






 本文介绍了如何在非Python环境中使用DQN算法进行路径规划,通过Matlab代码实现并应用于走迷宫问题,提供详尽的代码注释以便于实验和定制。
本文介绍了如何在非Python环境中使用DQN算法进行路径规划,通过Matlab代码实现并应用于走迷宫问题,提供详尽的代码注释以便于实验和定制。
DQN路径规划算法。
深度强化学习算法。
matlab代码,非python。
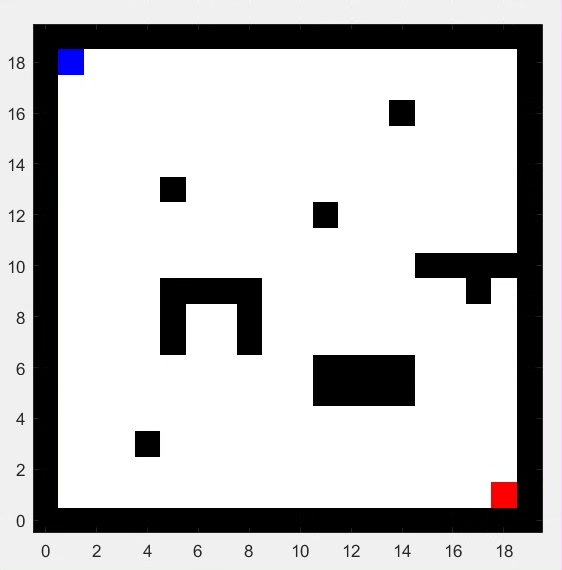
栅格环境。
走迷宫。
可以通过窗口界面方便观察交互过程。
代码注释详尽,可以方便替换自己的地图。
ID:6619767732486840
路径规划
标题:DQN路径规划算法在非Python环境下的应用
摘要:
本文基于深度强化学习算法,探讨了在非Python环境下使用DQN路径规划算法的实践。通过使用Matlab代码,并借助栅格环境进行走迷宫的实验,展示了DQN路径规划算法在非Python环境下的优势。文章中提供了窗口界面展示交互过程,并附上了详尽的代码注释,方便读者替换自己的地图。
-
引言
路径规划是许多领域中的常见问题,涉及到从起点到终点的最优路径搜索。传统的路径规划算法在复杂环境中的搜索效率较低,这激发了深度强化学习算法在路径规划领域的应用。本文旨在展示使用DQN路径规划算法在非Python环境下的实践效果。 -
算法介绍
2.1 深度强化学习算法
深度强化学习是结合了深度学习和强化学习的算法,通过神经网络模型和奖励机制来实现智能决策。在路径规划领域,利用深度强化学习可以学习到最优路径的策略。
2.2 DQN路径规划算法
