







论文作者:Mingzhen Sun,Weining Wang,Gen Li,Jiawei Liu,Jiahui Sun,Wanquan Feng,Shanshan Lao,SiYu Zhou,Qian He,Jing Liu
作者单位:CAS;Bytedance Inc.;UCAS
论文链接:http://arxiv.org/abs/2503.07418v1
内容简介:
1)方向:视频生成
2)应用:视频生成
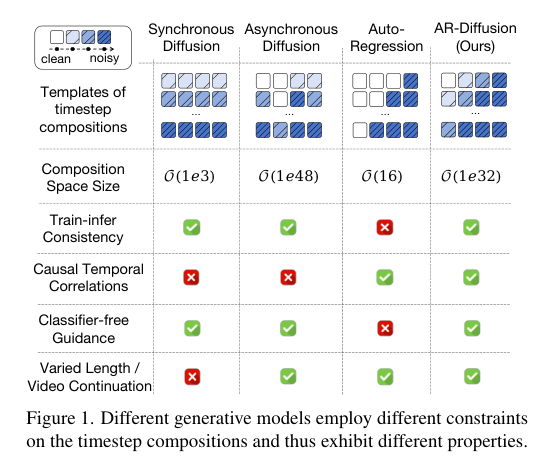
3)背景:现有的视频生成方法主要依赖于异步自回归模型或同步扩散模型。然而,异步自回归模型通常会在训练与推理阶段之间出现不一致,导致错误积累。而同步扩散模型则受到固定序列长度的限制,无法灵活地处理视频生成。
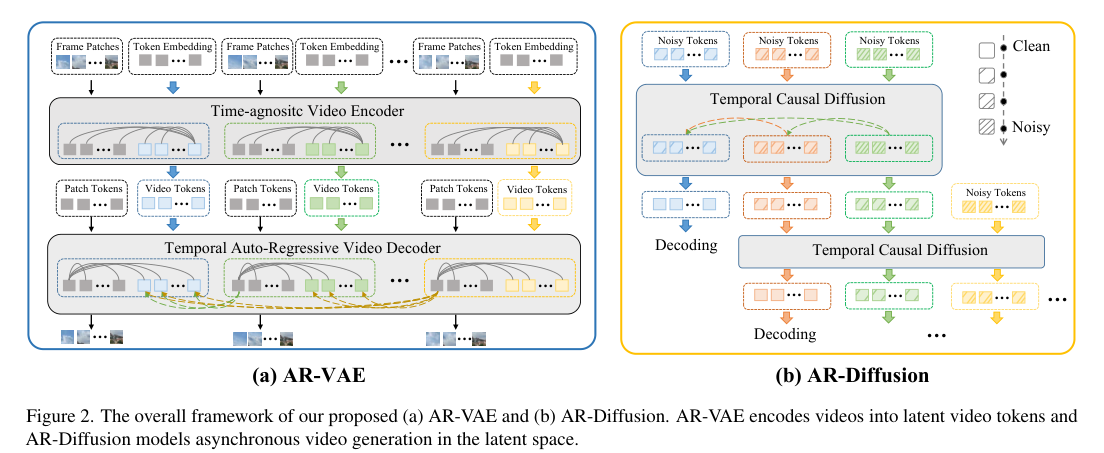
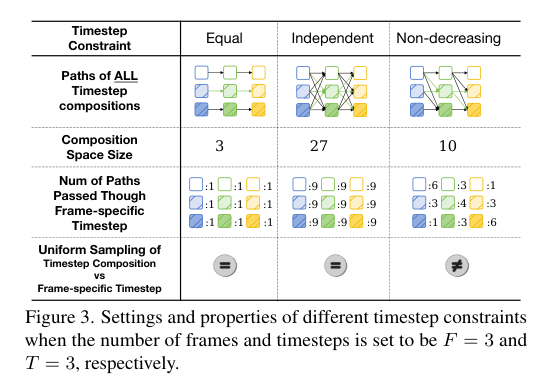
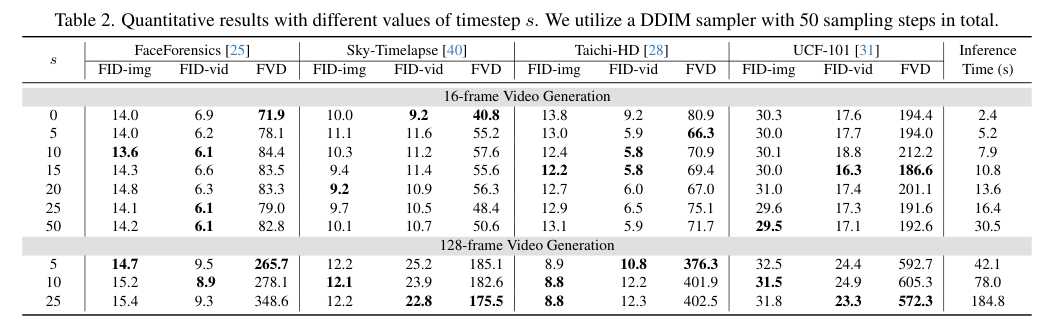
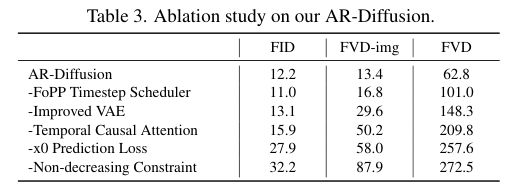
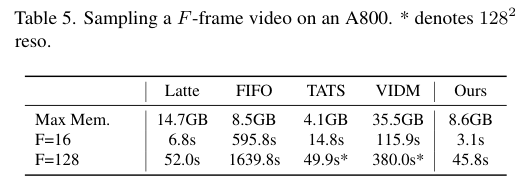
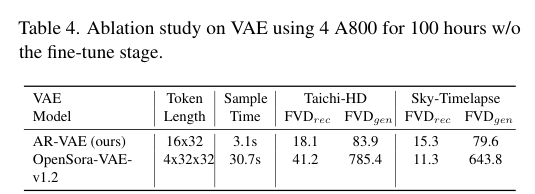
4)方法:为了解决这些问题,提出一种新的模型——自回归扩散(AR-Diffusion)。该模型结合了自回归模型和扩散模型的优势,支持灵活的异步视频生成。具体来说,在训练和推理过程中,采用扩散方法逐渐破坏视频帧,从而减少训练和推理阶段之间的差异。此外,受自回归生成的启发,模型对每帧的破坏步骤施加了非递减约束,确保早期帧比后续帧保持更清晰。结合时间因果注意力机制,该方法可以生成长度不固定的视频,同时保持时间上的一致性。模型还设计了两个专门的时间步调度器:FoPP调度器用于训练期间平衡时间步采样,AD调度器用于推理时支持灵活的时间步差异,支持同步和异步生成。
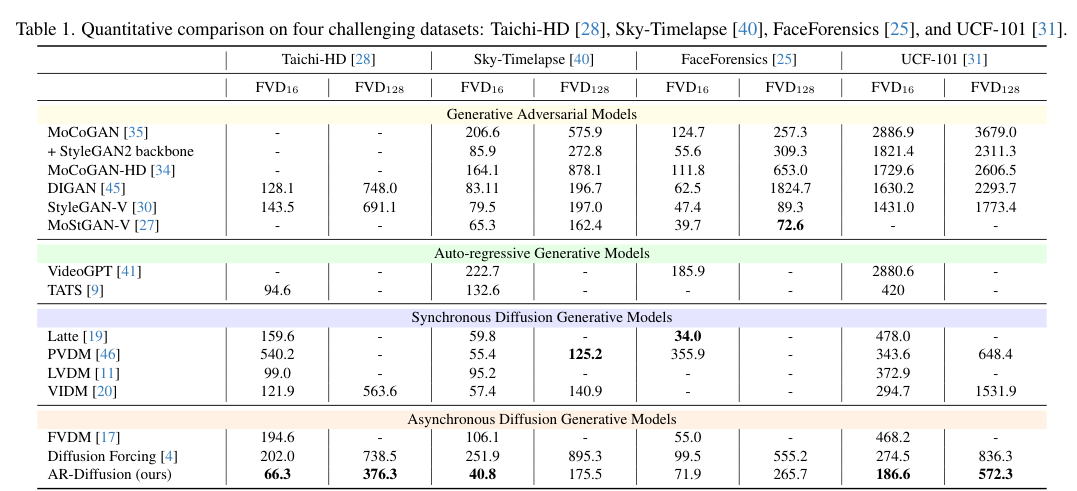
5)结果:通过大量实验验证,该方法在四个具有挑战性的基准测试中表现出色,取得了竞争力和最先进的结果,证明了其方法的优越性。


