






目录
一、ROI原理介绍
在本节中,笔者引入了一种基于 Region of Interest(ROI) 的改进方法。首先介绍 ROI 的基本原理,然后对引入 ROI 之后的单隐藏层卷积神经网络进行训练与测试,最后将其与上一节的模型进行对比,得出了改进之后的模型可以大幅缩短训练时长,但准确率却会略有下降的结论。
上一节的文章见下方链接:
(神经网络)MNIST手写体数字识别MATLAB完整代码-CSDN博客
1.1 基本原理
“Region of Interest”(ROI)是图像处理和计算机视觉领域的术语,指的是在一幅 图像或视频帧中选定的特定区域,这个区域包含了研究、分析或处理的主要兴趣区域。ROI 用于限定分析的范围,以减少计算复杂性,提高处理效率,并集中注意力在感兴趣 的图像部分上。
为帮助进一步理解 ROI 机制,笔者借助图19所示进行讲解。原图为一只猫的图片,仔细观察这张图可以发现真正对我们识别有帮助的只集中于中间一部分,而周围的空白对我们的识别不会起到任何帮助,因此我们可以采用将图片切割的方式减小输入图片的维度。图19右侧的图即为切割后的图,这样图的维度会有显著的降低,在不损失图片主要信息的情况下可以提高训练的准确度、降低计算的复杂度、降低训练所需的时间。



1.2 完整代码
%softmax激活函数
function r = softmax(x)
S = sum(exp(x));
r = zeros(length(x), 1);
for i = 1:length(x)
r(i) = exp(x(i)) / S;
end
end%基于ROI机制的单隐藏层神经网络(main函数)
%初始化第一个卷积层的连接权重
W1 = randn(9, 9, 20);
%设置学习率
alpha = 0.01;
% 设置文件夹路径
mainPath = 'MINIST_trian/';
%初始化分类网络的第一个隐层的权重参数
W2 = (2 * rand(100, 720) - 1) / 20;
%初始化输出层的连接权重
W3 = (2 * rand(10, 100) - 1) / 10;
%设置迭代次数
n = 1;
%初始化样本标签数据
Tab = zeros(60000, 1);
%先对每个样本进行标记
for i = 0:9
%依次遍历MINIST_train(训练集)文件夹下的每一个子文件夹,每一个子文件夹中包含相同的数字
trainfolderpath = strcat(mainPath, num2str(i));
% 获取文件夹中的所有图像文件
trainimageFiles = dir(fullfile(trainfolderpath, '*.jpg')); % 可以更改文件扩展名以匹配你的图像格式
% 循环读取每个图像
for j = 1:length(trainimageFiles)
% 假设imageFiles(j).name包含文件名,例如"example.jpg"
fullFileName = trainimageFiles(j).name;
% 使用fileparts函数来分析文件名
[~, baseFileName, ~] = fileparts(fullFileName);
%获得图片的序号
NUM = str2num(baseFileName);
Tab(NUM) = i;
end
end
% 开始计时
tic;
% 设置文件夹路径
mainPath_noclass = 'MINIST_trian_withouclass/';
%保存交叉熵
error = zeros(60000, 1);
%进行训练
for epochs = 1:n
