







欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定!
对商业智能BI、大数据分析挖掘、机器学习,python,R等数据领域感兴趣的同学加微信:tsaiedu,并注明消息来源,邀请你进入数据爱好者交流群,数据爱好者们都在这儿。
本文来自天善智能社区专栏作者[文文](https://ask.hellobi.com/people/%E7%9F%B3%E6%99%93%E6%96%87)
配套学习视频教程: [手把手教你用Python 实践深度学习](https://edu.hellobi.com/course/278)
阿里近几年公开的推荐领域算法可真不少,既有传统领域的探索如MLR算法,还有深度学习领域的探索如entire -space multi-task model,Deep Interest Network等,同时跟清华大学合作展开了强化学习领域的探索,提出了MARDPG算法。从本篇开始,我们就一起来探秘这些算法。这里,我们只是大体了解一下每一个算法的思路,对于数学部分的介绍,我们不会过多的涉及。
1、算法介绍
现阶段各CTR预估算法的不足
我们这里的现阶段,不是指的今时今日,而是阿里刚刚公开此算法的时间,大概就是去年的三四月份吧。
业界常用的CTR预估算法的不足如下表所示:
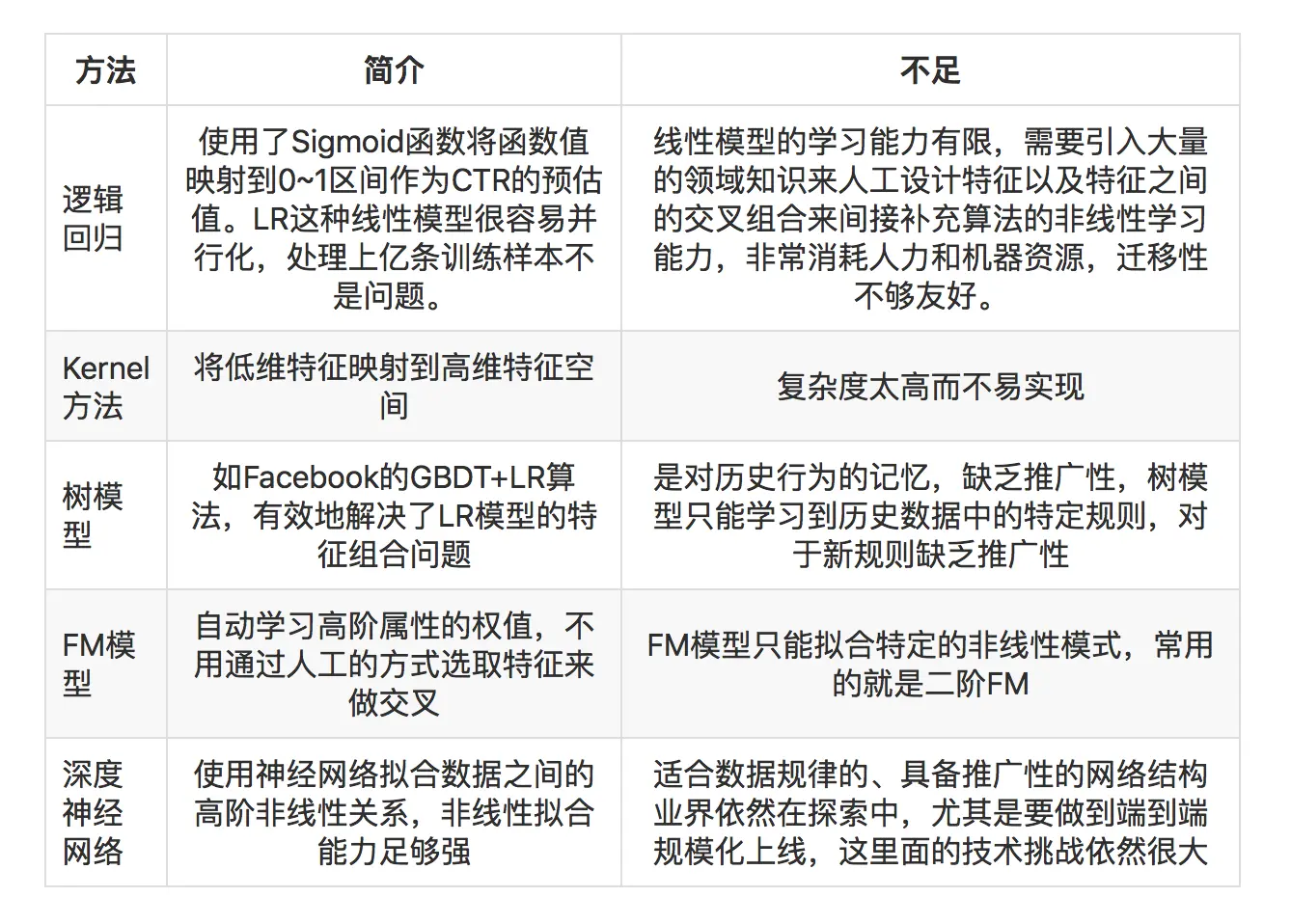
那么挑战来了,如何设计算法从大规模数据中挖掘出具有推广性的非线性模式?
MLR算法
2011-2012年期间,阿里妈妈资深专家盖坤创新性地提出了MLR(mixed logistic regression)算法,引领了广告领域CTR预估算法的全新升级。MLR算法创新地提出并实现了直接在原始空间学习特征之间的非线性关系,基于数据自动发掘可推广的模式,相比于人工来说效率和精度均有了大幅提升。
MLR可以看做是对LR的一个自然推广,它采用分而治之的思路,用分片线性的模式来拟合高维空间的非线性分类面,其形式化表达如下:
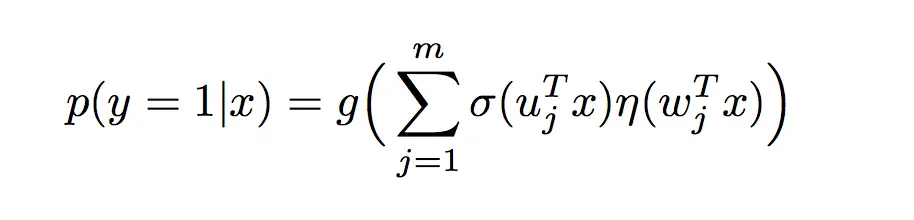
其中u是聚类参数,决定了空间的划分,w是分类参数,决定空间内的预测。这里面超参数分片数m可以较好地平衡模型的拟合与推广能力。当m=1时MLR就退化为普通的LR,m越大模型的拟合能力越强,但是模型参数规模随m线性增长&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 793
793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









