







👉导读
2017 年,某业务团队通过某次技术会议确定禁止在代码中使用异常,当时的目的旨在规范一些存在的基本问题,诸如:使用异常导致协程冲突,捕获到异常和抛出的不一致;未捕获异常导致后端框架中的 worker 进程终止,重启 worker 进程漫长导致效率很差;数据一致性问题等。代码到底该不该用异常,时至今日仍是一个争论不休的话题,本文作者根据自己多年的工作经验,撰写了《异常思辨录》系列专栏,希望能体系化地帮助到大家。本文为系列第四篇。主要聚焦上层的决策点进行展开,欢迎阅读。读完全文还可以参加惊喜活动抽奖哦!
👉目录
1 上层的决策点
1.1 建立可持续的一致性
1.2 历史的局限性
1.3 好复盘的重要性
2 结语
01
上层的决策点
作为一个完整的方案,没有老板的推动永远只是空谈,所以最后一章还是落实到老板的决策场景中。好用是一个完整方案的基石,老板的推动才是全面铺开的保证。
1.1 建立可持续的一致性
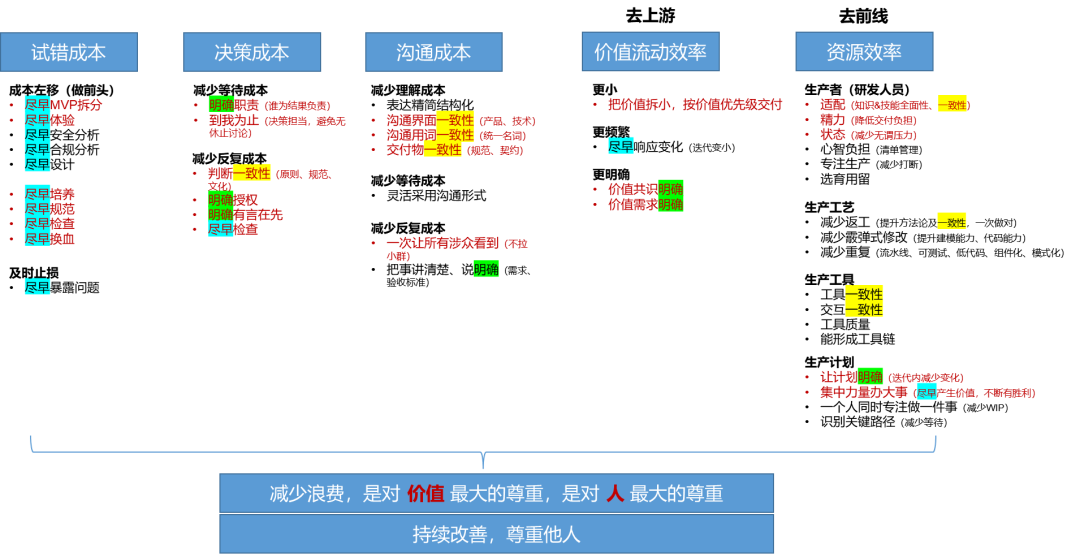
复杂性带来了效率下降。所以,提升效率的方法就是有效地降低复杂性,而降低随机复杂性的方法是提高一致性。对于一个系统来说,一致性本身会带来逆熵,减缓系统的熵增,让系统相对有序,从而提升效率,或者至少保证效率不降低得很快。
所以对于上层决策点从来不是用 int 来返回错误码或用异常思想来编写 C++ 代码 ,相应的决策应该是符合当时研发环境的。比如:
你不可能让一个完全不懂面向对象的分析与设计的同事,来完成异常的设计和使用;
你不可能在没有一个完整错误码管理系统在线的情况下,使用无法控制的异常类型来进行逻辑异常的运营和分析;
你不可能在没有构建基于领域驱动开发思想的情况下,分配合理的错误码,从而正确的使用错误码;
没有人员能力完成对某些重要系统重构时,领导凭着一些一句话结论复盘,只能选择相对可控相对容易实现的一致性的方案;
我们写代码都是在一定的约束条件下进行软件开发的。开发者不会有无限时间,无限资源写最完美的代码。所以,我们一定是带着技术债前行的,只有多少之分。这些技术债都可能产生偶然复杂性。
所以站在上层的视角,提升组织一致性,改善工具,持续信息化,数字化才是目标,使用某种手段只是解决方案。
以长期效率为核心,沉淀优质软件资产和工程能力;
提升团队的持续交付能力;
沉淀优质软件资产和工程能力;
控制复杂性,缩小犯错的可能性空间,减缓复杂系统的“熵增”,价值随团队规模而放大。
所以无论是大仓小仓,无论是异常还是返回错误码,无论是用统一编译还是静态基线公共库编译都是围绕一致性这一目标而实现的。同时作为管理者,将一致性融入到我们精益研发中也是其重要的目的。
1.1.1 一致性 1:建模和代码的实现一致
首先对于大规模复杂软件, 上层需要确定思想上的认知的一致——我们的业务是要做 10 年以上的——所以一把梭被认为是敏捷,要啥设计 这样的想法绝对是对软件敏捷开发的误解,以下摘自《敏捷软件开发 12 条原则》:
● 原则 8:敏捷过程倡导可持续开发。责任人、开发人员和用户要能够共同维持其步调稳定延续;
● 原则 9:坚持不懈地追求技术卓越和良好设计,敏捷能力由此增强;
● 原则 12: 团队定期地反思如何能提高成效,并依此调整自身的举止表现。
所以团队如果想要将软件工程应用好大规模的业务系统中,建模就是绕不开一个的话题,对于领域模型的动态建模就需要绘制序列图用于分析业务正常或异常时需要执行的操作。
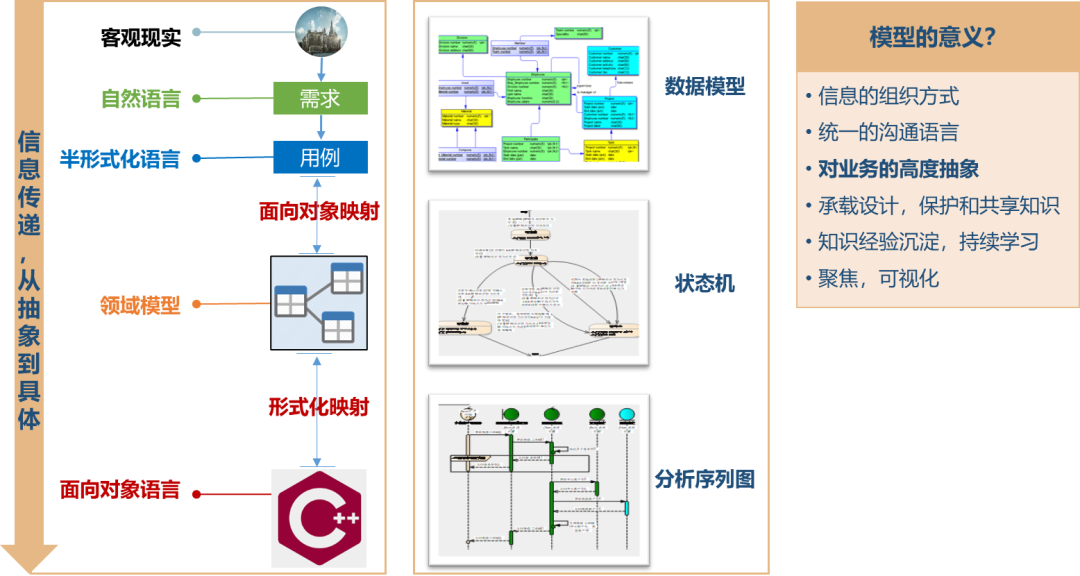
也就是说业务异常的设计并不是在编写代码中才开始设计的而是在面向对象而建模时就开始设计的。对于异常流的处理后续的业务操作,都需要体现到序列图中,而不是隐藏在代码,这样才能保证最终编写的业务代码和最初设计的模型的一致性。
如果抛弃了异常,势必要对所有的操作进行返回码检查,哪怕是自己根本无法处理的异常,也必须进行处理,一旦有了这样的一种思维定式,就会造成建模和实现代码的不一致。例如:
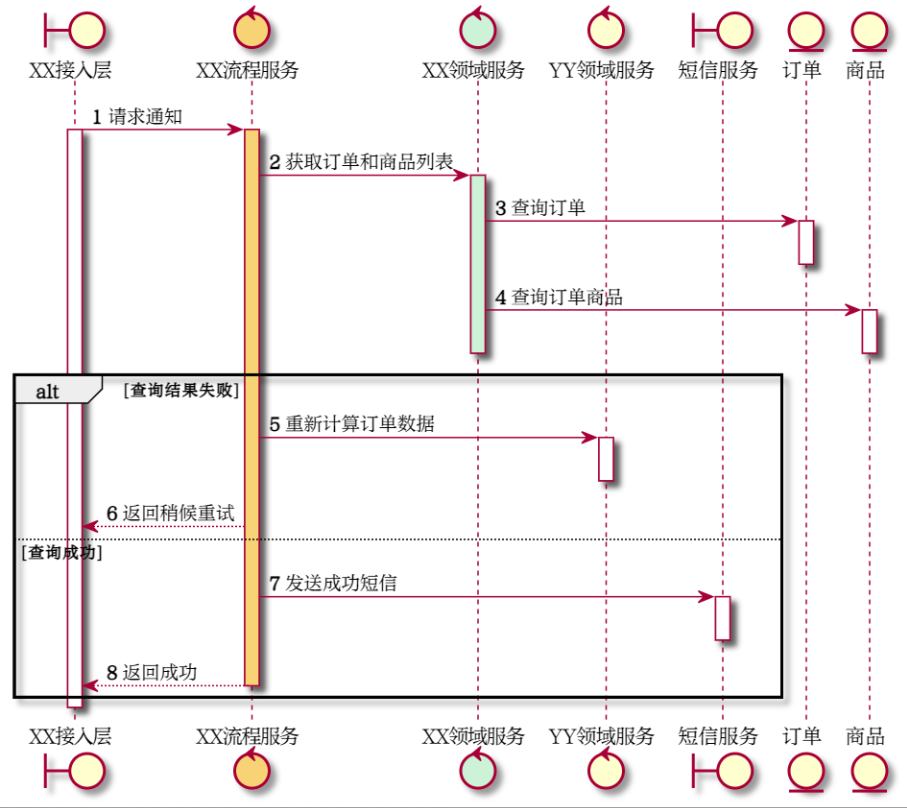
某员工拿到一个任务开发一个2 获取订单和关联的商品列表 的任务,原始的序列图流程中并没有对 4 查询订单商品 进行额外的异常捕获流程;
那么当获取订单成功,获取商品列表失败时(并不是返回空),员工很自然的想到这不是一个异常流,结果返回一个空列表和订单基础信息给回去;
上层员工在编写代码 1 请求通知 拿到了一个分完整的带空商品列表的订单记录,会认为这是正常流程,只是这个订单的商品列表确实为空,于是继续执行返回成功;
但实际上的是需要处理 4查询订单商品 这个异常的,因为根据异常的思维,第 4 步这个异常应该被转发到步骤 1。
在普通 C 语言的流程化设计过程中我只需要对我关心的异常负责的表现是,不需要对所有的函数调用结果进行确认,失败了也不影响下一步执行。而在 C++ 等高级语言中,默认思想是任何操作(构造一个对象、设置对象属性、调用对象方法)都有可能出错,如果没有兜底策略,出错的最终的结果就是程序终止。
而按照异常的思想,根据序列图,3 查询订单 4 查询订单商品 操作根本就需要对返回码进行处理,到 4 查询订单商品 时出现了异常,那么 XX 领域服务对象 正常析构,XX 流程服务对象 捕获到 4 查询订单商品的异常,执行异常分支流。
如果真的推行了异常思维,将代码和真正设计时的序列图结合起来,那么代码编写者再也不会有何时判断返回值的压力了,只有在序列图上出现的异常才会应该被捕获,否则其他的业务异常就直接根据框架或组件的行为向上传播到能处理异常的业务逻辑来进行处理。因为业务处理异常的职责已经明确到具体业务的执行者,而非代码编写的人员 。
1.1.2 一致性 2:组件框架职责一致
当使用错误码时,如果想要让组件和框架解耦,那么就需要对异常这样的一种场景做一致性的规范。即:抛出错误和捕获错误需要同时保证异常数据的完整性。
举一个最近在讨论 AppSet 分区实现的一个例子:
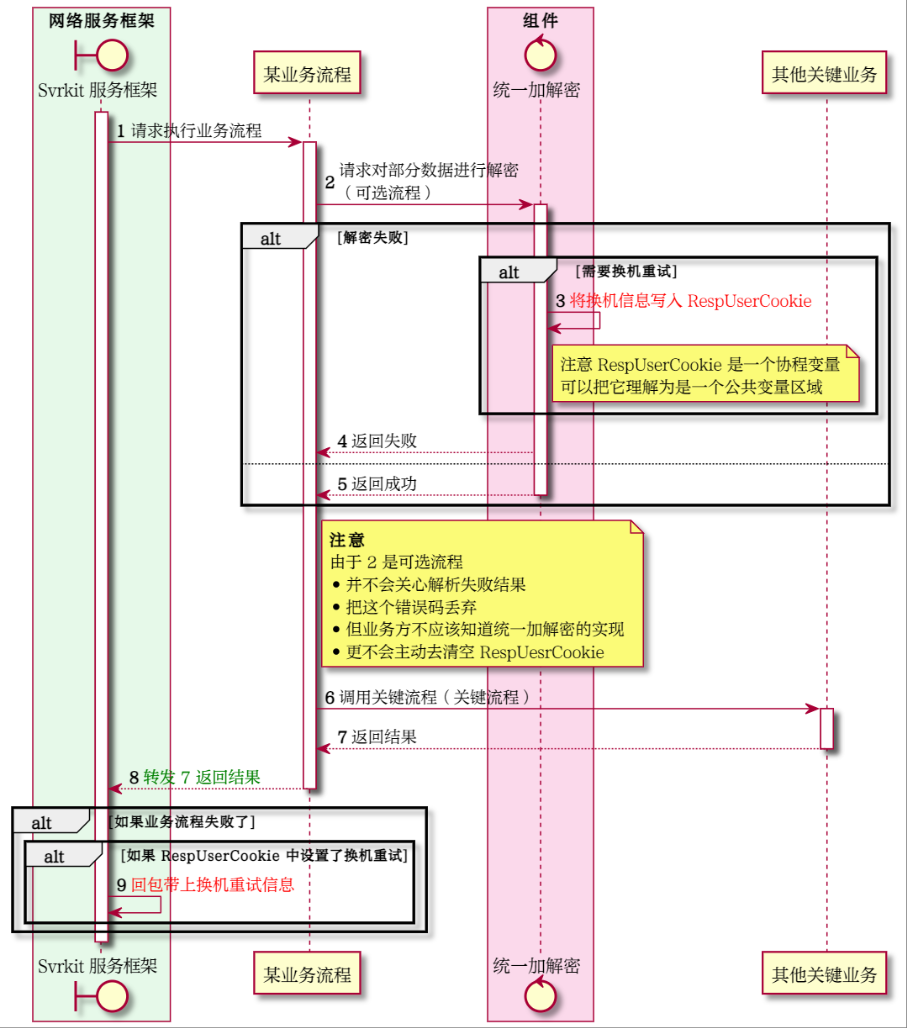
AppSet 需要知道是否需要将换机重试这异常上报给调用方,使用错误码就会出现一个非常两难的问题:
