deftraverse(y):
x = y
while(x.getPred()):print(x.getId())
x = x.getPred()print(x.getId())
wordgraph = buildGraph("fourletterwords.txt")
bfs(wordgraph, wordgraph.getVertex('FOOL'))
traverse(wordgraph.getVertex('SAGE'))
实现广度优先搜索建立完单词关系图以后,需要继续在图中寻找词梯问题的最短序列需要用到"广度优先搜索Breadth First Search"算法进行搜索BFS是搜索图的最简单算法之一,也是其他一些重要的图算法的基础广度优先搜索给定图G,以及开始搜索的起始顶点sBFS搜索所有从s可到达顶点的边而且在达到更远的距离k+1的顶点之前,BFS会找到全部距离为k的顶点可以想象为以s为根,构建一棵树的过程,从顶部向下逐步增加层次广度优先搜索能保证在增加层次之前,添加了所有兄弟节点到树中从fool开始











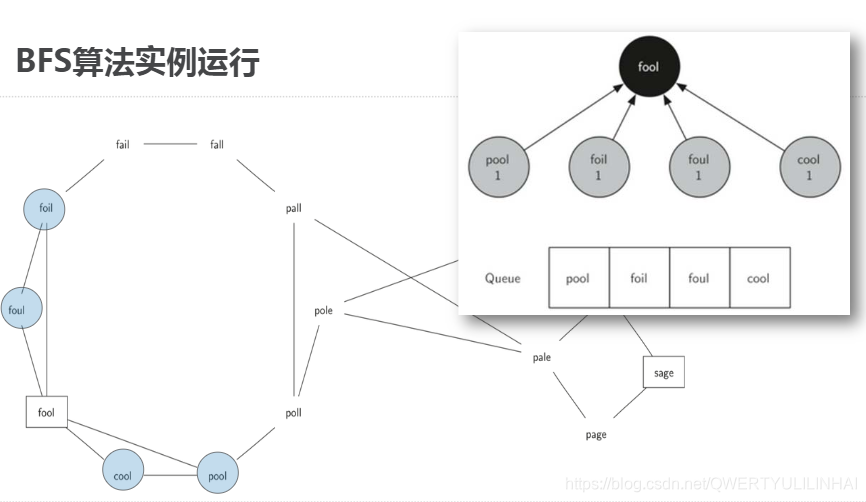
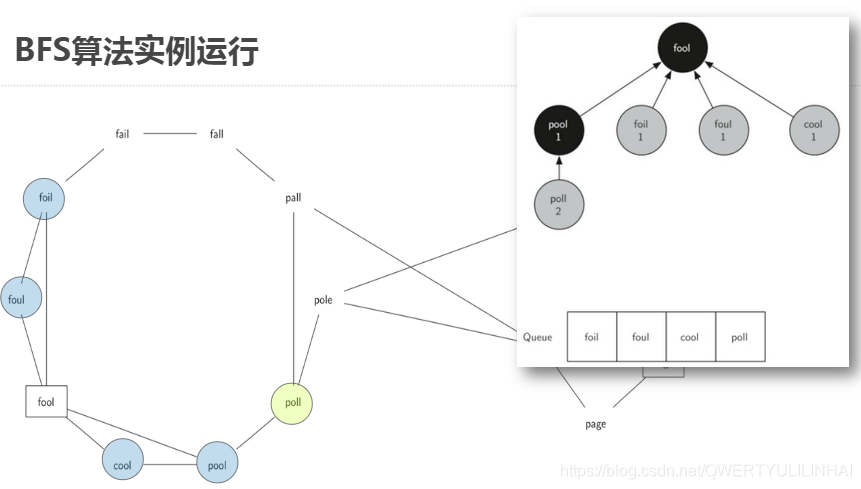
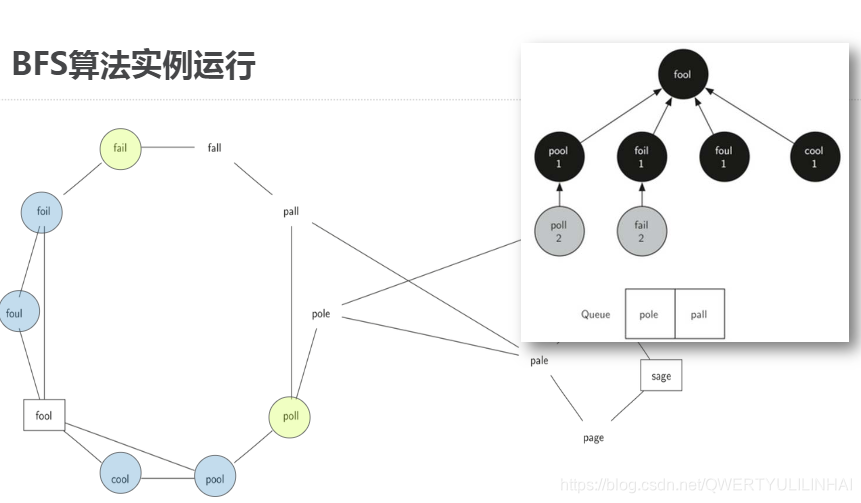
















 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











