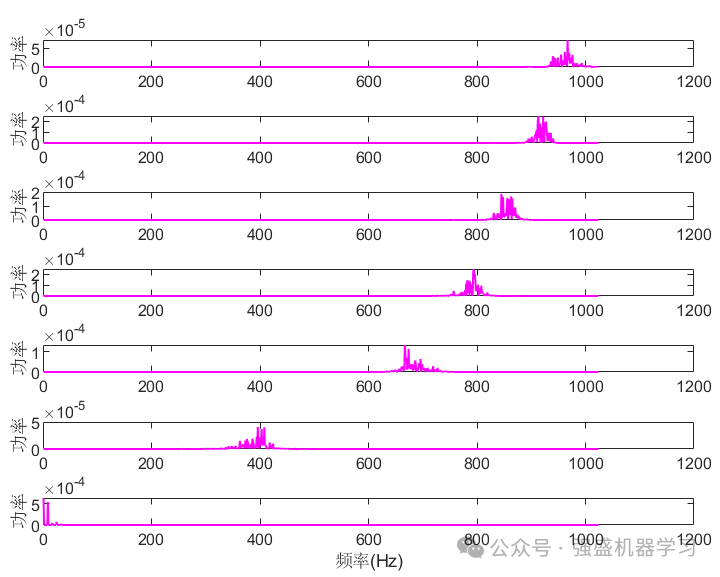
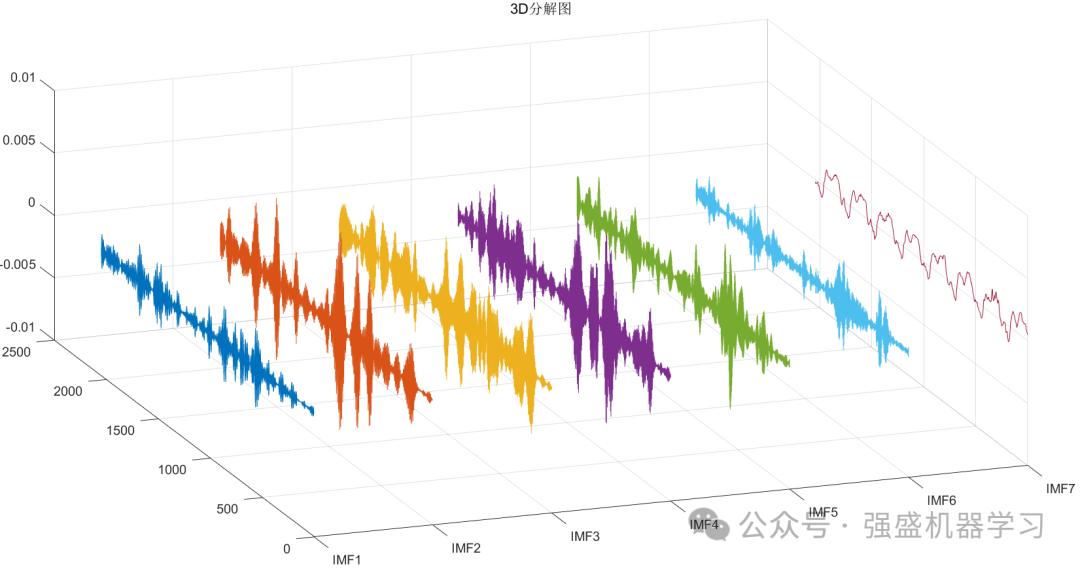
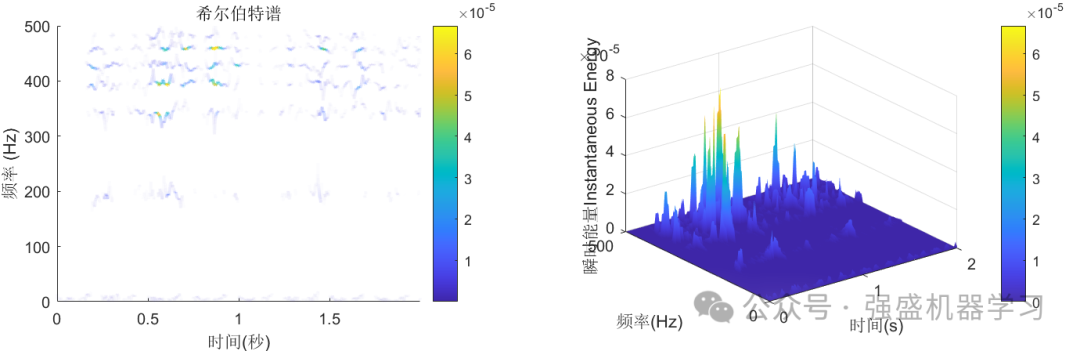
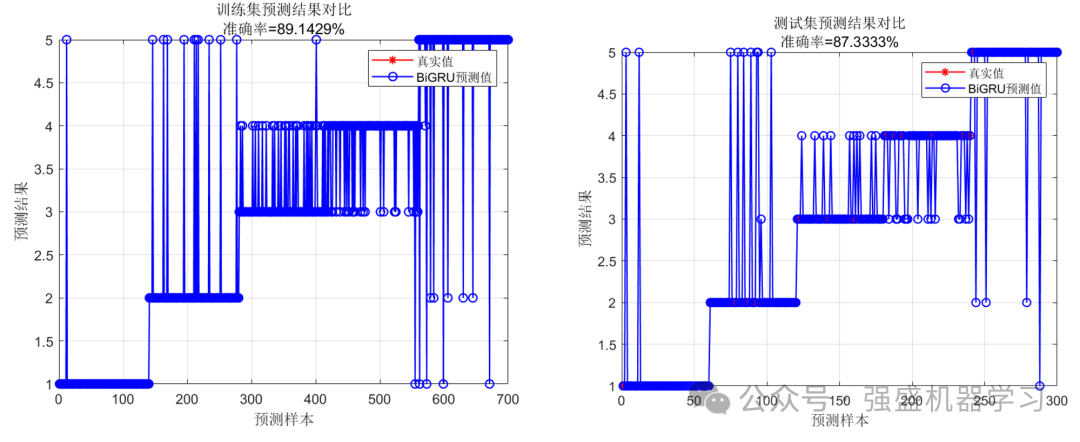
接着是分类效果图,包括训练集与测试集:
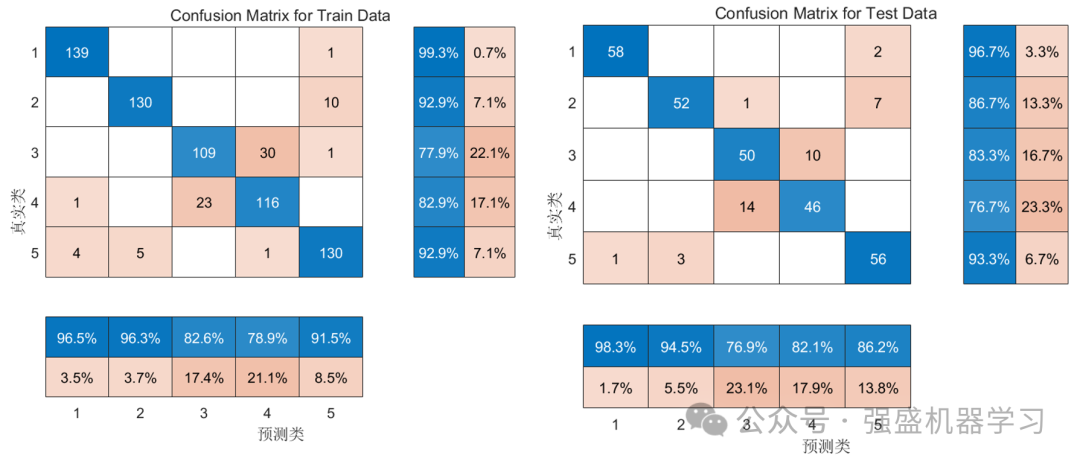
其次是混淆矩阵图,包括训练集与测试集:
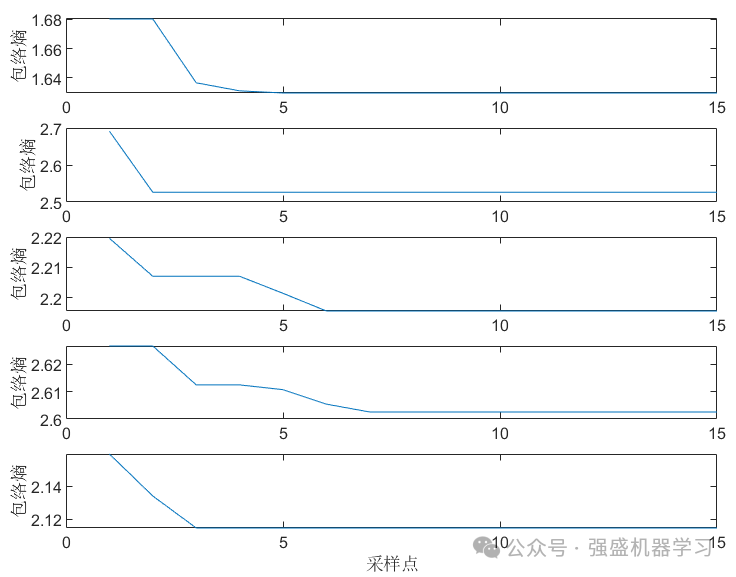
以及每个状态的包络熵(可自行替换为其他适应度函数):
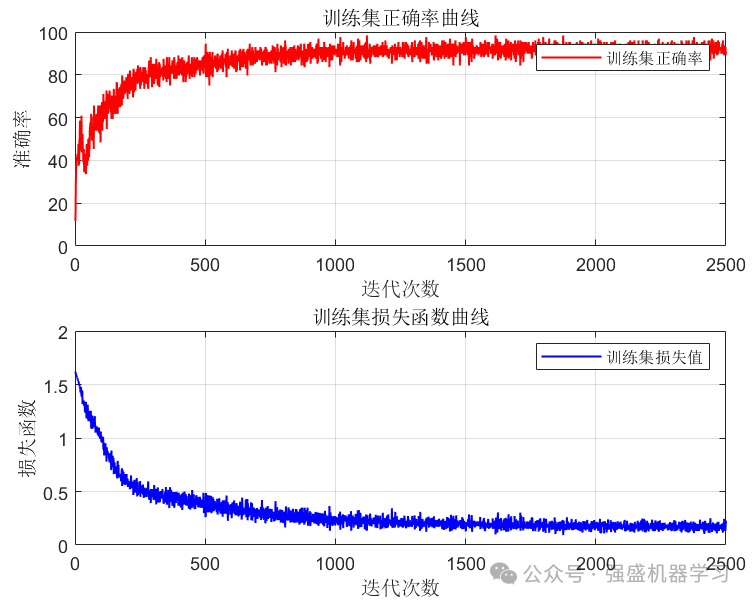