统一加解密组件报告说,本机有问题报告异常,下次请求换机重试并返回了一个返回码 α,然后将换机信息放置到一个全局变量中;
但业务流程任务统一加解密是一个可选的流程,继续往下走调用某关键流程,关键流程压根不关心换不换机重试,甚至完全有可能只能使用本机器进行重试请求,报告一个错误;
业务任务步骤 6 是关键流程,将其转发给上层框架错误,但此时只转发了错误码,因为对于业务方也不知道加解密干啥什么事儿;
框架收到了一个错误,并开始解析
RespUserCookie中的是否需要换机重试,回包带上换机重试的控制信息;此时就出现了实现的不一致,因为步骤 6 的异常,和步骤 2 的异常并没有被完备的整体的转发给上层。
可能有些大聪明会想到一个解决办法,就是对每个需要换机重试的的场景都返回同一个错误码,这样会带来更严重的问题:
错误码丧失了可运营可监控的这一特性,因为这样的错误码必须是和框架强绑定的,比如 -16 在 svrkit 框架里表示全程票据校验失败,但是哪个票据失败,哪个服务的票据失败,什么样的票据失败,根本就无从获取;
错误码不再反映业务的异常,虽然实际上确实是发生了业务异常,但错误码为了耦合控制信息的特性,不得不让位是的职责发生的变化。
按照异常建模一节所描述的,这些附加的信息是组合在异常这个对象中的,他们是完整的一体的,不应该拆开放置在不同的位置。Xwi 在设计之初曾经想同时使用函数返回码和错误栈,结果造成了理解不一致。这种框架和组件之间不一致的行为造成理解上的偏差也会形成债务。
还是回到异常设计的初衷:
异常是一个对象,这个对象不仅有返回值、还有控制码、错误信息,以及具备可扩展的能力(C++ 可使用类型擦除,C# 可使用装箱拆箱,不同语言都有不同的这样的能力),保证相关的角色可以获取自己的自己能够处理的信息,至于这个对象的属性、方法、事件,则是通过去泛化建模之后得到的,而不是凭空想象的;
异常需要能够被完美的转发,即不能处理异常的角色不应该对抛出的异常进行拆解从而破坏其完整性。
如果按照上述的思想重新设计,那么结果就会变得非常简单。
步骤 2 直接把业务异常捕获并忽略(打个日志什么的);
步骤 6 直接抛出异常,不需要换机重试;
步骤 9 就不会发生,因为接受到的是一个完整的异常对象而不只是一个意义不明的错误码。
1.1.3 一致性 3:不同语言实现一致
由于开篇我们就描述了特定团队的特定目的,所以在编码之前的流程就特别重视。即对于不同的业务建模的情况下:
1. 同一的业务序列图所对应出来的代码的差异应该只体现在语言关键字特征上,而非流程结构;
2. 对于基础组件或框架在不同语言中的维护成本将大大降低:不需要因为某些语言特性被禁用而修改特定代码,以适配这样的残缺语言的特性;
3. 编写业务代码的员工也将没有负担的完全按照序列图中描述的流程来实现:不需要因为某些语言的特性被禁用而额外实现逻辑,也不用担心会产生可能造成历史债务。
使用异常,在支持异常的语言 C++、JavaScript、Java、.NET 等都能编写出一样模式的代码,也许只是里面某些函数或语言关键字的不同(不支持面向对象的语言除外,这里适配成本过高)。
1.1.4 一致性 4:统一团队的思考模式
我曾经作为一个代码工作者参加了前端代码的某次代码评审,看到满屏的 return 错误码 简直就一种想打回去重做的冲动。JavaScript 作为发展了几年的高级语言,不存在 C++ 编写者的思想债务,使用者完全可以 throw new Error() 或者自己实现 Error 的子类用于封装错误码等异常信息,但还是将这样错误码使用的阴影运用到不合时宜的代码中。
就 JavaScript 这种语言来讲,我可以想到使用错误码的劣势就有:
1. asyncawait 语言关键字强依赖 return 和异常,Promise 类的静态方法也强依赖异常;
2. Error.prototype.stack 几乎所有浏览器 和 Node 环境可以非常明确的拿到异常发生的调用帧;
3. 异常被广泛运用到诸如 koa 等后端服务框架中,用于包括添加异常处理拦截器等。
甚至是某些全栈的评委在评论前端代码时依然评论某某函数没有检查错误码之类可笑荒唐的言论,这样的言论可以被任何一个前端开发非常轻易且不屑的反驳掉:我动态业务模型中并没有体现此处异常的处理,我为什么要检查这样的异常,异常发生之后后面都不会执行了。
接受异常往往不是从一种特定语言特性出发,而是从设计时就开始培养的,异常思维是和被研究的对象所强绑定的,而不只是一种编写代码的技术,如果能在整个研发团队(甚至是产品团队)中普及异常思维的思考方式,那么无疑在沟通、实现、拆解、职责分配中减少巨大的成本。
1.2 历史的局限性
通常情况下团队在某些时候遇到事故时会进行复盘,然后根据复盘最终的结论进行不二过的行动计划。
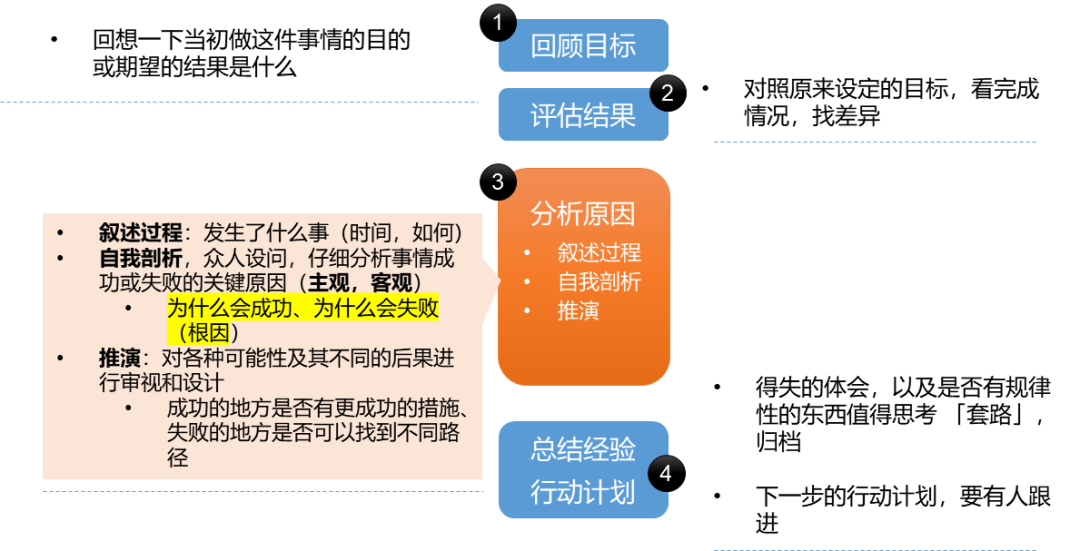
但往往复盘之后的行动计划被作为纲领来执行,未来时空转变的,甚至是故障的前置条件已经不存在了,还奉行所谓某次复盘的行动计划,往往是不那么合适的。
回想到自己曾经做过的一个项目复盘,在某个阶段上线了一段通过 libcurl 发包的代码,后来开启了协程就导致 libcurl 立即返回空数据包,经过一段时间的复盘,发现是 libcurl 和 libco 中有冲突,libco 会勾住 libcurl 发包行为导致 libcurl 收包异常,当前复盘的结论是在使用 libcurl 时要禁用协程切换。于是我对一个公共函数中的 libcurl 调用进行封装,在发包和收到时在代码中显式禁用协程切换(此方法不受服务器开启协程的影响),虽然可以暂时解决 libcurl 在多协程下收发包的问题,但副作用是很明显的——即在网络等待时没有进行协程切换,影响并发效率。
行动计划虽然总结了,但却有历史的局限性:
依赖 libco 没能正确在 libcurl 使用时处理网络收发包的场景;
使用会严重影响服务的并发性。
后来某些同事在尝试时,也使用了 libcurl 但并没有禁用协程也能成功,说并此次行动计划的先决条件已经不存在了,旧的行动计划由于时空环境的变化成了新的历史债务。
PS:可惜是现在目前最新版本的复盘规范中依然没有对不二过行动计划进行前置条件、时空环境做描述,即不存在一种失效机制让旧的行动计划废止或重新被审视。