%依次遍历MINIST_train(训练集)文件夹下的每一个子文件夹,每一个子文件夹中包含相同的数字
folderpath = mainPath_noclass;
%获取文件夹中的所有图像文件
imageFiles = dir(fullfile(folderpath, '*.jpg')); % 可以更改文件扩展名以匹配你的图像格式
% 循环读取每个图像
for j = 1:length(imageFiles)
% 构建完整的文件路径
tab = Tab(j);
%设置目标输出
D = zeros(10, 1);
D(tab+1) = 1;
%获取要读取的图片的地址
imagePath = strcat(folderpath, num2str(j));
imagePath = strcat(imagePath, '.jpg');
%输出正在处理的图像和训练进度
fprintf('训练进度为%f%%\n', j/600);
disp(imagePath);
% 使用 imread 读取图像
imageData = imread(imagePath);
%标记ROI区域
imageData = imageData(5:24, 5:24);
%对图像进行归一化操作
imageData = round(imageData / 255);
%进行卷积操作(卷积核的大小为9*9*20)
img_conv1 = zeros(12, 12, 20);
%第一层循环为卷积核编号的循环
for k = 1:20
%第二层循环是图像矩阵的行循环
img_conv1(:, :, k) = filter2(W1(:, :, k), imageData, 'valid');
end
%进行激活操作,使用的是ReLU激活函数
img_act = max(0, img_conv1);
%进行池化操作,我们采用平均池化的方式,卷积核的大小为2*2
img_pool = (img_act(1:2:end, 1:2:end, :) + img_act(2:2:end, 2:2:end, :) + img_act(1:2:end, 2:2:end, :) +img_act(2:2:end, 1:2:end, :)) / 4;
%将img_pool转换成一个列向量(720*1)
img_input = reshape(img_pool, [], 1);
%计算第一个隐层的输出
v1 = W2 * img_input;
y1 = max(0, v1);
%计算输出层的输出
v2 = W3 * y1;
y2 = softmax(v2);
% 计算交叉熵函数
error(j) = sum(- D .* log(y2) - (1 - D) .* log(1 - y2));
%计算输出层的delta
e2 = D - y2;
delta2 = e2;
%计算第一层隐藏层的delta1
e1 = W3' * delta2;
delta1= (y1 > 0) .* e1;
%计算输入层(reshape层)的e
e = W2' * delta1;
%将输入层的误差进行reshape,以便于误差进一步反向传播穿过池化层和卷积层
E2 = reshape(e, size(img_pool));
%将池化层的误差传播到卷积层
E1 = zeros(size(img_act));
E2_4 = E2 / 4;
E1(1:2:end, 1:2:end, :) = E2_4;
E1(1:2:end, 2:2:end, :) = E2_4;
E1(2:2:end, 1:2:end, :) = E2_4;
E1(2:2:end, 2:2:end, :) = E2_4;
