










2 Probability Distribution
概述
本章讨论的内容包括对限定观察数据集中的随机变量的概率分布进行建模,即密度估计(density estimation),这里假设所有的数据点都是独立同分布的。对于有限的观测数据集来说,有无数种可能的概率分布和其对应。关键就是要找到一种合适的分布,这就是模型选择问题,也是模式识别中的中心问题。
接下来要讨论的是离散随机变量的二项式分布和多项式分布以及连续型随机变量的高斯分布,这些都是参数分布的具体例子。之所以这么叫,是因为它们被一小部分可调整的参数控制着。要想把这些模型应用到密度估计的问题中,我们需要在被观测数据集给定的情况下,通过一个程序决定这些参数合适的值。从频率派的观点来看,就是要优化一些标准,比如似然函数。从贝叶斯的观点来看,则要找到相对观测数据的后验概率分布。在这里,共轭先验扮演了重要角色,极大地简化了贝叶斯分析。
使用参数方法的一大缺陷就是其为分布假定了一个具体的函数形式,对于特定的应用来说可能不适合。另一种方法则是无参数密度估计,其分布的形式依赖于数据集的大小,其中也有参数,但是其控制的是模型的复杂度而不是分布的形式。
2.1 Binary Variables
伯努利分布: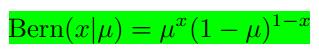
相应的期望与方差为: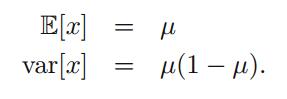
我们目前假设有一个关于
x
的观测数据集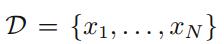
我们能够建立关于
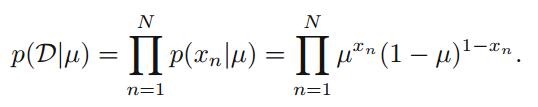
从频率派的观点出发,我们可以通过最大化似然函数或者最大化其对数来估计
μ
的值,即
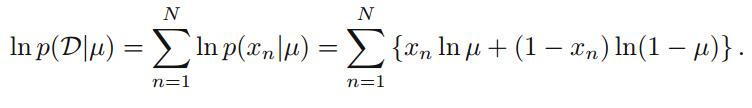
对其求关于
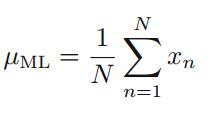
其中
N
观察数据的次数
上式相当于求平均值,如果假设