试想一下,以前我们说不要用异常,不准用异常,也许在当时的历史局限下确实这么做是合理的:
客观条件上:
微信后端基础框架不支持拦截器,所以不能统一管理异常带来的风险;
C++11 还并没有在团队中大规模使用(
std::logic_error嵌套异常等都是在 C++11 之后才被规范的);优秀的第三方库还没有考虑到异常思想(JsonCpp 是在
1.x.y版本之后才引入异常,fmtlib还没有被推荐用于打日志,boost 会使用的团队还很少,inja模板引擎还没问世);
主观意愿上:
团队中并没有一群中坚力量可以制定规范的使用异常(甚至都没有代码委员会);
没有人力来评估异常带来的风险和收益;
团队人数太少,业务处于蛮荒地带,组织中大量存在 C with class 等不合格的开发者。
但时过境迁,客观条件和主观意愿都发现了非常明显的变化,这时候就应该打破历史的局限性在新的时空背景下对以前的规则翻旧账。
1.3 好复盘的重要性
某业务团队在 2017 年通过某次技术会议确定禁止在代码中使用异常,当时公司级别的代码委员会还没有成立。讨论禁用异常也只是几名代码写的比较多的同学发起的,当时的目的旨在规范一些存在的基本问题。本人尝试重新复盘一下当时的场景。
当时坚决反对使用异常的同事提出:
使用异常导致协程冲突,捕获到异常和抛出的不一致;
未捕获异常导致后端框架中的 worker 进程终止,重启 worker 进程漫长导致效率很差。
未捕获异常导致回滚逻辑尚未触发,影响数据一致性。
那么我们现在来重新研究一下当初的复盘。
1.3.1 抛出 C++ 异常代码静态分析
我们可以来研究一下抛出异常和捕获异常时,编译器和库分别做了什么事情。
将下列简单的异常代码反编译 :
#include <stdexcept>
void foo() {
if (rand() > 50) {
throw std::logic_error("bad");
}
}
int main(int argc, const char* argv[]) {
try {
foo();
} catch (const std::exception &ex) {
printf("%s", ex.what());
}
return 0;
}首先来看看 throw std::logic_error("bad") 是如何执行的。
; throw std::logic_error("bad");
mov edi, 16
; 从线程局部存储中分配异常对象的空间
call __cxa_allocate_exception
mov rbx, rax
mov esi, OFFSET FLAT:.LC0
mov rdi, rbx
; 在分配好的空间中调用异常的构造函数
call std::logic_error::logic_error(char const*) ;[complete object constructor]
mov edx, OFFSET FLAT:_ZNSt11logic_errorD1Ev
mov esi, OFFSET FLAT:_ZTISt11logic_error
mov rdi, rbx
; 一旦异常被创建,该函数就会被调用
call __cxa_throw
; 注意:此之后的代码是由 catch 之后程序调用
mov r12, rax
mov rdi, rbx
; 释放 __cxa_allocate_exception 分配的内存
call __cxa_free_exception
mov rax, r12
mov rdi, rax
; 调用 栈恢复 函数,即清理操作(析构块内的对象)
call _Unwind_Resume根据此处的汇编代码可以了解到抛出异常时需要调用两个函数 __cxa_allocate_exception 和 __cxa_throw
__cxa_allocate_exception:该函数从名字就能看出其主要功能__cxa_allocate_exception接受一个size_t类型的参数,然后为正在被抛出的异常分配足够的内存。但这其中的机制远比你想象的复杂:当一个异常被抛出时,会对栈进行一些操作,所以在这里进行分配可能不是个好主意。同时,在堆上分配内存可能也不是个好主意,因为我们可能需要在内存耗尽的情况下抛出异常。静态分配也不是一个好主意,因为我们需要这个操作是线程安全的(否则,如果两个线程同时抛出异常,那就麻烦了)。考虑到这些限制,大多数实现似乎都是在本地线程存储(堆)上分配内存,但如果内存耗尽,就会使用紧急存储(可能是静态的)。当然,我们不希望过于关心这些复杂的细节,所以我们可以选择只使用一个静态缓冲区5;分配好缓冲区后,就在这个缓冲区的内存中构造异常对象,所以考虑内存的安全性,就只需要考虑,分配好后这个异常对象的指针会不会被覆写,至于说这个指针指向的缓冲区是线程内存池还是静态区域,不重要,只是你 catch 住之后将期释放就行;
__cxa_throw:这是处理所有 throw 操作的函数,根据 ABI 参考,一旦异常被创建,__cxa_throw就会被调用。这个函数负责开始栈的展开。这个过程的一个重要效果是:__cxa_throw永远不应该返回。它要么将执行权委托给正确的 catch 块来处理异常,要么(默认情况下)调用std::terminate,但它绝不返回。
那么捕获异常实际会执行哪些代码呢?
.L12:
mov rdi, rax
; 用于处理是本地或外部异常
call __cxa_begin_catch
mov QWORD PTR [rbp-24], rax
mov rax, QWORD PTR [rbp-24]
mov rax, QWORD PTR [rax]
add rax, 16
mov rax, QWORD PTR [rax]
mov rdx, QWORD PTR [rbp-24]
mov rdi, rdx
call rax
mov rsi, rax
mov edi, OFFSET FLAT:.LC1
mov eax, 0
call printf
; 处理完异常进行清理操作
call __cxa_end_catch
jmp .L13
mov rbx, rax
call __cxa_end_catch
