







 本文详细介绍了KNN(K-Nearest Neighbor)算法,包括其基本思想、实践应用,以及如何手写实现。通过鸢尾花数据集展示了KNN的实际操作,包括数据划分、模型训练和评估。此外,还探讨了KNN的超参数调优,如选择最佳的K值,以及与距离计算相关的超参数。最后,文章指出KNN不仅可以用于分类,也可应用于回归问题,并总结了KNN算法的优缺点。
本文详细介绍了KNN(K-Nearest Neighbor)算法,包括其基本思想、实践应用,以及如何手写实现。通过鸢尾花数据集展示了KNN的实际操作,包括数据划分、模型训练和评估。此外,还探讨了KNN的超参数调优,如选择最佳的K值,以及与距离计算相关的超参数。最后,文章指出KNN不仅可以用于分类,也可应用于回归问题,并总结了KNN算法的优缺点。
什么是 KNN近邻算法?
通常我们都知道这么一句话 “近朱者赤近墨者黑” , KNN算法就是这句话的完美诠释了。
我们想要判断某个东西属于哪个分类, 那么我们只需要找到最接近该东西的 K 个邻居, 这些邻居中哪种分类占比最大, 那么我们就认为该东西就属于这个分类!
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别 。
KNN近邻算法 实践
这里我们会使用到 sklearn 和 numpy 两个库, 当然就算你不熟悉也没关系, 这里主要就是为了直观的感受一下 KNN 算法。
- 导入数据 这里我们使用
sklearn中自带的测试数据集:鸢尾花数据。 import numpy as np import matplotlib import matplotlib.pyplot as plt from sklearn import datasets #这里我们采集的是 sklearn 包里面自带的 鸢尾花 的数据 digits = datasets.load_iris() # 鸢尾花的种类 用 0,1,2 标识 y = digits.target # 鸢尾花的 特征,为了可视化的需求,我们这里只取前两个特征 x = digits.data[:,:2] # 在2d平面上画出鸢尾花的分布情况 #为了方便显示,我们这里只取标识为 0 和 1 两种鸢尾花的数据 plt.scatter(x[y==0,0],x[y==0,1],color='r') plt.scatter(x[y==1,0],x[y==1,1],color='b') plt.show()
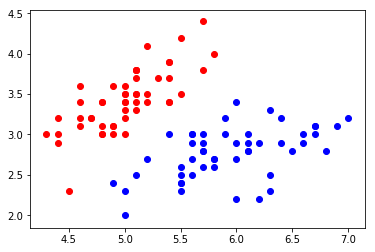
鸢尾花分布图
- 拆分数据 一般来说,对于数据集我们需要拆分为测试 和 训练 数据, 以方便我们后续对训练的模型进行预测评分 # 将数据拆分为 测试数据 和 训练数据 from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2) # 显示如下图 plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1],color='r') plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1],color='b') # 测
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8408
8408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









