






OFDM同步算法实现流程及算法介绍
同步的意义
通过分析OFDM(正交频分复用)的系统模型我们可以得知,其子载波间的正交性对系统的性能优劣起到了至关重要的作用,即要求接收端做到频域上的同步;同时为了确保接收端按时序正确解码,即能够正确识别OFDM符号的开始与结束,要求接收端做到时域上的同步。因此同步算法的好坏对整个OFDM传输系统的性能优劣起着决定性的作用。下图为同步实现总流程图:
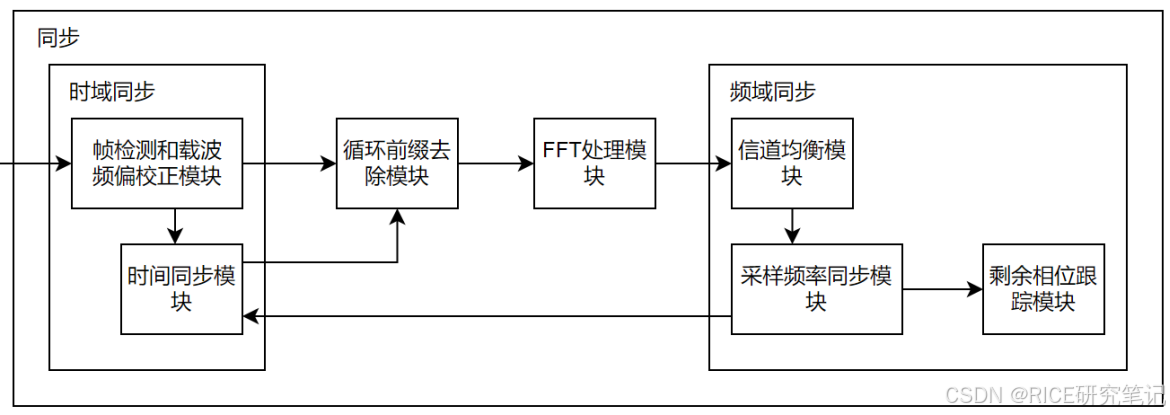
下面将介绍一些经典的分组检测算法、符号同步算法以及载波频率同步算法。
1 分组检测(粗同步)
分组检测是接收机工作的第一步,其主要用途为检测信道上是否有新数据到达,并且粗略估计出数据到达的位置,以方便后续符号同步(精同步)的精确定时估计。
常见的分组检测方法有接收信号能量检测法、双滑动窗口分组检测法、采用前导结构进行分组检测法。同另外两种算法相比,采用前导结构进行分组检测法是利用发射信号中前导结构中短训练符号的周期性而产生的相关,不易受外界因素如发射功率、信道、噪声等影响,具有更好的性能,因此下面介绍采用前导结构进行分组检测,即时延相关算法的相关原理。
算法原理
时延相关算法主要利用了前导中短训练符号的周期性。此算法中涉及两个窗口,窗口C和窗口P,两个窗口内的能量为
C
n
C_n
Cn、
P
n
P_n
Pn,并且判决变量
m
n
m_n
mn独立于接收功率。
延时相关
C
n
C_n
Cn的值为
C
n
=
∑
k
=
0
L
−
1
r
n
−
k
r
n
−
k
−
D
∗
\begin{align} C_{n} =\sum_{k=0}^{L-1}r_{n-k}r_{n-k-D}^{*} \end{align}
Cn=k=0∑L−1rn−krn−k−D∗
接收信号能量
P
n
P_n
Pn的值为
P
n
=
∑
k
=
0
L
−
1
∣
r
n
−
k
−
D
∣
2
\begin{align} P_{n} =\sum_{k=0}^{L-1}\left |r_{n-k-D} \right | ^{2} \end{align}
Pn=k=0∑L−1∣rn−k−D∣2
则延时相关算法的判决变量
m
n
m_n
mn为
m
n
=
∣
C
n
∣
P
n
=
∣
∑
k
=
0
L
−
1
r
n
−
k
r
n
−
k
−
D
∗
∣
∑
k
=
0
L
−
1
r
n
−
k
−
D
r
n
−
k
−
D
∗
\begin{align} m_{n} =\frac{\left | C_{n} \right | }{P_{n} } =\frac{\left | \sum_{k=0}^{L-1}r_{n-k}r_{n-k-D}^{*} \right | }{\sum_{k=0}^{L-1}r_{n-k-D}r_{n-k-D}^{*} } \end{align}
mn=Pn∣Cn∣=∑k=0L−1rn−k−Drn−k−D∗