mov rax, rbx
mov rdi, rax
call _Unwind_Resume在执行 catch 块代码的时候,会先要调用 __cxa_begin_catch 函数对异常对象进行调整(计数器、放置到栈顶),执行完后会调用 __cxa_end_catch 函数进行异常对象的销毁。
其他有关异常更深层的实现,如 unwind 之类,如果有兴趣的请参考 C++ exceptions under the hood。
通过上述代码分析,可以知道,在异常抛出和捕获过程中。
异常对象是在线程安全的堆空间中分配的
__cxa_allocate_exception返回到 RAX;捕获到的对象调用
__cxa_begin_catch进行处理;最终通过
_Unwind_Resume回溯到__cxa_free_exception进行释放。
结论:对于目前 libco 使用了 stackful 的方式保存协程现场,在整个分配过程中都使用的是寄存器保存异常对象,同时异常对象的分配也是线程安全的,也就是说当回溯时就算发生了协程切换,保存的协程数据中也会将当前寄存器中的异常对象指针一并保存和恢复。使用协程,如果不是在代码中(例如抛出异常前写入一个全局变量的数据,然后在 catch 中对这个全局变量的数据进行修改),那么使用协程是数据安全的。
但如果是在 catch 中捕获了异常对象,由于此异常对象并不是在栈上保存的,如果在 catch 块的执行过程中发生了协程切换,虽然栈上的异常对象的指针还是原来的捕获时的异常对象,但不保证切换回来时异常对象已被清理。
1.3.1 抛异常时协程切换动态分析
为了验证我们的想法,可以写一个简单的程序来验证在捕获异常时,异常对象的是否也跟随上下文同时切换了。
#include <stdexcept>
#include <string_view>
#include "fmt/format.h"
#include "basic/colib/co_routine.h"
#include "basic/colib/co_routine_specific.h"
// 一个协程对象用于表示模拟协程执行时间
struct RoutineObject {
int index;
int sleep_ms;
void copy_from(const RoutineObject& other) {
index = other.index;
sleep_ms = other.sleep_ms;
}
inline string_view color() const {
switch (index) {
case 1:
return CC_GREEN;
case 2:
return CC_YELLOW;
default:
return CC_RESET;
}
}
template <typename S, typename... Args>
void Print(const S& fmt_str, Args&&... args) const {
fmt::print("{}[#{}] ", color(), index);
fmt::print(fmt_str, std::forward<Args>(args)...);
fmt::print("\n" CC_RESET);
}
};
// 一个协程变量(注意这个协程变量也可能不一定准确)
CO_ROUTINE_SPECIFIC(RoutineObject, routine_variable);
// 用于标记是否已经结束
static int kRunningRoutineCounter = 0;
// 在协程执行时抛出的异常,用于判断创建和析构的时机
class RoutineException : public logic_error {
public:
RoutineException(string text) : logic_error(text), text_(text) {
routine_variable->Print("Construct `RoutineException` [{}]: {}", fmt::ptr(this), text_);
}
virtual ~RoutineException() {
routine_variable->Print("Deconstruct `RoutineException` [{}]: {}", fmt::ptr(this), text_);
}
const string& text() const { return text_; }
private:
string text_;
};
// 抛出异常后,捕获异常后发生协程切换
void* CoRoutineTickSwitchInCaught(void* raw_arg) {
const RoutineObject& arg = *reinterpret_cast<const RoutineObject*>(raw_arg);
kRunningRoutineCounter++;
routine_variable->copy_from(arg);
arg.Print("Start!");
try {
throw RoutineException(fmt::format("From routine #{}", arg.index));
} catch (const RoutineException& ex) {
arg.Print("Caught exception: [{}] {}", fmt::ptr(&ex), ex.text());
arg.Print("Sleeping in caught {}ms ...", arg.sleep_ms);
arg.Print("Before context switch");
co_yield_timeout(arg.sleep_ms);
arg.Print("After context switch: [{}]", fmt::ptr(&ex));
arg.Print("Restore exception variable [{}] {}", fmt::ptr(&ex), ex.text());
}
