



1、决策树基本原理
1、决策树是一个树结构(可以二叉或非二叉),每一个非叶子节点表示一个特征属性的测试,
每一个分支代表这个特征属性在某个值域上的输出,叶节点存放类别。
2、决策过程:从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到达到叶子节点,叶子节点存放的类别作为决策结果。
1)决策树&knn
1、决策树:
优势-数据形式非常容易理解 白盒模型、可以视图化 、效率高
缺点:可以把所有数据的特征都划分到各自满足条件的特定子集中,这样会带来的问题模型不具备很好的泛化能力 ,只提供了一个算法理论基础,易过拟合
解决过拟合:
1、集成学习GBDT梯度提升树(决策树的进化版本)不需要剪纸处理
2、剪树枝(前剪枝、后剪枝)控制分裂点最小值 控制决策树深度
2、knn:
优点:可以完成很多分类任务;
缺点:无法给出数据的内在含义
2)构造决策树:
关键步骤:分裂属性。就是某个节点按照某一特征属性的不同划分构造不同的分支。
分裂属性的三种情况:
1、属性是离散值 且不要求生成二叉决策树,此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉树,此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支
3、属性是连续值,此时确定一个值作为分裂点,按照>分裂点和<=分裂点生成两个分支。
属性选择度量:自顶向下递归分治,不回溯的贪心策略,
3)有关算法:
1、ID3 算法

2、C4.5算法:增加信息增益比(info_H-info_L)/info_H
3、对比
Entory熵:描述数据的混乱程度 -log2(pi) 计算效率偏低,更适合处理离散型数据