DQN(Deep Q-Network)是一种基于深度神经网络的强化学习算法,使用了Q-learning算法的优化技巧。该算法通过模拟智能体在不同状态下的决策,学习到最优的行动策略。
-
非Python环境下的实践
为了在非Python环境下应用DQN路径规划算法,本文选择了Matlab作为实现工具。Matlab代码提供了对DQN算法的实现以及对栅格环境下走迷宫的支持。这一选择能满足部分研究人员对非Python语言的需求,同时也使得代码更容易上手和应用。 -
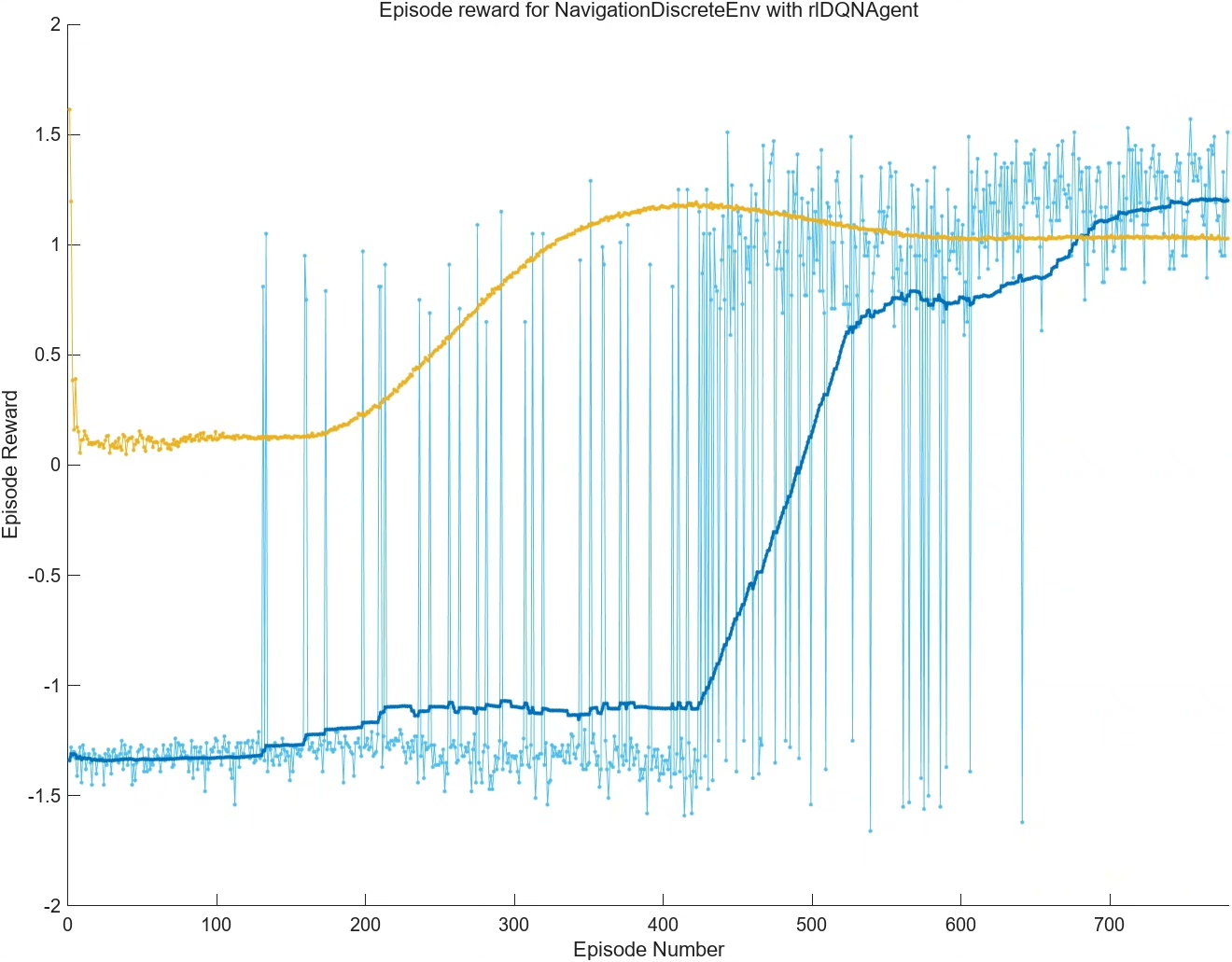
实验设计与结果展示
为了验证非Python环境下的DQN路径规划算法的效果,本文设计了一系列实验。通过窗口界面,读者可以方便地观察交互过程,并了解算法在不同环境下的表现。同时,为了方便读者进行实验,代码注释详尽,使其能够轻松替换自己的地图。 -
总结与展望
本文以DQN路径规划算法为主题,围绕非Python环境下的实践进行了探讨。通过在Matlab中实现该算法,并借助栅格环境进行走迷宫实验,展示了其在非Python环境下的优势。实验结果验证了DQN路径规划算法在非Python环境中的可行性和有效性。未来,我们将进一步优化算法细节,并尝试在更多领域应用该算法。
关键词:深度强化学习、路径规划、DQN算法、非Python环境、Matlab代码、栅格环境、走迷宫、窗口界面、代码注释
以上相关代码,程序地址:http://wekup.cn/767732486840.html















 1516
1516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