∑k=0L−1rn−krn−k−D∗
其中D为一个短训练符号的长度,即16,L为检测长度。
仿真分析
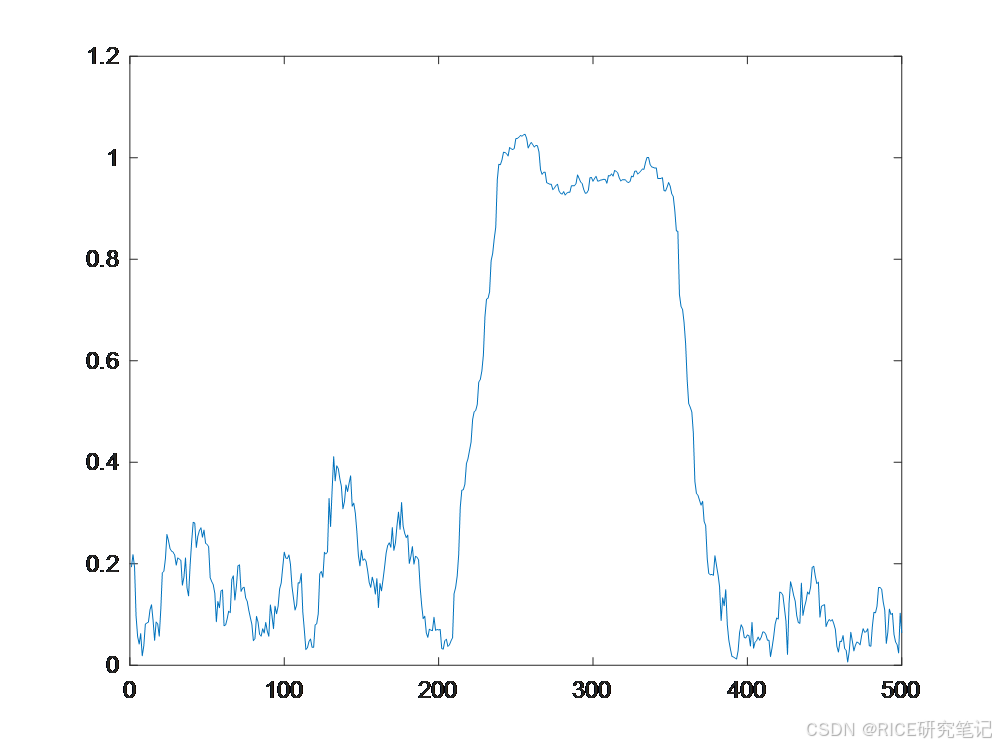
当接收的信号只有噪声时,在理想情况下输出的延时相关值 C n C_n Cn为0,因为噪声取样值的互相关系数为0,因此在数据分组开始前 m n m_n mn值很小;当接收到第2个短训练符号时, C n C_n Cn为相同短训练符号的互相关系数, m n m_n mn开始明显增加,并且出现一个持续9个短训练符号长度的相关平坦。
但是此算法在低信噪比条件下,判决变量 m n m_n mn可能由于受到信道中较大随机噪声的影响而超过预先设定的门限值,从而错误的判断有分组到来,即虚警概率提高。因此,为了提高分组检测算法的可靠性,可以在延时相关算法的基础上增加保持长度的要求,即判决变量要在预设门限值之上保持一定的采样周期数才判决有分组的到来,从而避免了较大随机噪声的影响。
2 符号同步(精同步)
上述算法只能对数据分组的起始提供粗略的估算,并不能精确判断出数据的起始位置,因此还需要用符号同步来对数据分组进行准确定时,确保接收端能够准确地识别OFDM符号的开始和结束,即对数据进行精同步。
常见的符号同步算法有Schmidl&Cox算法[1]、Minn算法[2,3]、Park算法[4]、基于CP的定时同步算法(ML算法)、利用短训练符号做互相关等,其中前三种算法需要额外设置特定的训练序列,后两种算法可以直接在现有的OFDM帧结构上进行同步,因此下面分别介绍后两种算法。
基于CP的定时同步算法原理
基于CP的定时同步算法的基本原理为利用CP和OFDM符号有效数据的相关性,通过双滑动窗进行符号定时估计,结合最大似然估计算法完成同步,其具体流程图如下:
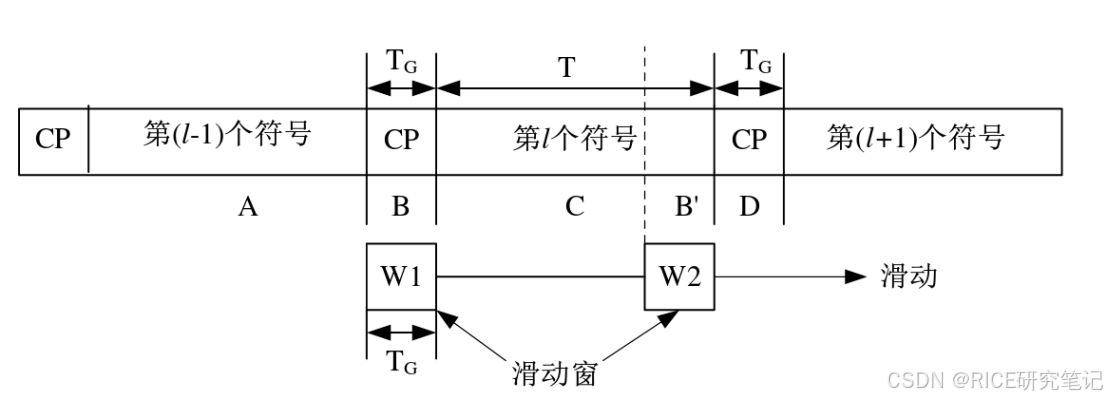
W1和W2是两个滑动窗,采样块及滑动窗长度相同,通过在采样区间内滑动寻找两个窗内相似的采样值。当CP落在滑动窗W1内,两个窗内的采样块之间的相似度最大,此时通过求得此最大值可以判定符号定时估计[5]。
此算法计算公式为:
d
^
M
L
=
arg
max
{
∣
γ
(
m
)
∣
−
ρ
Φ
(
m
)
}
\begin{align} \hat{d}_{M L} & = \arg \max \{|\gamma(m)|-\rho \Phi(m)\} \end{align}
d^ML=argmax{∣γ(m)∣−ρΦ(m)}
其中:
γ
(
m
)
=
∑
k
=
m
m
+
L
−
1
r
(
k
)
r
∗
(
k
+
N
)
\begin{align} \gamma \left ( m \right ) =\sum_{k=m}^{m+L-1} r\left ( k \right ) r^{*}\left ( k+N\right ) \end{align}
γ(m)=k=m∑m+L−1r(k)r∗(k+N)
