






一、相关文件下载地址
二、虚拟机基础配置
1.配置模版虚拟机
配置模版机这里就不单独说了,如果需要的可以点击下方链接:
配置JDK也不说了,需要的也可以点击下方链接查看一下:
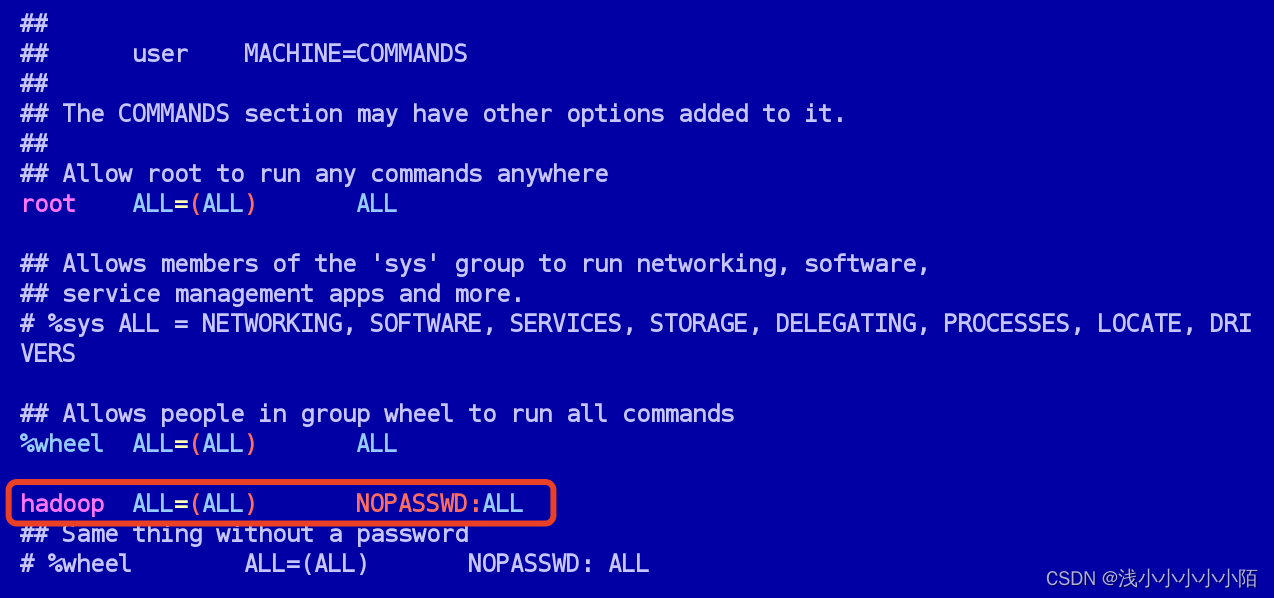
#给普通用户提高权限
sudo vim /etc/sudoers
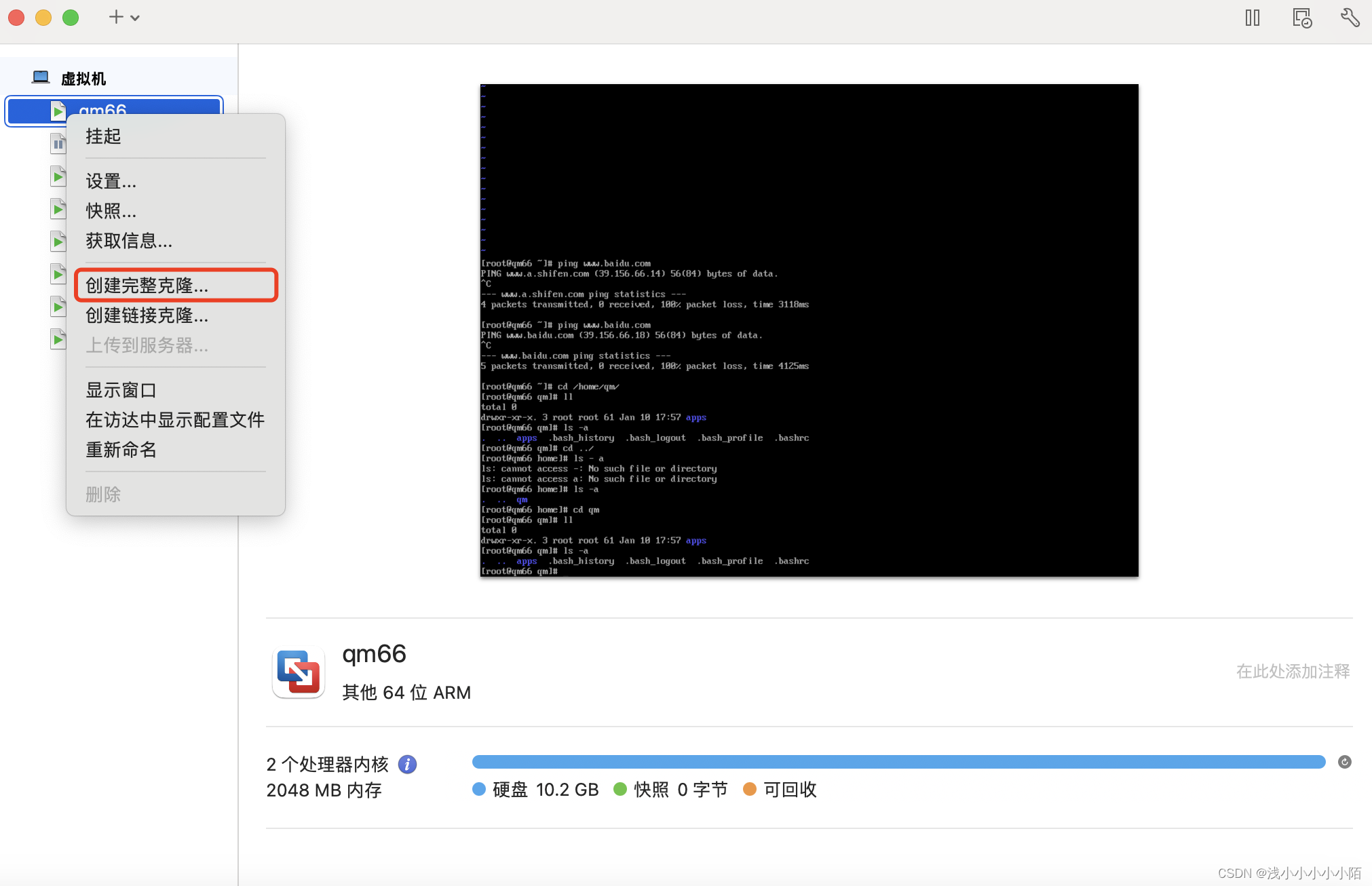
2.克隆虚拟机
3.更改克隆虚拟机配置
#按照模版虚拟机配置教程,更改克隆出来的两台虚拟机的配置
#修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens160
#域名映射
vim /etc/hosts
#主机名称
vim /etc/hostname
#我这里的3台虚拟机主机名为hadoop01、hadoop02、hadoop03,普通用户都叫hadoop4. 配置SSH免密登录(普通用户)
#三台虚拟机都输入这个命令,之后敲三次回车
ssh-keygen #生成公钥和私钥
#在第一台机器执行
ssh-copy-id hadoop01 #将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop02 #将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop03 #将公钥拷贝到要免密登录的目标机器上
#在第二台机器执行
ssh-copy-id hadoop01 #将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop02 #将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop03 #将公钥拷贝到要免密登录的目标机器上
#在第三台机器执行
ssh-copy-id hadoop01 #将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop02 #将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop03 #将公钥拷贝到要免密登录的目标机器上5.关闭防火墙
systemctl stop firewalld三、安装Hadoop
1.在hadoop01下Hadoop文件存放到software中