arg.Print("Finish!");
kRunningRoutineCounter--;
return nullptr;
}
// 如果没有正在执行的协程就终止循环
int CoRoutineEventLoop(void*) {
if (kRunningRoutineCounter == 0) {
fmt::print(CC_RED "No routine stop loop.\n");
return -1;
}
return 0;
}
int main(int argc, char* argv[]) {
stCoRoutine_t* co = nullptr;
static RoutineObject routine_objects[] = {
{1, 300},
{2, 400},
};
// 使其可以使用 CO_ROUTINE_SPECIFIC 这个宏
CoRoutineSetSpecificCallback(co_getspecific, co_setspecific);
for (auto& arg : routine_objects) {
co_create(&co, nullptr, CoRoutineTickSwitchInCaught, &arg);
co_resume(co);
}
co_eventloop(co_get_epoll_ct(), CoRoutineEventLoop, nullptr);
return 0;
}上述代码在模拟了两个协程同时执行一段可切换的逻辑,
协程 1 在捕获到异常后,进行协程切换停止 300ms;
协程 2 在捕获异常后,协程切换,停止 400ms;
此时应该切换到协程 1 继续执行捕获后的逻辑。
另外一个思考点是,如果在抛出异常和捕获异常之间出现协程切换,会发生什么效果呢?我们把协程处理函数重写一下,使用 RAII 的思想在块超出作用域时进行协程切换。
// 抛出异常后,捕获异常前发生协程切换
void* CoRoutineTickSwitchInDefer(void* raw_arg) {
const RoutineObject& arg = *reinterpret_cast<const RoutineObject*>(raw_arg);
kRunningRoutineCounter++;
routine_variable->copy_from(arg);
arg.Print("Start!");
try {
BOOST_SCOPE_EXIT_ALL(&) {
arg.Print("Deferred sleeping {}ms ...", arg.sleep_ms);
arg.Print("Before context switch");
co_yield_timeout(arg.sleep_ms);
arg.Print("After context switch");
};
throw RoutineException(fmt::format("From routine #{}", arg.index));
} catch (const RoutineException& ex) {
arg.Print("Caught exception: [{}] {}", fmt::ptr(&ex), ex.text());
}
arg.Print("Finish!");
kRunningRoutineCounter--;
return nullptr;
}这段代码执行的结果如下:

由于之前我们分析的,异常的分配和捕获都是在栈中分配的变量。实际上我们可以认为协程切换是发生在 _Unwind_ 回溯函数时发生的,所以其实和是否使用异常关系不大(任何 return 语句都会触发当前帧的回溯 )。
1.3.2 那些协程内传递变量方式是安全的
好的复盘肯定是需要将所有的编写代码的情况都尽可能考虑进来的。通过上一节的分析我们设计了一个基准测试程序用于测试不同代码和不同传递方式,变量和预期值的试验,并通过单线程单协程、多线程单协程、单线程多协程和多线程多协程方式来测试其其对可轮转任务效率影响的情况。
变量值的传递方式
使用全局变量来传递,为了防止多线程冲突,我们会使用
std::mutex来保证多线程时的线程不冲突:
class ThreadSafeString {
public:
std::string load() const {
std::scoped_lock lock(unsafe_mutex_);
return unsafe_variable_;
}
void store(const string& val) {
std::scoped_lock lock(unsafe_mutex_);
unsafe_variable_ = val;
}
private:
std::string unsafe_variable_;
mutable std::mutex unsafe_mutex_;
};
static ThreadSafeString global_variable;使用线程局部存储来传递,C++ 11 新增关键字
thread_local来保证每个线程都是独立的变量:
static thread_local std::string thread_variable;使用协程变量来传递,libco 提供了一个线程+协程独立存储的方式来保证每个线程和协程中的变量都保持独立:
struct JobRoutineVariable {
public:
std::string value() const { return buffer_; }
void set_value(const std::string& val) { strncpy(buffer_, val.c_str(), sizeof(buffer_)); }
private:
char buffer_[64];
};
// CO_ROUTINE_SPECIFIC 用于定义一个协程变量,在每个协程切换后都会保持恢复独立
CO_ROUTINE_SPECIFIC(JobRoutineVariable, routine_variable);使用异常对象通过抛出异常和捕获异常来传递。