ρ
=
S
N
R
S
N
R
+
1
\begin{align} \rho=\frac{SNR}{SNR+1} \end{align}
ρ=SNR+1SNR
Φ
(
m
)
=
1
2
∑
k
=
m
m
+
L
−
1
(
∣
r
(
k
)
∣
2
+
∣
r
(
k
+
N
)
∣
2
)
\begin{align} \Phi(m)=\frac{1}{2} \sum_{k=m}^{m+L-1} ( \left | r ( k )\right |^{2}+ \left | r ( k+N )\right |^{2}) \end{align}
Φ(m)=21k=m∑m+L−1(∣r(k)∣2+∣r(k+N)∣2)
L
L
L表示CP的长度
最后可以得到m正好在CP的起始点位置时得到峰值。
但此算法中涉及到未知信道上信噪比的计算,在实际实现过程中精确计算出信噪比的值并不是一件容易的事。下面介绍一种更为简单的符号同步算法。
利用短训练符号做互相关算法原理
IEEE 802.11a 协议中设计的前导结构,对发射机和接收机都是已知的。因此,接收机可以将载波同步模块输出的数据与本地已知的短训练符号做互相关,从而将分组检测模块对数据分组进一步进行精确估计,确定短训练符号的结束点或长训练符号的起始点。
将接收的数据分组与本地已知短训练符号的共轭复数相乘并累加,可得互相关系数为
C
k
=
∑
m
=
0
D
−
1
r
k
−
m
×
S
m
∗
\begin{align} C_{k} =\sum_{m=0}^{D-1} r_{k-m} \times S_{m}^{*} \end{align}
Ck=m=0∑D−1rk−m×Sm∗
其中,上标*表示共轭,D为互相关系数的长度。
当 ∣ C k ∣ |C_k| ∣Ck∣峰值出现时,表示这个时刻点为一个短训练符号的结束。利用这一特性,即可找到OFDM 分组中所有短训练符号的结束点。当 ∣ C k ∣ |C_k| ∣Ck∣出现最后一个峰值时,这一时刻即为短训练符号的结束时间点。为了简化运算,可以设置一个阈值,当 ∣ C k ∣ |C_k| ∣Ck∣超过此阈值时就认定找到一个短训练符号的结束点。
仿真分析
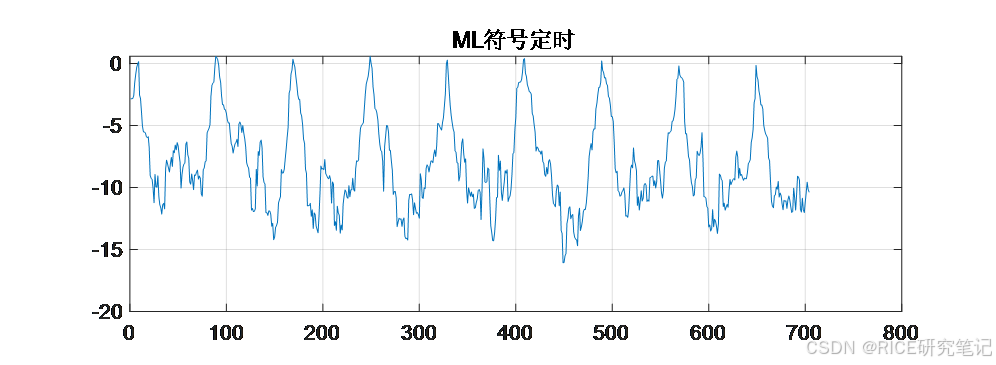
通过分析OFDM符号的性质我们可以得知,其CP(m位)与数据符号的后m位为一一对应的关系。因此如果时序同步时,将定位点位于数据符号开始位前a位(a<m),对数据进行分段处理后进入FFT处理模块中的数据值仍为所发送的数据符号的值,只是数据的前后顺序有变化,而这一点是可以在信道估计模块中进行处理并且重新排序的;但如果定位点位于数据符号开始位之后,或数据符号开始位前b位(b>m),对数据进行分段处理后进入FFT处理模块中的数据值则不是一个完整的数据符号,即会导致丢帧的情况。因此在实际处理中,可以将符号定时点估计值往前移4-5个取样点,以提高整体系统的估算准确率。