JINI系数:描述数据有序程度-pi**2计算效率高 ,适合连续数据
4、C5.0算法:效率的提升
5、CART算法:只做二叉分裂,生成的是一个二叉树
4)分析:
任意一组数据都有可能划分成绝对纯的一组数据,不能划分成100可能纯度高但没有泛化能力,
2、实战iris分类
1)内容
决策树(完全成长)&决策树(决策树的深度=4,分裂四次)&KNN&LogisticRegression对比
2)代码
1、导包加载数据集
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
# data,target=load_iris(return_X_y=True)
iris=load_iris()
iris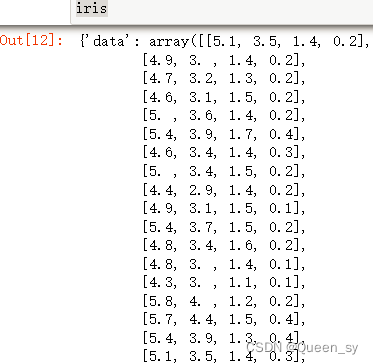

2、数据
data=iris.data
target=iris.target3、建模
#模型
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
dc=DecisionTreeClassifier()
dc4=DecisionTreeClassifier(max_depth=4)
# 限制决策树深度max_depth=None默认完全生长(见上面原理)
knn=KNeighborsClassifier()
lr=LogisticRegression()
dc.fit(train,target)
dc4.fit(train,target)
knn.fit(train,target)
lr.fit(train,target)
#####################################################################