delta = (img_act > 0) .* E1;
dW1 = zeros(9, 9, 20);
for k = 1:20
dW1(:, :, k) = alpha * (filter2(delta(:, :, k), imageData, 'valid'));
end
%更改权重
W1 = W1 + dW1;
W2 = W2 + alpha * delta1 * img_input';
W3 = W3 + alpha * delta2 * y1';
end
end
% 停止计时
elapsedTime = toc;
% 打印执行时间
fprintf('训练时长为:%.4f 秒\n', elapsedTime);
%训练结束的信号
disp('训练结束,等待测试...');
%测试代码
testPath = 'MINIST_test/';
l = 1;
%分类真确的样本个数的计数
acc = 0;
p = 1;
for i = 0:9
%依次遍历MINIST_train(训练集)文件夹下的每一个子文件夹,每一个子文件夹中包含相同的数字
testfolderpath = strcat(testPath, num2str(i));
% 获取文件夹中的所有图像文件
testimageFiles = dir(fullfile(testfolderpath, '*.jpg')); % 可以更改文件扩展名以匹配你的图像格式
% 循环读取每个图像
for j = 1:length(testimageFiles)
% 构建完整的文件路径
imagePath = fullfile(testfolderpath, testimageFiles(j).name);
% 使用 imread 读取图像
imageData = imread(imagePath);
%标记ROI区域
imageData = imageData(5:24, 5:24);
%对图像进行归一化操作
imageData = round(imageData / 255);
%进行卷积操作(卷积核的大小为9*9*20)
img_conv1 = zeros(12, 12, 20);
%第一层循环为卷积核编号的循环
for k = 1:20
%第二层循环是图像矩阵的行循环
img_conv1(:, :, k) = filter2(W1(:, :, k), imageData, 'valid');
end
%进行激活操作,使用的是ReLU激活函数
img_act = max(0, img_conv1);
%进行池化操作,我们采用平均池化的方式,卷积核的大小为2*2
img_pool = (img_act(1:2:end, 1:2:end, :) + img_act(2:2:end, 2:2:end, :) + img_act(1:2:end, 2:2:end, :) +img_act(2:2:end, 1:2:end, :)) / 4;
%将img_pool转换成一个列向量(2000*1)
img_input = reshape(img_pool, [], 1);
%计算第一个隐层的输出
v1 = W2 * img_input;
y1 = max(0, v1);
%计算输出层的输出
v2 = W3 * y1;
y2 = softmax(v2);
[~, z] = max(y2);
acc = acc + ((z-1) == i);
l = l + 1;
if (z-1) ~= i
[~, baseFileName, ~] = fileparts(testimageFiles(j).name);
order(p) = str2num(baseFileName);