3 载波频率同步
载波频率同步的主要目的是确保每个子载波的频率位置不发生偏移。OFDM 技术是同时在多个重叠子信道上传输信号的,为了正确接收,必须严格保证子载波之间的正交性,但是由于多普勒频移和收发晶振的不完成相同,往往存在一定的载波频率偏差,这将破坏子载波间的正交性,且这种频差对相位的影响还具有累加性[6]。因此,为了保证OFDM 性能,必须进行载波频率同步。
常见的载波频率同步算法有Schmidl&Cox频偏估计算法[1]、Moose算法、基于最大似然法的频率同步算法[7,8]。基于最大似然法的频率同步算法较为简易,并且估算准确率较高,因此下面介绍基于两个连续重复符号的最大似然法的频率同步算法。
算法原理
假设发送信号为
x
n
x_n
xn,那么接收信号即为
r
n
=
x
n
e
j
2
π
△
f
n
T
s
\begin{align} r_{n} =x_{n}e^{j2\pi \bigtriangleup fnT_{s} } \end{align}
rn=xnej2π△fnTs
其中
△
f
\bigtriangleup f
△f为发送载波频率和接收载波频率之间的频率差,由此可以得到周期重复信号的延时相关和为
R
=
∑
n
=
0
L
−
1
r
n
∗
r
n
+
D
∗
=
∑
n
=
0
L
−
1
x
n
e
j
2
π
△
f
n
T
s
∗
(
x
n
e
j
2
π
△
f
(
n
+
D
)
T
s
)
∗
=
∑
n
=
0
L
−
1
x
n
∗
x
n
+
D
∗
e
−
j
2
π
△
f
D
T
s
=
e
−
j
2
π
△
f
D
T
s
∑
n
=
0
L
−
1
∣
x
n
∣
2
\begin{align} R =\sum_{n=0}^{L-1}r_n*r_{n+D}^{*} \\ =\sum_{n=0}^{L-1}x_{n}e^{j2\pi \bigtriangleup fnT_{s} }* (x_{n}e^{j2\pi \bigtriangleup f(n+D)T_{s} })^{*}\\ =\sum_{n=0}^{L-1}x_{n}*x_{n+D}^{*}e^{-j2\pi \bigtriangleup fDT_{s} }\\ =e^{-j2\pi \bigtriangleup fDT_{s} }\sum_{n=0}^{L-1}|x_n|^{2} \end{align}
R=n=0∑L−1rn∗rn+D∗=n=0∑L−1xnej2π△fnTs∗(xnej2π△f(n+D)Ts)∗=n=0∑L−1xn∗xn+D∗e−j2π△fDTs=e−j2π△fDTsn=0∑L−1∣xn∣2
整理上述等式即可得到发送端和接收端的频率差为
f
Δ
=
−
1
2
π
D
T
s
∠
R
\begin{align} f_{\Delta } =-\frac{1}{2\pi DT_s} \angle R \end{align}
fΔ=−2πDTs1∠R
其中
D
D