class JobException : public std::logic_error {
public:
explicit JobException(const std::string& content)
: std::logic_error("Raise exception: " + content), content_(content) {}
const std::string& content() const { return content_; }
private:
std::string content_;
};可能出现协程切换的场景
不会出现任何协程切换,使用 C++ 函数而不是 yield 函数来模拟一段时间的耗时;
class RaiseExceptionWithoutContextSwitch : public JobBase {
public:
void operator()() const {
std::string expected = GenerateRandomString();
std::string exception_variable;
try {
Level1(expected);
} catch (const JobException& ex) {
exception_variable = ex.content();
}
run_status.ReportMutation(
expected,
global_variable.load(),
thread_variable,
routine_variable->value(),
exception_variable);
}
private:
static void Level1(const std::string& expected) { Level2(expected); }
static void Level2(const std::string& expected) {
// 使用 C++ 函数模拟执行一段时间代码
std::this_thread::sleep_for(milliseconds(arg_job_cost_ms));
global_variable.store(expected);
thread_variable = expected;
routine_variable->set_value(expected);
throw JobException(expected);
}
};在抛出异常前进行协程切换,绝大多数场景就是如此的。比如发送一个 RPC 包,然后再判断其结果,根据结果的不同进行异常处理;
class RaiseExceptionBeforeSwitchContext : public JobBase {
public:
void operator()() const {
std::string expected = GenerateRandomString();
std::string exception_variable;
try {
Level1(expected);
} catch (const JobException& ex) {
exception_variable = ex.content();
}
run_status.ReportMutation(
expected,
global_variable.load(),
thread_variable,
routine_variable->value(),
exception_variable);
}
private:
static void Level1(const std::string& expected) { Level2(expected); }
static void Level2(const std::string& expected) {
// 注意:co_yield_timeout 只适用于协程场景,真实代码还需要判断当前执行的代码是否是在协程中
co_yield_timeout(arg_job_cost_ms);
global_variable.store(expected);
thread_variable = expected;
routine_variable->set_value(expected);
throw JobException(expected);
}
};逐帧回溯时进行协程切换,当使用 RAII 思想进行清理时才会出现此场景,如自定义智能指针释放时执行的析构代码等;
class SwitchContextInRewind : public JobBase {
public:
void operator()() const {
std::string expected = GenerateRandomString();
std::string exception_variable;
try {
Level1(expected);
} catch (const JobException& ex) {
// 当抛出异常后,回自动逐帧回溯 Level2 Level1 中块的变量
// 触发延迟执行 Level1 中的 BOOST_SCOPE_EXIT_ALL 块
exception_variable = ex.content();
}
run_status.ReportMutation(
expected,
global_variable.load(),
thread_variable,
routine_variable->value(),
exception_variable);
}
private:
static void Level1(const std::string& expected) {
BOOST_SCOPE_EXIT_ALL(&) { co_yield_timeout(arg_job_cost_ms); };
Level2(expected);
}
static void Level2(const std::string& expected) {
global_variable.store(expected);
thread_variable = expected;