x(p) = z - 1;
p = p + 1;
end
end
end
fprintf('准确率为%f\n', acc/(l-1));
plot(1:60000, error);
xlabel('训练的图片数');
ylabel('交叉熵');
title('交叉熵函数');1.3 输出结果
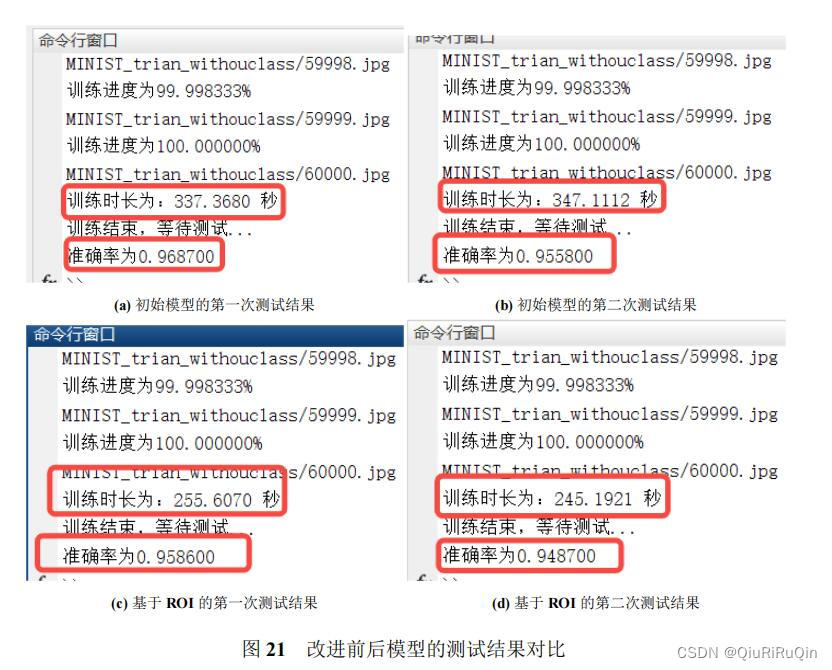
图21所示为初始模型与基于ROI机制的模型的结果对比。相比于初始模型,基于ROI机制的模型,通过降低输入图像的维度,确实做到了显著降低训练时长的效果。但就在测试集上的准确率来说,却略有下降。
为了进一步提高模型的准确率,我们可以通过加深网络层数的方式,增加特征提取的数量。
二、深层神经网络
2.1 深层与浅层神经网络
深层神经网络(Deep Neural Network,DNN)和浅层神经网络(Shallow Neural Network)是两种神经网络的术语,它们主要区别在于神经网络的层数。
(1)浅层神经网络:
浅层神经网络通常指的是只有一层或者很少层隐含层的神经网络。这样的网络相对较简单,参数较少,通常包含输入层、一个或者多个隐含层,以及输出层。浅层神经网络在一些简单的任务上表现得很好,但对于复杂的问题,可能无法捕捉到数据中的复杂模式。
(2)深层神经网络
深层神经网络则包含更多的隐含层,通常包括多个深度的隐含层。深层神经网络的优势在于它们能够学习更复杂的表示和特征层级,使得它们更适用于处理大规模、高维度的数据以及复杂的任务。
2.2 深层神经网络的有点与缺点
深层神经网络相对于浅层神经网络具有一些优点和缺点,这些优缺点在不同的任务和场景下会有不同的表现。
2.2.1 深层神经网络的优点
(1)更强大的表示学习能力: 深层神经网络能够学习更复杂、更抽象的特征表示,通过层层堆叠非线性变换来捕捉数据中的复杂模式。
(2)适用于大规模数据: 当有大量数据可用时,深层神经网络通常能够更好地利用这些数据,从而提高性能。
(3)处理高维度输入: 对于高维度输入数据(如图像、文本等),深层神经网络能够更好地处理和提取关键特征。
2.2.2 深层神经网络的缺点
(1)需要更多的数据: 深层神经网络通常需要大量的数据来训练,否则容易发生过拟合。
(2)计算资源需求高: 训练深层神经网络需要大量的计算资源,特别是在深层网络中,参数的数量迅速增加,导致训练过程需要更多的时间和计算能力。
(3)调参困难: 深层神经网络的调参相对更加困难,需要谨慎选择学习率、正则化方法等超参数,以及网络的结构。而且深层神经网络模型中,很容易遇到梯度消失的情况,一旦误差无法向后传播到,权重系数也就无法更改,自然无法达到训练的效果了。
总的来说,深层神经网络具有更强大的表示学习能力,但也需要更多的数据和计算资源。浅层神经网络则更容易理解和训练,适用于一些较简单的任务。选择使用深层还是浅层神经网络通常取决于任务的复杂性、数据的特性以及可用的计算资源
三、双隐藏层神经网络模型的应用
3.1 网络结构介绍
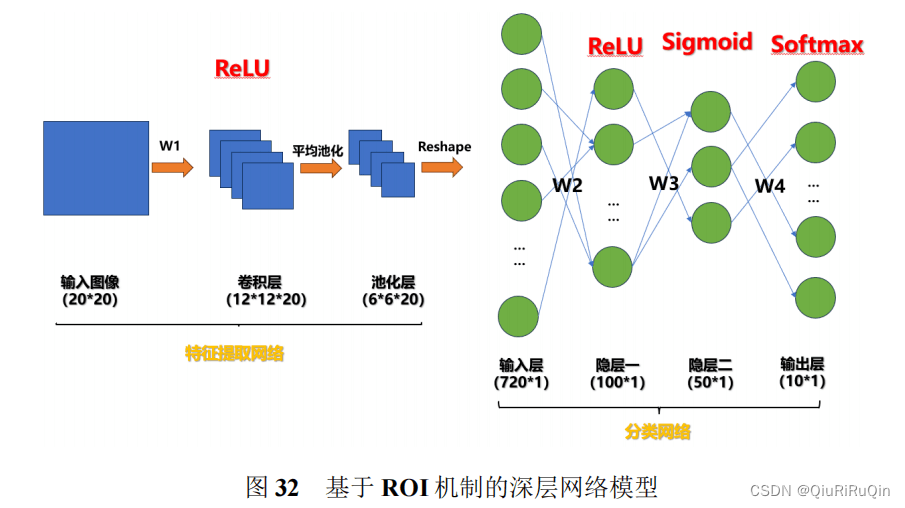
3.2 结果展示
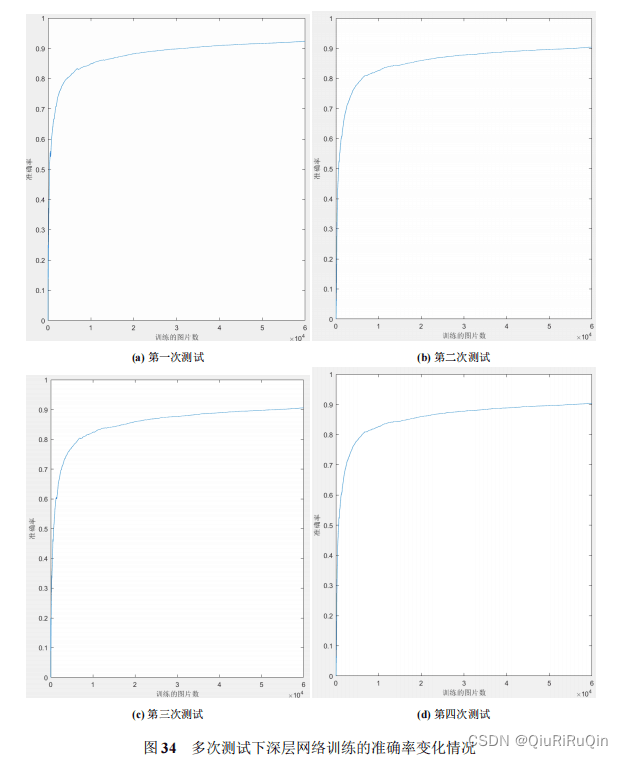
图33所示为多次训练深层神经网络对应的损失函数变化情况。可以看到,损失函数均未收敛。图34所示为多次训练深层神经网络对应的准确率变化情况,可以观察到最终训练过程中模型的准确率均达到 90% 以上。
相比于基础模型,基于 ROI 机制的“深层”神经网络可以大幅缩短训练时间,并保持一个较高的准确率;相比于第一节的单隐藏层模型,这个模型的准确率也有了些许提升 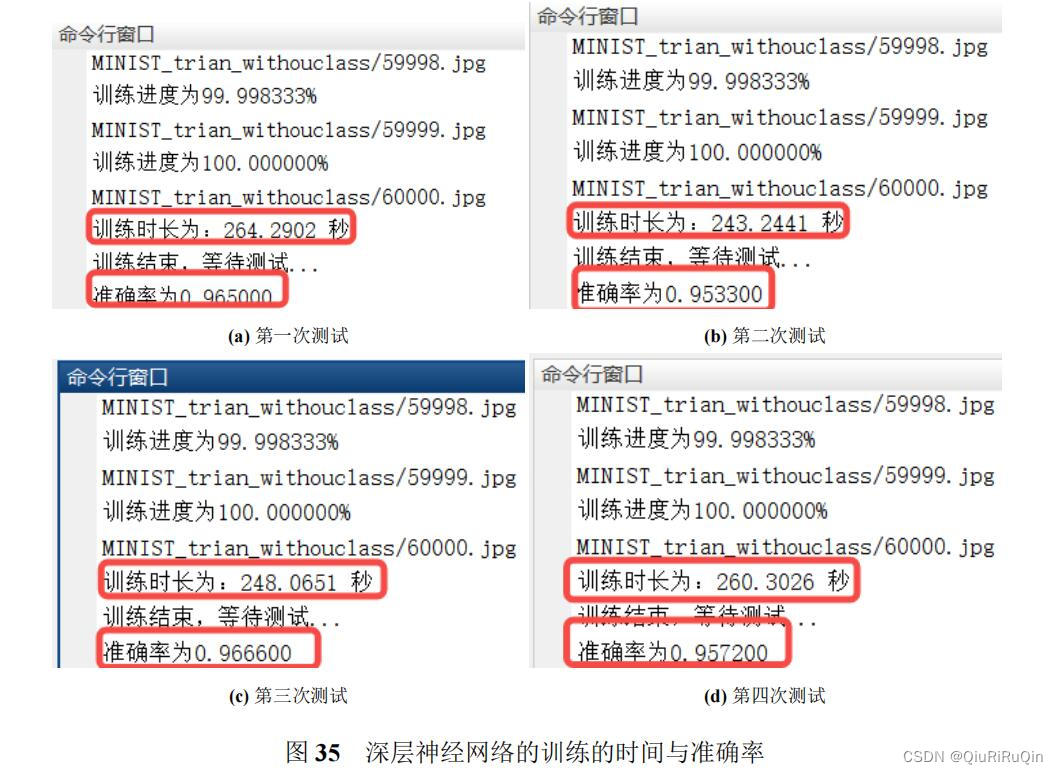