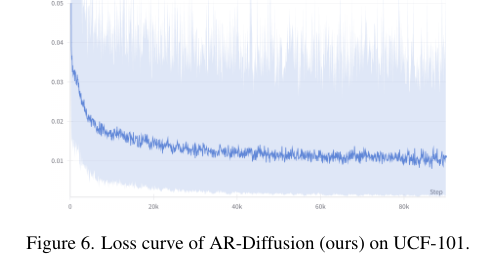
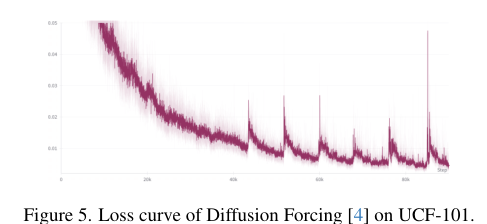

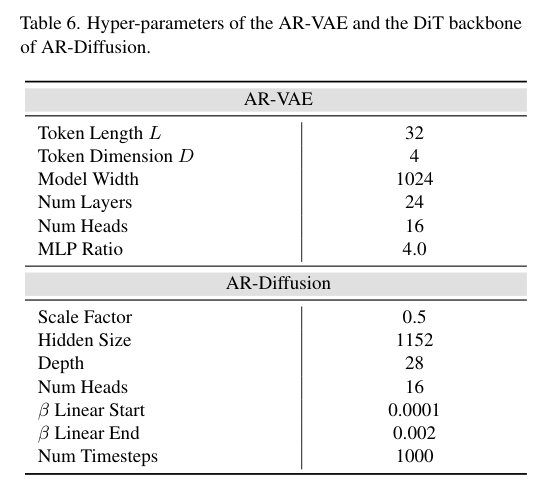




















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