#找背景点得到训练集
xmin,xmax=train[:,0].min(),train[:,0].max()
ymin,ymax=train[:,1].min(),train[:,1].max()
x_=np.linspace(xmin,xmax,100)
y_=np.linspace(ymin,ymax,100)
#网络交叉处理
xx,yy=np.meshgrid(x_,y_)
# xx,yy扁平处理后级联,得到测试集数据()背景点
X_test=np.c_[xx.ravel(),yy.ravel()]
# np.concatenate((xx.reshape((-1,1)),yy.reshape((-1,1))),axis=1)相等
#######################################################################
# 绘制
plt.scatter(X_test[:,0],X_test[:,1])
plt.scatter(train[:,0],train[:,1],c=target)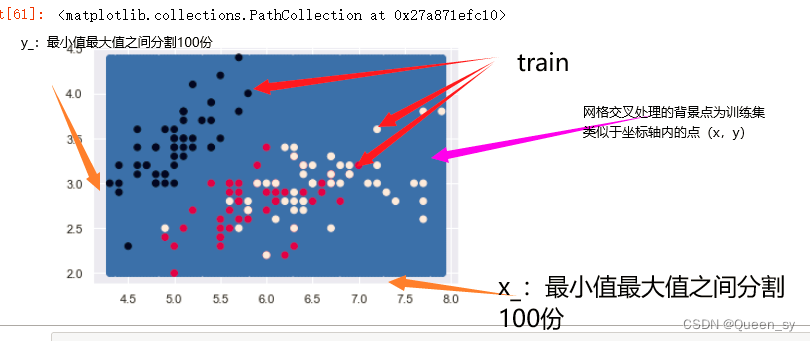
# x_.shape=(100,)
# X_test.shape=(10000, 2)
4、预测
y_test_dc_p=dc.predict(X_test)
y_test_dc4_p=dc4.predict(X_test)
y_test_knn_p=knn.predict(X_test)
y_test_lr_p=lr.predict(X_test)
result={
"DC":y_test_dc_p,
"DC4":y_test_dc4_p,
