






目录
梯度下降算法的引入:
1、以Linear Model为例 y=x*w
模型开始w是一个随机猜测,w=random value,
搜索的过程:就是要找一个w最适合数据集的w
目的:使得Σ(y^-y)²最小。
最直接的方法:将认为权重可能取值的区间w_list=[]表示出来,循环,每层循环求取一个loss(损失) loss最小的w最佳,例如
w_list=[]
mse_list=[]
for w in np.arange(0.0,4.1,0.1):
print('w=',w)
loss_sum=0
......当权重增多时,并不可取
2、升级算法:梯度下降算法引入
1)公式:
gradient=

通过 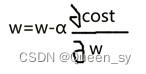 不断搜索w, 直到找到全局最小值(loss最小)所对应的w,但在此过程中有可能1)将局部最优解误成全局最优解。
不断搜索w, 直到找到全局最小值(loss最小)所对应的w,但在此过程中有可能1)将局部最优解误成全局最优解。
2)当导数为0时,w不更新,陷入鞍点,无法迭代。(马鞍,每个轴有一个切面,一个切面w对应loss取最小值,但别的切面可能取最大值)
2)练习:
已知x、y求w和loss 此题称作cost,其中cost=(y_pred-y)**2
x=[1.0,2.0,3.0]
y=[2.0,4.0,6.0]
w=1.0
def forword(x):
return x*w
def cost(x,y):
cost=0
for i,j in zip(x,y):
y_perd=forword(x)
cost+=(y_perd-y)**2
return cost/len(x)
# 取cost平均值
def gradient(x,y,w):
grad=0
for i,j in zip(x,y):
grad+=2*i*(i*w-j)
return grad/len(x)
# grad也要取平均值
print('predict before training',4,forword(4))
for epoch in range(100):
cost_val=cost(x,y)
grad_val=gradient(x,y,w)
w-=0.01*grad_val
# 更新梯度
print('epoch:',epoch,'w=',w,'loss=',cost_val)
print('predict after training', 4, forword(4))loss曲线是一直下降的,如果不是那么训练失败(先下降在上升也是失败的)
训练失败的原因:学习率太大
3、随机梯度下降(深度学习常用这个)
1、区别:
cost=(y_pred-y)**2=(x*w-y)**2 其中**2表示平方


2、练习(与上题相同)
已知x、y求w和loss 此题称作cost,其中cost=(y_pred-y)**2
x=[1.0,2.0,3.0]
y=[2.0,4.0,6.0]
w=1.0
# print('type(x)=',type(x))
# # type(w)
def forword(x):
return x*w
def loss(x,y):
y_pred=forword(x)
return (y_pred-y)**2
def gradient(x,y,w):
return 2*x*(x*w-y)
print('predict before training',4,forword(4))
for epoch in range(100):
for xx,yy in zip(x,y):
l=loss(x,y)
grad=gradient(x,y)
w=w-0.01*grad
print('epoch:',epoch,'w=',w,'loss=',l)
print('predict after training', 4, forword(4))














 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









