







引用是什么呢?
引用(reference)是C++引入的新语言特性,是C++常用的一个重要内容之一,正确、灵活地使用引用,可以使程序简洁、高效。
引用其实是给已经定义的变量起一个别名
定义的格式为: 类型 & 引用的变量名 = 已经定义的变量
引用这样几个特点:
1.一个变量可以起多个别名,也就是说可以进行多次引用
2.引用必须初始化
3.引用 只能在引用的时候初始化一次,不能改变引用,就是不能再去引用别的变量
例如:
int a = 10;
int& c = a;
cout << "a address:" << &a << endl;
cout << "c address:" << &c << endl;c是a的别名,可以理解为,给变量a的又加了一个名字
引用作为函数参数
在C中,函数参数是值传递,如果想改变一些变量的时候就得用指针,这个可以提高效率,在C++中,我们可以选择引用,引用的其中一个重要的作用就是作为函数的参数,例如:
void Swap(int& a, int& b) {
int tmp = a;
a = b;
b = tmp;
}
int main() {
int a = 10;
int b = 11;
cout << "a = " << a << "b = " << b << endl;
Swap(a, b);
cout << "a = " << a << "b = " << b << endl;
system("pause");
return 0;
}在上面的Swap函数中,形参是实参的别名,所以就可以直接更改。
根据上面的代码,我们分析可以得出以下几个结论:
1.引用的效果看起来和指针产生的效果是一样的
2.使用引用传递函数的参数,在内存中并没有产生一个新的变量,它是实参的别名,在函数内部是直接对实参进行操作的,当参数传递的数据较大时,使用引用的效果更好,不用为形参重新创建内存空间,而且效率也会更高
如果我们需要引用一个变量,但是又不想改变它,就可以在引用时加上const,使之成为常引用,例如:
int a = 10;
const int& b = a;
a = 20;
//错误,不能修改常量
b = 10;我们来看一下这样两行代码:
double c = 10.0;
int b = c;在上面的赋值过程中,会有一个隐式的类型转换,先是创建一个临时变量,然后再把c复制给临时变量,然后再把临时变量的值进行截取,再赋值给b,那么再看下面的代码:
double c = 10.0;
int& b = c;上面的代码是错误的,因为看似是引用c,但其实是想对那个临时变量取一个别名,临时变量具有常性,所以如果想要编译通过,就必须使用常引用,如:
double c = 20.0
const int& b = c;
引用作为返回值
引用还可以作为函数的返回值,用引用做返回值时,函数应该这样定义:
类型标识符 &函数名(形参列表及类型说明)
{函数体}
int fun1(int a, int b) {
int c = a + b;
return c;
}
int& fun2(int a, int b) {
int c = a + b;
return c;
}
int main() {
int a = 10;
int b = 20;
//c1是fun1函数的返回值,30
int c1 = fun1(a, b);
//c2是在fun1中临时变量的别名,可能会出错,因为不能从被调函数中返回一个临时变量或局部变量的引用
int& c2 = fun1(a, b);
//c3是fun2的返回值,但是系统不会产生一个返回值的副本
int c3 = fun2(a, b);
//c4是函数fun2中变量c的所存在的内存空间的别名
int& c4 = fun2(a, b);
cout << c3 << endl;
cout << c4 << endl;
//因为在fun2函数之后还有cout函数的调用栈,所以c4的值是一个随机值通过上面的例子,我们可以得出以下的结论:
1.不能返回局部变量的引用,因为局部变量会在函数完成后被销毁,即使能访问到也是一个随机值,这是个非法的操作。
2 如果返回对象出了当前函数的作用域依旧存在,则最好使用引用返回,因为这样更高效。
引用的特性
引用看似是给变量取了个别名,那么,具体是如何实现的呢?
int& Add(int a, int b) {
int c = a + b;
return c;
}
int main() {
int a = 10;;
int b = 20;
int c = Add(a, b);
system("pause");
return 0;
}看这段代码,引用做返回值,注意,引用不要做局部变量的返回值,但是这里的关注点不是这个,如图:

这个是在Add函数中的int c = a + b这个表达式的汇编代码,注意,前面三句的意思是,把a和b相加的值放在寄存器eax里面,然后再赋值给c,注意reutrn c这一句的汇编代码,lea eax , [c]这一句,是把c的地址放到eax里面,继续看图:
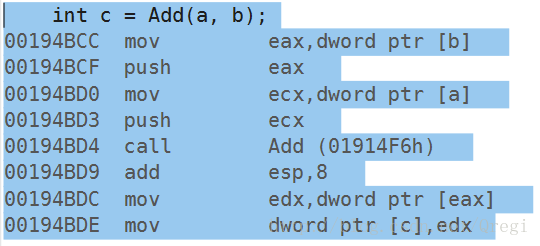
这是主函数中的Add函数的调用,前面已经看到了,eax里面存的是c的地址,注意看最后两句汇编代码,是把eax里面的地址的内容赋给edx,再把edx赋值给c。
还有一个例子:
int a = 10;;
int b = 20;
// int c = Add(a, b);
int&c = a;看汇编代码:
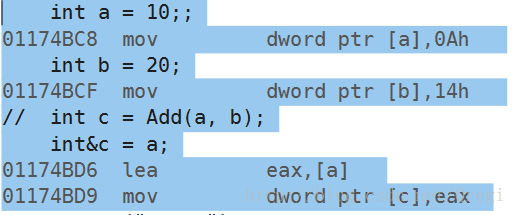
这几行代码,c是a的引用,跟上面一样,都是把a的地址给寄存器eax,然后再把寄存器eax存储的地址给变量c。
所以,引用虽然跟指针有很多不同,但是其底层还是用指针来实现的,那么,引用和指针有什么区别呢?
引用和指针的区别
引用和指针的区别有以下几点:
1.引用在创建的时候必须被初始化,而指针可以不初始化
2.引用被初始化后,就不能再改变了,而指针可以被改变
3.引用不能对不存在的变量进行引用,而指针可以指向NULL
4.指针和引用的自增(++)和自减(–)是有区别的(如果在数组中指针自增是指向下一个元素,而如果引用一个变量,然后自增,其实是给这个变量自增)
5.相对而言,引用比指针更安全
本质上,引用传递在底层上和指针传递的实现方式是一样的,我们可以认为引用仅仅是语法上的一种不同方法(有时称为“语法糖”)。什么是语法糖,举个例子,a[i]和(a+i)本质上是一样的,但a[i]的可读性更强,比(a+i)更加直观容易理解,语法糖使得程序更加不容易出错,更好用,而且也不会带来性能上的损失。














 4062
4062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