"KNN":y_test_knn_p,
"LR":y_test_lr_p
}5、效果展示
# 颜色设置
from matplotlib.colors import ListedColormap
colors=sns.color_palette("hls")
cmap= ListedColormap(colors[:3])
plt.figure(figsize=(18,5))
location=1
for k,v in result.items():
ax=plt.subplot(1,4,location)
location+=1
ax.scatter(X_test[:,0],X_test[:,1],c=v,cmap=cmap)
ax.scatter(train[:,0],train[:,1],c=target)
ax.set_title(k)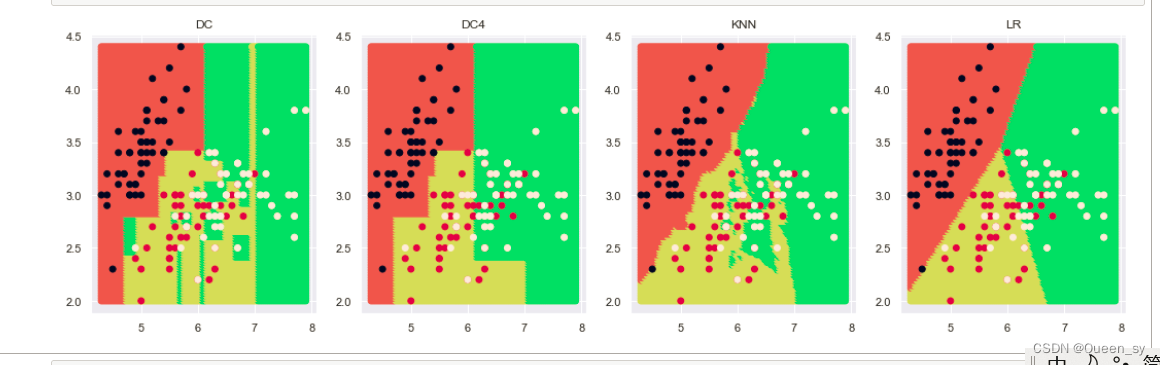
3)结论
lr 直线
knn曲线
下面讲解绘制决策树 需要安装软件
3、graphviz-2.38.msi免费下载使用绘图
1)安装
graphviz(图形绘制软件)下载 v2.38官方版 含中文教程-第五资源
里面有安装步骤,一直next安装就可以了
1、双击“graphviz-2.38.msi”进入到软件安装向导
2、点击next选择软件安装目录,默认为“C:\Program Files (x86)\Graphviz2.38\”
3、一直next安装就可以了
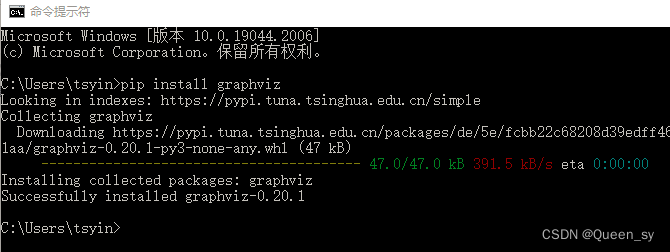
4、在终端cmd----------pip install graphviz
5、
![]()
在文件夹下cmd进入
输入dot -version