D为采样点数,
T
s
T_s
Ts为采样周期,
R
R
R为周期重复信号的延时相关和,理论上讲如果没有频偏,
R
R
R应该为一个实数。
在这一步可以纠正大部分的频率偏差。
4 总结
通过上述算法处理后的信号中还会有少部分频率偏移残留,即相位偏移的存在,这部分偏移可以通过信道估计及剩余相位补偿进行纠正。
参考文献
[1] Schmidl T M, Cox D C. Robust frequency and timing synchronization for OFDM[J]. Communications IEEE Transactions on, 1998,45(12):1613~1621.
[2] Minn H, Zeng M, Bhargava V K. On timing offset estimation for OFDM systems[J]. Communications Letters IEEE, 2000, 4(7):242~244.
[3] Minn H, Bhargava V K.Asimple and efficient timing offset estimation for OFDM systems[C]. IEEE Vehicular Technology Conference.IEEE, 2000:51~55 vol.1.
[4] Park B, Cheon H, Kang C, et al.Anovel timing estimation method for OFDM systems[J]. Communications Letters IEEE, 2003, 7(5):239~241.
[5] 高岩.基于训练序列的OFDM系统同步技术研究[D].东北石油大学,2021.
[6] G Casella, R Berger. Statistical Inference. Duxbury Press, California, 1990.
[7] J J van de Beek, M Sandell, P O Borjesson. MI. Estimation of Time and Frequency Offset in OFDM systems. IEEE Transactions on Signal Processing, Vol. 45, No. 7, July 1997.
[8] T M Schmidl, D C Cox. Low-Overhead, Low-Complexity [Burst] Synchronization for OFDM. IEEE International Conference on Communications, Vol. 3, 1996, pp. 1301-1306

















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