3.3 完整代码
%softmax激活函数
function r = softmax(x)
S = sum(exp(x));
r = zeros(length(x), 1);
for i = 1:length(x)
r(i) = exp(x(i)) / S;
end
end%sigmoid函数
function r = sigmoid(x)
r = 1 ./ (1 + exp(-x));
end%DeepNet主函数
%初始化第一个卷积层的连接权重
W1 = randn(9, 9, 20);
%设置学习率
alpha = 0.01;
% 设置文件夹路径
mainPath = 'MINIST_trian/';
%初始化分类网络的第一个隐层的权重参数
W2 = (2 * rand(100, 720) - 1) / 20;
%初始化分类网络的第二个隐层的权重参数
W4 = (2 * rand(50, 100) - 1) / 20;
%初始化输出层的连接权重
W3 = (2 * rand(10, 50) - 1) / 10;
%设置迭代次数
n = 1;
%初始化样本标签数据
Tab = zeros(60000, 1);
%先对每个样本进行标记
for i = 0:9
%依次遍历MINIST_train(训练集)文件夹下的每一个子文件夹,每一个子文件夹中包含相同的数字
trainfolderpath = strcat(mainPath, num2str(i));
% 获取文件夹中的所有图像文件
trainimageFiles = dir(fullfile(trainfolderpath, '*.jpg')); % 可以更改文件扩展名以匹配你的图像格式
% 循环读取每个图像
for j = 1:length(trainimageFiles)
% 假设imageFiles(j).name包含文件名,例如"example.jpg"
fullFileName = trainimageFiles(j).name;
% 使用fileparts函数来分析文件名
[~, baseFileName, ~] = fileparts(fullFileName);
%获得图片的序号
NUM = str2num(baseFileName);
Tab(NUM) = i;
end
end
% 开始计时
tic;
% 设置文件夹路径
mainPath_noclass = 'MINIST_trian_withouclass/';
%保存交叉熵
error = zeros(60000, 1);
%进行训练
for epochs = 1:n
%依次遍历MINIST_train(训练集)文件夹下的每一个子文件夹,每一个子文件夹中包含相同的数字
folderpath = mainPath_noclass;
%获取文件夹中的所有图像文件
imageFiles = dir(fullfile(folderpath, '*.jpg')); % 可以更改文件扩展名以匹配你的图像格式
% 循环读取每个图像
for j = 1:length(imageFiles)
% 构建完整的文件路径
tab = Tab(j);
%设置目标输出
D = zeros(10, 1);
D(tab+1) = 1;
%获取要读取的图片的地址
imagePath = strcat(folderpath, num2str(j));
imagePath = strcat(imagePath, '.jpg');
%输出正在处理的图像和训练进度
fprintf('训练进度为%f%%\n', j/600);