最后是打印出来的损失函数与准确率曲线:
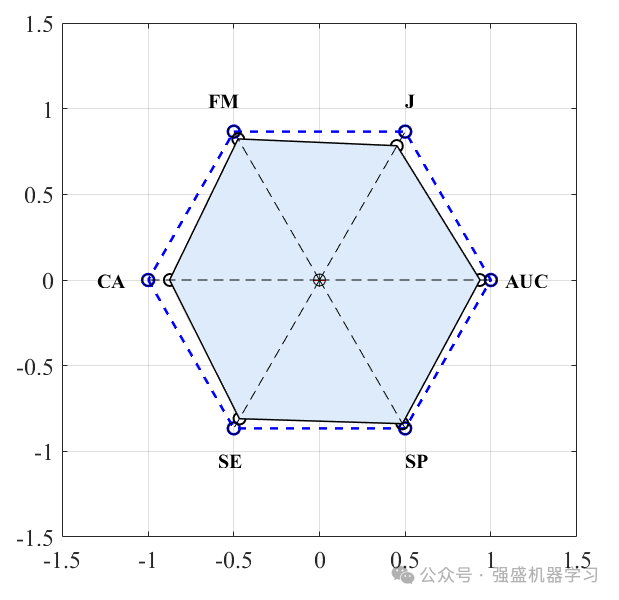
六边形分类指标图:
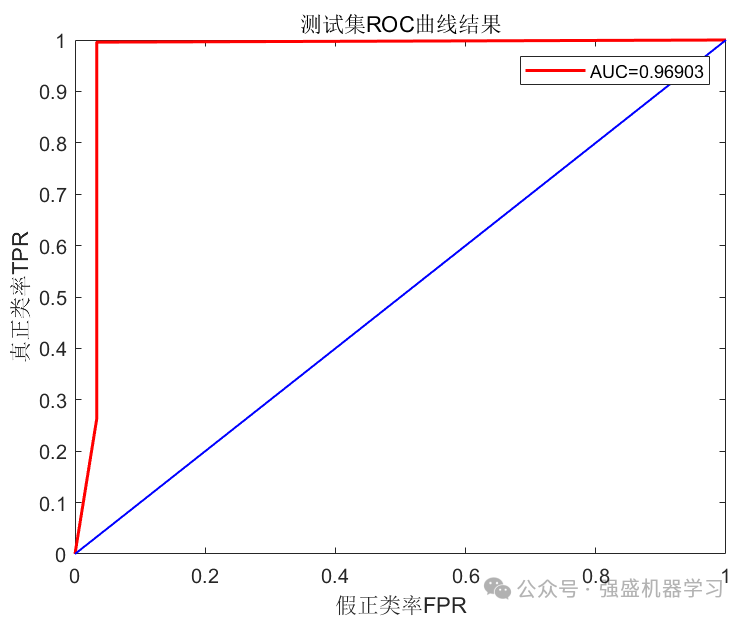
ROC曲线:
以及BiGRU网络结构图:
以上所有图片,作者都已精心整理过代码,都可以一键运行main直接出图,不像其他代码一样需要每个文件运行很多次!