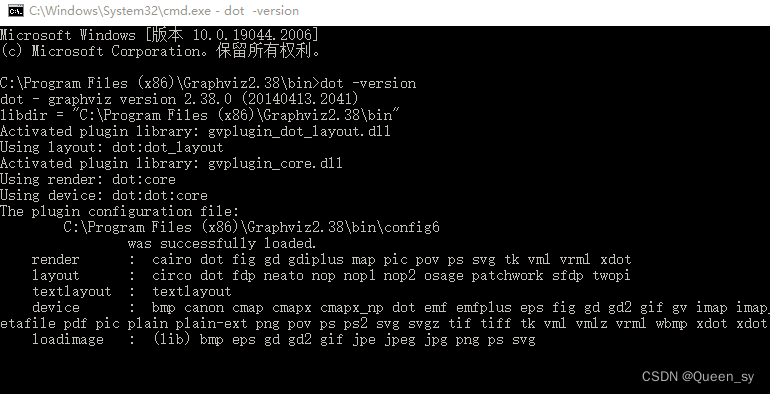
看到版本说明则安装成功
6、配环境变量:C:\Program Files (x86)\Graphviz2.38\bin
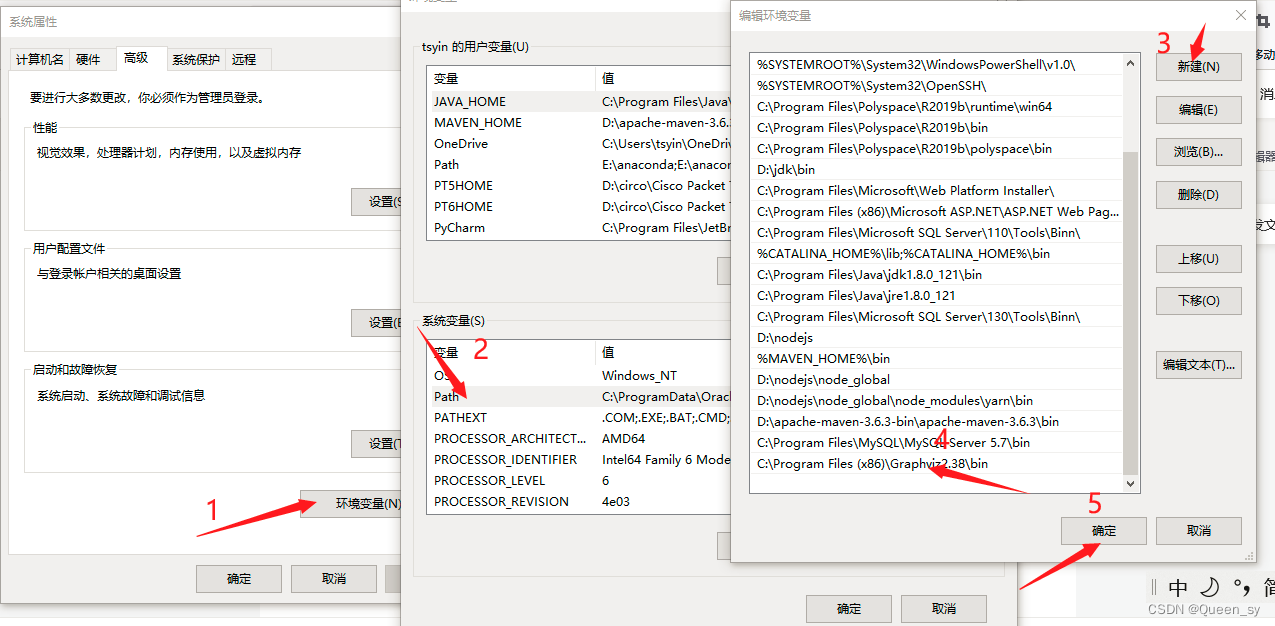
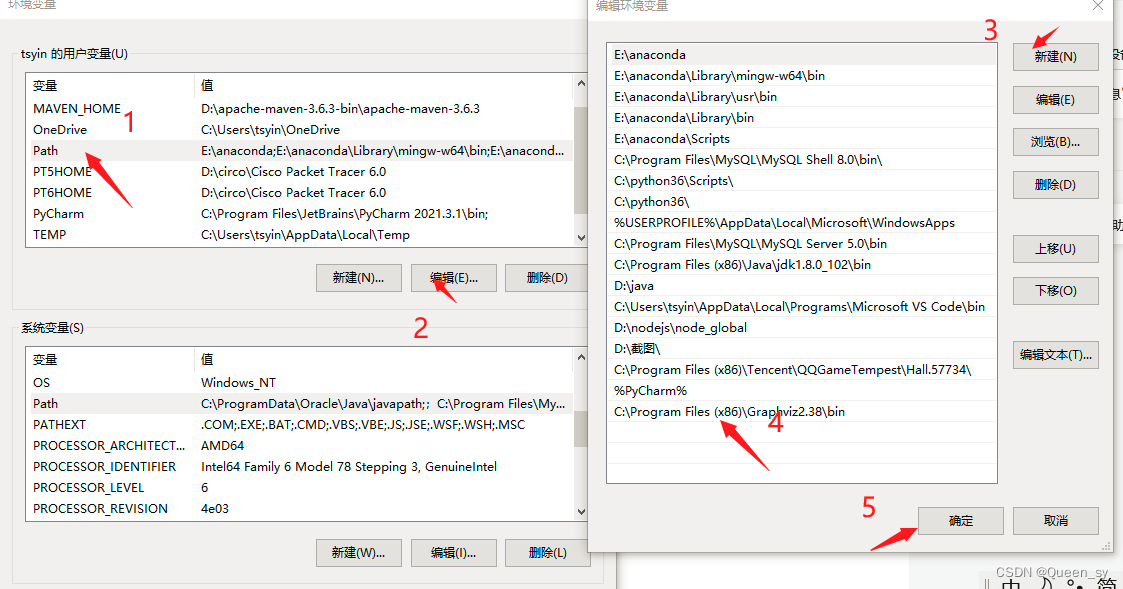
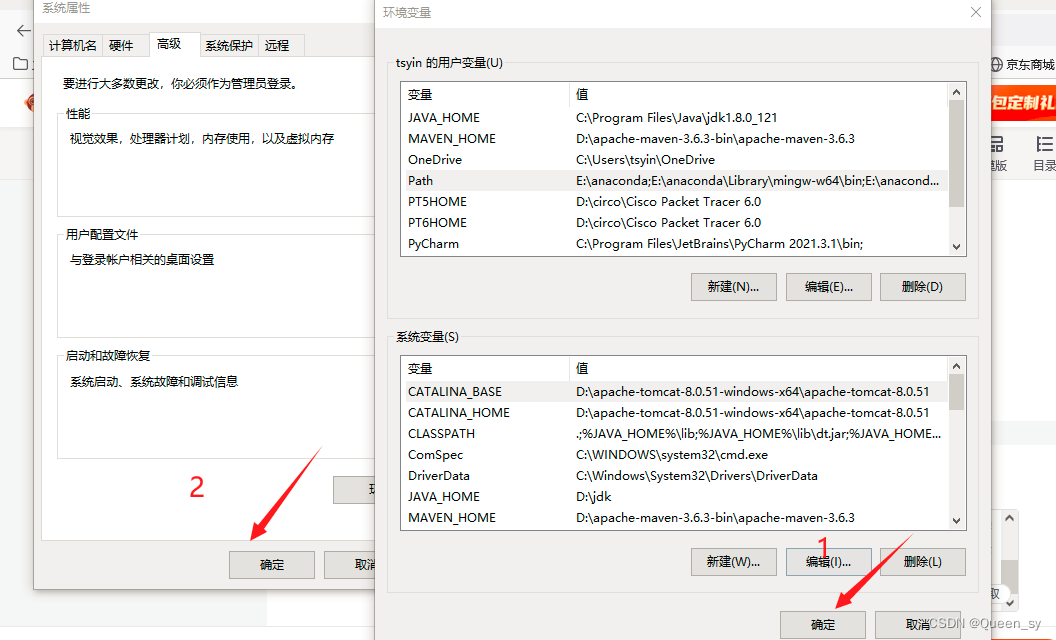
重新打开检查一下
7、在终端cmd--------
8、则jupyter notebook中可以使用,画图时导入包先
2)绘制决策树代码
使用上面代码 需要重启jupyternotebook
继续上面代码继续添加
import graphviz
from sklearn import tree
target_names=iris.target_names
iris.feature_names

#参数使用上面代码中的树 out_file不配置默认生成本地文件
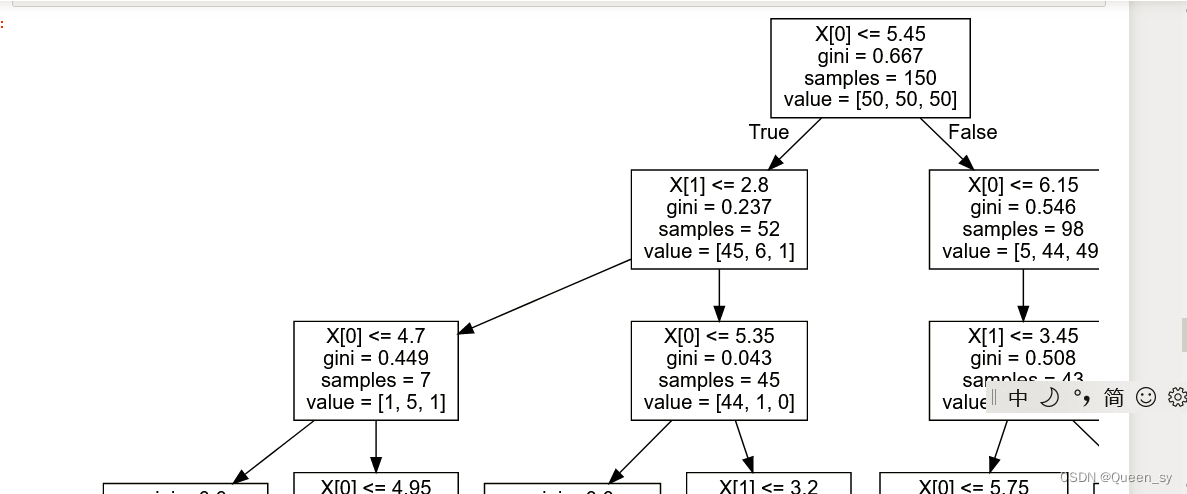
dot=tree.export_graphviz(dc4,out_file=None,feature_names=['sepal length (cm)',
'sepal width (cm)'],class_names=target_names)
graphviz.Source(dot) 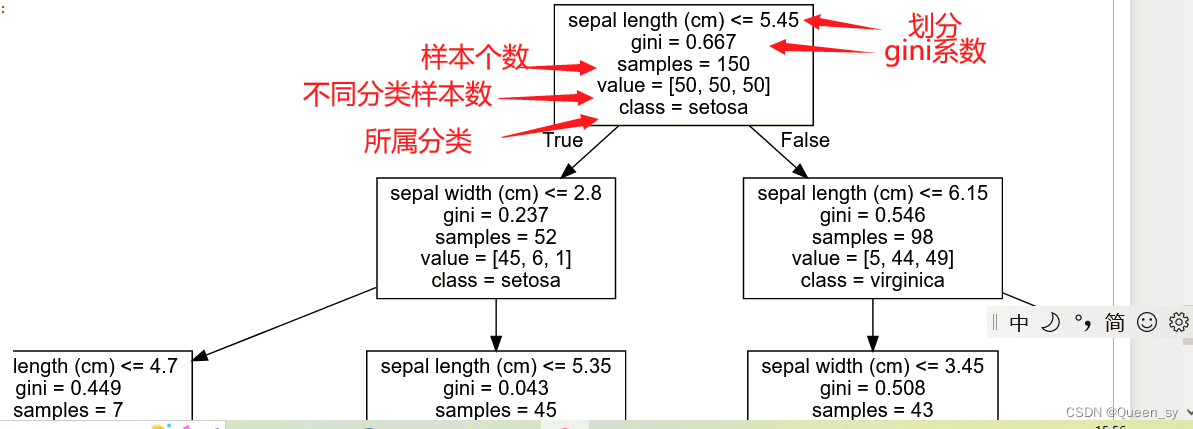
绘制完成
机器学习深度学习交流群:qq585241255


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