2.将Hadoop文件解压到module中
tar -xvf hadoop-arrch-3.2.1.tar.gz -C /opt/module/四、修改Hadoop配置文件
1.修改hadoop-env.sh配置文件
#进入Hadoop目录修改etc/hadoop下的文件
cd /opt/module/hadoop-3.2.1/etc/hadoop/
vim hadoop-env.s #修改hadoop-env.s配置
#进入hadoop-env.s配置JDK的路径
export JAVA_HOME=/opt/module/jdk1.8.0_3912.修改core-site.xml配置文件
vim core-site.xml #修改core-site.xml配置
#将下面的代码添加到<configuration></configuration>中间:
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoopData/temp</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 qm -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
3.修改hdfs-site.xml配置文件
vim hdfs-site.xml #修改hdfs-site.xml配置
#将下面的代码添加到<configuration></configuration>中间:
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
4.修改mapred-site.xml配置文件
vim mapred-site.xml #修改mapred-site.xml配置
#将下面的代码添加到<configuration></configuration>中间:
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.2.1</value>
</property>
5.修改yarn-site.xml配置文件
vim yarn-site.xml #修改yarn-site.xml配置
#将下面的代码添加到<configuration></configuration>中间:
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
6.修改workers配置文件
vim workers #修改workers配置
#将内容修改为:
hadoop01
hadoop02
hadoop02五、将Hadoop文件分发到从节点
#分别分发到从节点hadoop02和hadoop03上,使用命令:
#要注意操作的目录
scp -r /opt/module/hadoop-3.2.1 hadoop02:$PWD #分发到hadoop02
scp -r /opt/module/hadoop-3.2.1 hadoop03:$PWD #分发到hadoop03六、配置Hadoop系统环境变量
1.记录Hadoop路径
cd /opt/module/hadoop-3.2.1/ && pwd![]()
2.配置环境变量
#需要在三个节点上都进行配置,使用命令:
sudo vim /etc/profile #编辑配置文件在文件最后添加如下代码:
# 配置Hadoop-3.2.1
export HADOOP_HOME=/opt/module/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:wq保存并退出vim编辑器
3.生效配置
source /etc/profile
七、启动Hadoop集群
1.初始化文件系统
#在hadoop01节点执行命令:
hdfs namenode -format2.启动hadoop服务
#在hadoop01、hadoop02、hadoop03节点执行命令:
start-all.sh3.启动JobHistory
#在hadoop01节点执行命令:
mapred --daemon start historyserver4.查看进程是否启动
在hadoop01的终端执行jps命令,在打印结果中会看到5个进程,分别是JobHistoryServer、Jps、NameNode、NodeManager、DataNode,如果出现了这5个进程表示主节点进程启动成功。如下图所示:

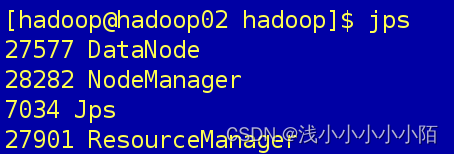
在hadoop02的终端执行jps命令,在打印结果中会看到4个进程,分别是DataNode、NodeManager、Jps、ResourceManager,如果出现了这4个进程表示主节点进程启动成功。如下图所示:
在hadoop03的终端执行jps命令,在打印结果中会看到4个进程,分别是DataNode、SecondaryNameNode、Jps、NodeManager,如果出现了这4个进程表示主节点进程启动成功。如下图所示:

5.Web端查看HDFS的NameNode
浏览器输入:http://hadoop01的IP:9870
查看HDFS上存储的数据信息
6.Web端查看YARN的ResourceManager
浏览器输入:http://hadoop02的IP:8088
查看YARN上运行的Job信息
7.Web端查看JobHistory
浏览器输入:http://hadoop01的IP:19888/jobhistory
查看Jobhistory信息
八、测试集群是否安装成功
#检测HDFS是否成功启动,使用命令:
hadoop fs -ls /
#检测YARN集群是否启动成功,使用提交MapReduce例子程序的方法进行测试,使用命令:
cd /opt/module/hadoop-3.2.1/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.2.1.jar pi 2 2
相关文章参考:
MySQL安装,点此链接跳转















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