routine_variable->set_value(expected);
throw JobException(expected);
}
};按常量引用捕获异常对象后,在异常对象使用后协程切换。
class SwitchContextAfterCaughtVariable : public JobBase {
public:
void operator()() const {
std::string expected = GenerateRandomString();
std::string exception_variable;
try {
Level1(expected);
} catch (const JobException& ex) {
// 捕获异常后立即保存其变量,避免被异常对象被无效化
exception_variable = ex.content();
co_yield_timeout(arg_job_cost_ms);
}
run_status.ReportMutation(
expected,
global_variable.load(),
thread_variable,
routine_variable->value(),
exception_variable);
}
private:
static void Level1(const std::string& expected) { Level2(expected); }
static void Level2(const std::string& expected) {
global_variable.store(expected);
thread_variable = expected;
routine_variable->set_value(expected);
throw JobException(expected);
}
};拷贝捕获异常对象后,在异常捕获块中进行协程切换。
class SwitchContextBeforeCopyCaughtVariable : public JobBase {
public:
void operator()() const {
std::string expected = GenerateRandomString();
std::string exception_variable;
try {
Level1(expected);
} catch (JobException ex) {
co_yield_timeout(arg_job_cost_ms);
// 由于是拷贝了一份新的异常对象
// 所以这里直接使用异常对象的副本也是安全的
exception_variable = ex.content();
}
run_status.ReportMutation(
expected,
global_variable.load(),
thread_variable,
routine_variable->value(),
exception_variable);
}
private:
static void Level1(const std::string& expected) { Level2(expected); }
static void Level2(const std::string& expected) {
global_variable.store(expected);
thread_variable = expected;
routine_variable->set_value(expected);
throw JobException(expected);
}
};根据上述我们编写了一个基准测试程序:用来测试 10 线程、10 进程执行 1000 个任务,每个任务模拟耗时 10ms。
根据上述结果我们可以得到一些简单的结论:
任何情况下,全局变量是不安全的,只要是使用了多协程或多线程,读取和写入不具备连续性;
在不使用多线程的情况下,理论上全局变量只要保证在抛出并且捕获之间保证不发生协程切换是安全的,但由于无法保证逐帧回溯时产生协程切换(例如某段代码来一个析构时 RPC 远程上报一把),请避免使用全局变量或线程本地变量;
如果协程切换依然是同一个协程函数,逐帧回溯、异常处理都会导致写到不同的全局变量或线程本地变量,请避免使用;
协程变量和通过异常对象传递数据,任何时候都是安全的(即传递的数据和拿到的数据是一样的)。但在动态分析一节中告诉我们,不要在捕获块代码的协程切换后再使用异常对象,因为它有可能已经被析构,不再有效。
1.3.4 重新分析当初的复盘结论
使用异常导致协程冲突,捕获到异常和抛出的不一致。
很有可能就是在编写代码时本身就使用了全局变量或线程本地存储变量,导致代码中的使用不一致,而由于没有仔细对代码的分析,很有可能就把锅盖到自己不熟悉的事物上,事实上之后就算不使用异常,也有很多因为使用了全局变量导致业务数据不一致的例子。
未捕获异常导致框架中的 worker 进程终止,重启 worker 进程漫长导致效率很差。
微信后端服务框架并未兜底异常其实也是一种思考方式;
2020 年底微信后端服务框架框架提供了服务函数拦截器,通过这个功能可以非常简单的添加业务异常处理拦截器;
早在 2015 年来自开放平台业务部的基础库中已经包括了
BEGIN_SERVICE和END_SERVICE宏,用于集中处理业务异常,也没有听说出现过未捕获异常导致 worker 进程终止,导致雪崩的告警;微信支付接入层框架自 2018 年起就在内部使用异常来处理框架中的代码,也在业务处理函数中可选开启了异常兜底选项,至今从未出现 worker 进程异常终止,或数据失效的问题;
未捕获异常导致回滚逻辑尚未触发,影响数据一致性。
如果根据现在的思考方式,一致性从来都不应该由某个片段的代码来决定,而应该由分布式事务等服务架构模式来确定;
与其在每个返回值判断之后再编写一段兜底逻辑,不如学习 RAII 的思想,保证对象在清理时对象的内在完整性;
其他语言也有类似
defer函数的功能,boost.scope_exit 也可以直接使用,编写可读性更高的代码是每个程序员的基本追求。
那么在 libco 的库的使用情况下,如何安全的使用异常呢?