disp(imagePath);
% 使用 imread 读取图像
imageData = imread(imagePath);
%标记ROI区域
imageData = imageData(5:24, 5:24);
%对图像进行归一化操作
imageData = round(imageData / 255);
%进行卷积操作(卷积核的大小为9*9*20)
img_conv1 = zeros(12, 12, 20);
%第一层循环为卷积核编号的循环
for k = 1:20
%第二层循环是图像矩阵的行循环
img_conv1(:, :, k) = filter2(W1(:, :, k), imageData, 'valid');
end
%进行激活操作,使用的是ReLU激活函数
img_act = max(0, img_conv1);
%进行池化操作,我们采用平均池化的方式,卷积核的大小为2*2
img_pool = (img_act(1:2:end, 1:2:end, :) + img_act(2:2:end, 2:2:end, :) + img_act(1:2:end, 2:2:end, :) +img_act(2:2:end, 1:2:end, :)) / 4;
%将img_pool转换成一个列向量(720*1)
img_input = reshape(img_pool, [], 1);
%计算第一个隐层的输出
v1 = W2 * img_input;
y1 = max(0, v1);
%计算第二个隐藏层的输出
v2 = W4 * y1;
y2 = sigmoid(v2);
%计算输出层的输出
v3 = W3 * y2;
y3 = softmax(v3);
% 计算交叉熵函数
error(j) = sum(- D .* log(y3) - (1 - D) .* log(1 - y3));
%计算输出层的delta
e3 = D - y3;
delta3 = e3;
%计算第一层隐藏层的delta1
e2 = W3' * delta3;
delta2= y2 .* (1 - y2) .* e2;
e1 = W4' * delta2;
delta1 = (y1 > 0) .* e1;
%计算输入层(reshape层)的e
e = W2' * delta1;
%将输入层的误差进行reshape,以便于误差进一步反向传播穿过池化层和卷积层
E2 = reshape(e, size(img_pool));
%将池化层的误差传播到卷积层
E1 = zeros(size(img_act));
E2_4 = E2 / 4;
E1(1:2:end, 1:2:end, :) = E2_4;
E1(1:2:end, 2:2:end, :) = E2_4;
E1(2:2:end, 1:2:end, :) = E2_4;
E1(2:2:end, 2:2:end, :) = E2_4;
delta = (img_act > 0) .* E1;
dW1 = zeros(9, 9, 20);
for k = 1:20
dW1(:, :, k) = alpha * (filter2(delta(:, :, k), imageData, 'valid'));
end
%更改权重
W1 = W1 + dW1;
W2 = W2 + alpha * delta1 * img_input';
W4 = W4 + alpha * delta2 * y1';
W3 = W3 + alpha * delta3 * y2';
end
end
% 停止计时
elapsedTime = toc;
% 打印执行时间
fprintf('训练时长为:%.4f 秒\n', elapsedTime);