不信的话可以看下面文件夹截图,非常清晰明了,并且有使用说明!

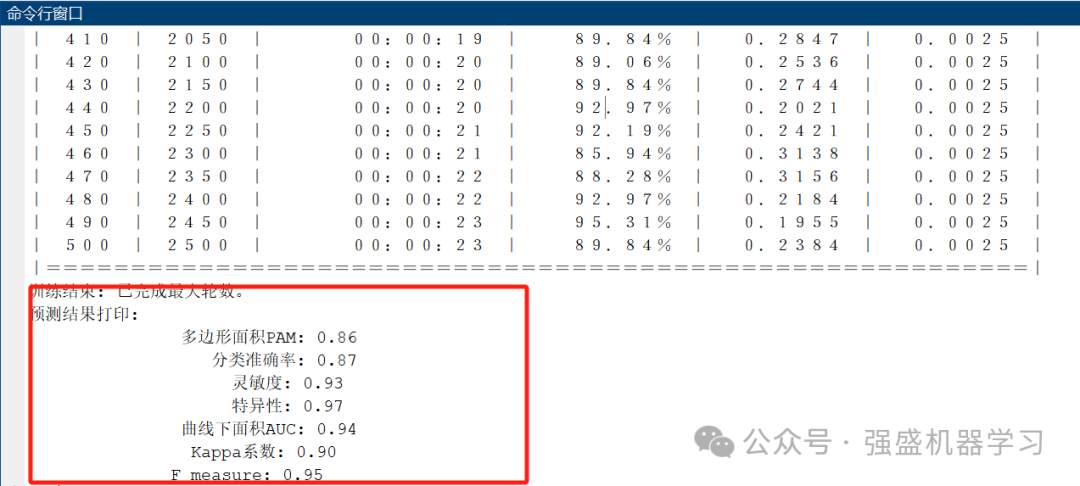
最后,命令行窗口也会显示六种分类指标!包括多边形面积PAM、分类准确率、灵敏度、特异性、曲线下面积AUC、Kappa系数以及F_measure,可以大大增加论文工作量!
其中,刚刚讲到的数据预处理部分已帮大家整理成Excel格式,特征提取与故障诊断部分已全部包含在main文件及其子函数中,VMD画图部分则在plotFigure文件中,非常清晰。
部分代码展示
%% 读取数据(已将原始数据整理完放入Excel中)
res = xlsread('东南大学齿轮箱数据.xlsx');
%% 设置参数
D = 2; % 优化变量数目
lb = [100 3]; % 下限值,分别是a,k
ub = [2500 10]; % 上限值
T = 15; % 最大迭代数目
N = 10; % 种群规模
vmddata = [];
samplenum = size(res,1)/10;
……
……
……
%% 分析数据
num_class = length(unique(data(:, end))); % 类别数(Excel最后一列放类别)
num_dim = size(data, 2) - 1; % 特征维度
num_res = size(data, 1); % 样本数(每一行,是一个样本)
num_size = 0.7; % 训练集占数据集的比例
data = data(randperm(num_res), :); % 打乱数据集(不打乱数据时,注释该行)
flag_conusion = 1; % 标志位为1,打开混淆矩阵(要求2018版本及以上)
%% 设置变量存储数据
P_train = []; P_test = [];
T_train = []; T_test = [];
%% 划分数据集
for i = 1 : num_class
mid_res = data((data(:, end) == i), :); % 循环取出不同类别的样本
mid_size = size(mid_res, 1); % 得到不同类别样本个数
mid_tiran = round(num_size * mid_size); % 得到该类别的训练样本个数
P_train = [P_train; mid_res(1: mid_tiran, 1: end - 1)]; % 训练集输入
T_train = [T_train; mid_res(1: mid_tiran, end)]; % 训练集输出
P_test = [P_test; mid_res(mid_tiran + 1: end, 1: end - 1)]; % 测试集输入
T_test = [T_test; mid_res(mid_tiran + 1: end, end)]; % 测试集输出
end
%% 数据转置
P_train = P_train'; P_test = P_test';
T_train = T_train'; T_test = T_test';
%% 得到训练集和测试样本个数
M = size(P_train, 2);
N = size(P_test , 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
t_train = categorical(T_train);
t_test = categorical(T_test );完整代码获取
如果需要以上完整代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
GZZDD

















 4918
4918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









