






前言
笔者独立完成过 Ethernet/IP 协议主站(Scanner)和从站(Adapter)的开发。且开发的从站(Adapter)通过了 ODVA 官方的 Conformance Test。本文档记录笔者对于 Etherenet/IP 协议的理解。
什么是 Ethernet/IP 协议
Ethernet/IP(以太网工业协议)是一种基于以太网的工业通信协议,主要用于工业自动化和控制系统中。它由ODVA(Open DeviceNet Vendors Association)开发,并基于标准的以太网技术,结合了CIP(Common Industrial Protocol)协议,支持实时控制和信息交换。
该协议一般用于工业生产场景,用于不同的工业设备之间的通信。 例如: 根据产线要求,一个PLC连接多个机器人,以实现产线的整体启停等。 部分焊机设备也使用该协议用于焊机的控制, 例如:麦格米特焊接电源。
目前支持该协议的厂家有: 汇川,欧姆龙, Rockwell,codesys,三菱,纳博特等。
Ethernet/IP协议内容
具体的协议规范加入ODVA的会员获取,由于版权问题,这里无法提供具体的协议细节。这里讲述一下笔者所理解的 Ethernet/IP 协议。
这个协议可以简单理解为 TCP/IP + CIP 协议。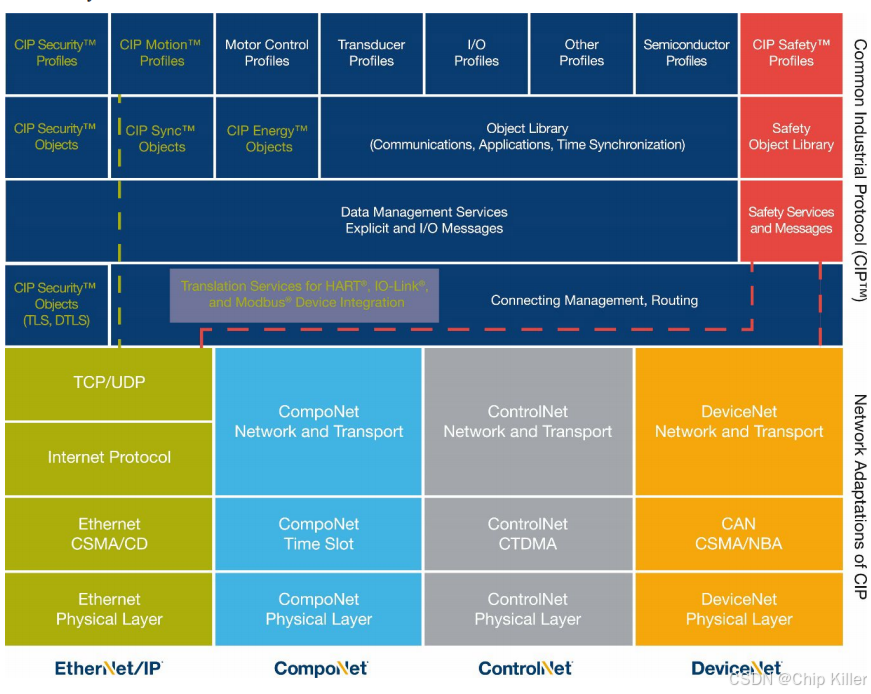
Ethernet/IP协议基于标准以太网, 它在 TCP 和 UDP 的基础上, 添加应用层协议 CIP 。
应用层协议CIP规定了Ethernet/IP从站设备的四个部分: 对象模型(Object Model),服务(Services),消息路由(Message Routing),连接管理(Connection Management).
其中最关键的是对象模型.
CIP 中的每个设备都是由多个对象(Objects)组成,每个对象都有以下属性:
Class(类): 定义对象的类型,例如 Identity Object、Connection Object 等。
Instance(实例): 类的具体实现,表示实际的设备组件。
Attributes(属性): 描述对象的状态或配置参数。
Services(服务): 提供对对象的操作(如读写、配置等)。
Ethernet/IP的消息主要有两种, 显式消息(ExplicitMessage)和 隐式消息(ImplicitMessage)。
所有的通信都是由主站发起,从站响应的。从站无法主动发起通信。
显式消息使用 TCP 进行传输, 端口一般是44818, 通信模式是请求响应模式. 主站向从站发送消息, 从站回应主站的消息. 例如主站向从站发送显示消息. 针对Class 1(Identity),的 Instance 1的Attributes 1 Vendor ID (供应商ID)执行 Services 0x0E Get_Attribute_Single(获取单个属性) 操作, 从站在收到该信息后将自己的供应商ID返回给主站. 这就是一次完整的显式消息.
隐式消息(有些厂商也叫做IO消息)使用 UDP进行传输, 端口一般是 2222. 通信的模式是连接式的. 首先主站通过显式消息向从站发起连接请求. 主要是针对 Class 6 (Connection Manager)的 Instance 1 执行 Services 0x54 Forward_Open, 主站发送连接请求时会附带连接参数等信息.从站在收到这些 Forward_Open 之后, 会根据自身的状态判断是否可以建立连接, 如果可以会通过显式消息返回给主站连接成功的信息. 随后主站和从站会按照连接参数中约定的通信周期, 周期性通过UDP的2222端口向对方发送数据.
Ethernet/IP的性能
Ethernet/IP总线的实时性是通过设置消息的 Qos 来实现的. 市面上常见的Ethernet/IP设备的实时性大部分在 5-10ms. 相比起 EhterCAT 等电机控制协议的1ms通信周期, 这个实时性还是较差的. 所以Ethernet/IP协议只能用作过程控制, 无法用于运动控制.
Ethernet/IP协议的使用方法
在工业场景中, 很少有使用显式消息的情况, 大部分情况都是主站和从站间通过隐式消息通信 (部分厂家把这个叫做 IO 连接). 这里介绍较为通用的主站连接从站的方法.
对于任何一个 Ethernet/IP 从站设备, 都会配套有一份 eds 文件(设备描述文件). 该文件记录了 从站设备 中所实现的CIP对象模型中的类的信息, 以及进行IO连接时所需参数信息.
首先将从站的 eds 文件导入主站, 然后主站通过扫描网络中从站的方式(或者手动输入的方式)获取从站的IP地址信息.
随后正常启动主站即可建立 Ethernet/IP 网络连接.
不同的主站厂商提供的导入eds文件和扫描从站的方式不一样, 请以主站厂商的用户手册为准.
Ethernet/IP协议的实现
Ethernet/IP的主站和从站都有开源的实现.
主站 EIPScanner : GitHub - nimbuscontrols/EIPScanner: Free implementation of EtherNet/IP in C++

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