%训练结束的信号
disp('训练结束,等待测试...');
%测试代码
testPath = 'MINIST_test/';
l = 1;
%分类真确的样本个数的计数
acc = 0;
p = 1;
for i = 0:9
%依次遍历MINIST_train(训练集)文件夹下的每一个子文件夹,每一个子文件夹中包含相同的数字
testfolderpath = strcat(testPath, num2str(i));
% 获取文件夹中的所有图像文件
testimageFiles = dir(fullfile(testfolderpath, '*.jpg')); % 可以更改文件扩展名以匹配你的图像格式
% 循环读取每个图像
for j = 1:length(testimageFiles)
% 构建完整的文件路径
imagePath = fullfile(testfolderpath, testimageFiles(j).name);
% 使用 imread 读取图像
imageData = imread(imagePath);
%标记ROI区域
imageData = imageData(5:24, 5:24);
%对图像进行归一化操作
imageData = round(imageData / 255);
%进行卷积操作(卷积核的大小为9*9*20)
img_conv1 = zeros(12, 12, 20);
%第一层循环为卷积核编号的循环
for k = 1:20
%第二层循环是图像矩阵的行循环
img_conv1(:, :, k) = filter2(W1(:, :, k), imageData, 'valid');
end
%进行激活操作,使用的是ReLU激活函数
img_act = max(0, img_conv1);
%进行池化操作,我们采用平均池化的方式,卷积核的大小为2*2
img_pool = (img_act(1:2:end, 1:2:end, :) + img_act(2:2:end, 2:2:end, :) + img_act(1:2:end, 2:2:end, :) +img_act(2:2:end, 1:2:end, :)) / 4;
%将img_pool转换成一个列向量(2000*1)
img_input = reshape(img_pool, [], 1);
%计算第一个隐层的输出
v1 = W2 * img_input;
y1 = max(0, v1);
%计算输出层的输出
v2 = W4 * y1;
y2 = sigmoid(v2);
v3 = W3 * y2;
y3 = softmax(v3);
[~, z] = max(y3);
acc = acc + ((z-1) == i);
l = l + 1;
if (z-1) ~= i
[~, baseFileName, ~] = fileparts(testimageFiles(j).name);
order(p) = str2num(baseFileName);
x(p) = z - 1;
p = p + 1;
end
end
end
fprintf('准确率为%f\n', acc/(l-1));
plot(1:60000, error);
xlabel('训练的图片数');
ylabel('交叉熵');
title('交叉熵函数');感谢您的关注、点赞与支持!!!这是我继续更新的最大动力!














 1566
1566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