只需要关心 catch 块中是否会发生协程切换,如果 catch 块中的代码确定不会发生协程切换就是安全的。最佳的做法是捕获到 catch 块只进行异常对象的数据简单处理,保持 catch 块和外层代码只发生简单的数据耦合;
如果 catch 块中发生来协程切换,那么在发生切换后,如果是按引用捕获的异常对象,那么这个对象可能不再安全,因为可能已经被析构掉了,所以尽量保证使用捕获的异常对象发生在协程切换之前;
如果一定要在 catch 块中协程发生切换后还要再使用被捕获的异常对象,请按值捕获(即深拷贝一个异常对象)这样在整个 catch 块中,这个已经被深拷贝的对象都一直是协程安全的;
可使用一些辅助函数,例如
UnifiedRpcController::SafeCall函数包裹住不安全的 lambda,调用完成后如果发生异常会把异常对象中的信息填充到controller中,这样业务代码就完全看不到try...catch...语句了。
1.3.5 行动计划
如果上层决定使用异常思维来应用到我们的代码编写中,可以参照以下行动计划:
思想上放开对异常就是恶魔的认识;
特别是对于某些代码评审者,不要认为使用异常就是恶鬼;
代码开发者在编写代码或库时,多参考业界新的 C++17 之后的库的方案,对于某大厂的代码参考时要保持思辨的头脑——到底是优秀实践、还是历史债务,又或是特定时空环境的特殊选择?
业务代码的设计是要和基础设施解耦的,犯不着为了某些陈旧的基础设施束缚了自己思考,况且基础设施也会升级的;
业务建模中增加异常思维,保证业务异常在设计中落地;
业务异常在动态建模时就应该落地,甚至是应该在先于模块划分时就将错误码申请好,这样才能保证每一个异常业务逻辑才能被监控,同时也保证了错误码不会被随意申请随意使用(你也不想一堆错误码都对应一种异常逻辑这样的恶心事发生吧);
对于编写代码时,根据业务建模,该你捕获的异常就处理,不该你处理的就交给上层框架来兜底——有了这样的思维模式,就会被迫在设计阶段考虑到所有的业务异常,而非将这些异常处理兜底处理杂糅在最终的实现代码中;
保证在代码中使用 RAII 思想,通过对象的析构来保证对象的完整性,而不是通过返回的错误码来操作兜底;
将面向对象的分析技术的高级思维模式属性、方法、事件(组件对象模型)等的学习和认识;
渐进的将异常代码运用到日常的服务中;
构建微信后端服务框架服务端拦截器用于兜底异常处理,此拦截器可以通过代码显式的完成 上报、收敛、控制码语义等兜底行为;
规范使用代码中异常的抛出,对于使用
throw语句抛出的业务异常需要显式的添加// NOLINT: (说明原因)标记并审核其必要性,其他的业务异常则统一使用UCLI_ASSURE_XX来保证一致性;可先拿不重要的业务来试点,从开发者获取反馈,并进一步提升异常库的代码质量,规范使用方式,避免踩坑。
02
结语
另外再次感谢曾经在公司内部论坛中吐槽过的员工,虽然当时本人也曾经有过简单的回答,但无奈并没有对整体进行结构化思考。也不知道当时是不是因为组织上甚至是公司间的复盘不够给力或不够发人深省,导致有很多有想法的同事产生了受委屈了这样的感受。
不知不觉写完此文章已经用了 1 个多月的时间,其中搜集了很多资料,也对很多疑难问题进行亲自的验证,还希望对大家有所帮助。
本文为《异常思辨录》系列最后一篇,
第一篇:《降本增笑的P0事故背后,是开猿节流引发的代码异常吗?》
第三篇:《异常≠错误,正如Bug≠事故,详解业务开发中的异常处理》
-End-
原创作者|陈明龙

你觉得代码到底该不该用异常?欢迎评论分享。我们将选取1则优质的评论,送出腾讯Q哥公仔1个(见下图)。1月23日中午12点开奖。

分享抽龙年红包封面!!转发本篇文章就能随机获得以下封面 1 个!限量50个,周一中午12点开奖!
参与方式:
1、分享本篇文章到朋友圈,并截图。
2、到腾讯云开发者公众号后台回复“0118”,经核验截图后,即可随机抽取以下 1 款红包封面!

📢📢欢迎加入腾讯云开发者社群,社群专享券、大咖交流圈、第一手活动通知、限量鹅厂周边等你来~

(长按图片立即扫码)




















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