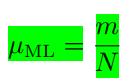
但是最大化似然函数存在一个问题,当我们抛了三次硬币,三次均朝正面时(假设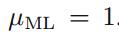
我们对
N
次抛硬币中出现

其中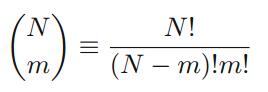
进而我们可以求出二项分布的期望和方差:
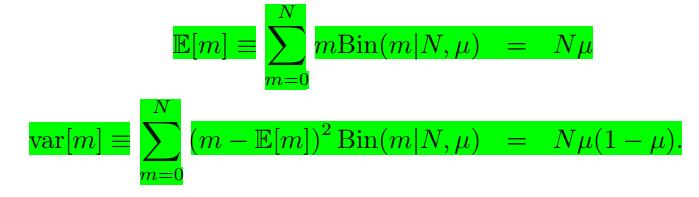
2.1.1 The beta distribution
正如上文提到的针对小数据集,使用最大化似然函数会出现过拟合结果,为了解决这个问题,我们介绍先验分布。
我们在这里选择了和似然函数有相似结构形式的先验分布——beta分布:
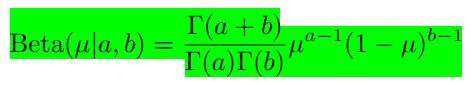
其中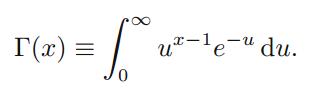
同时有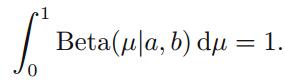
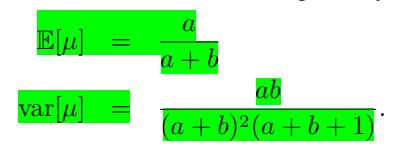
这里
a,b
被称为超参数,用来控制参数
μ
的分布
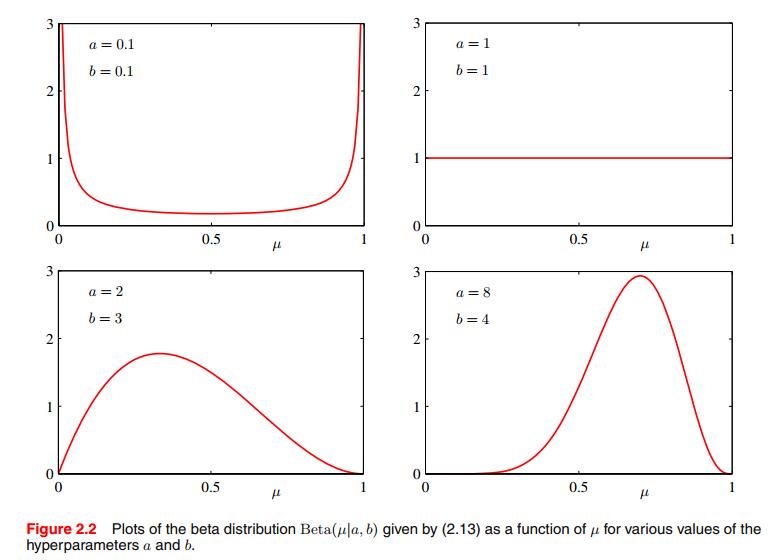
下图是对于不同的
现在我们可以将
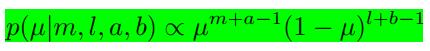
我们可以看到上式拥有和先验分布一样的函数形式,这体现了共轭性质。
最终我们通过归一化得到了后验分布:
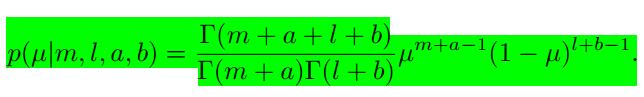
我们可以发现,从先验到后验,正面朝上的次数在
a−1
上增加了
m
,同样反面朝上的次数在
当我们随后再次观测额外的数据时,之前的后验分布就变成了先验分布,在加入新的观测数据之后又得到了新的后验分布。
下图是一个简单示例:
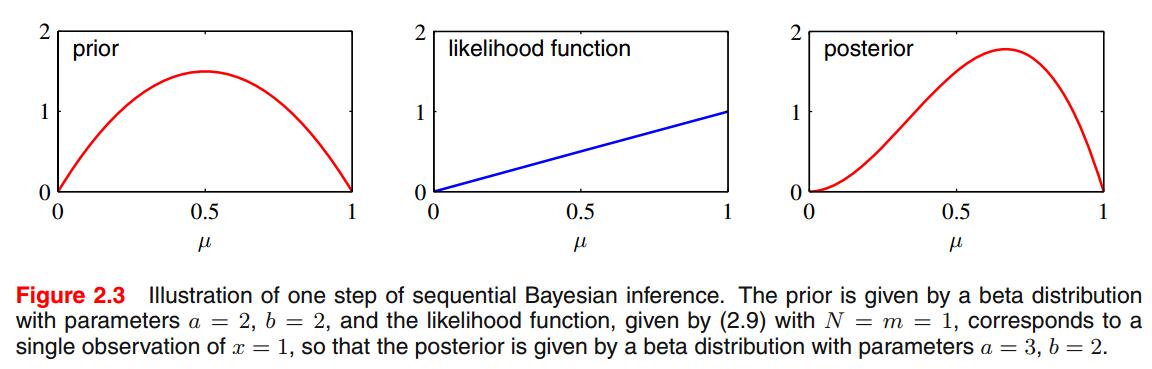
这种按次序的方式独立于先验与似然函数的选择,只依赖于独立同分布的数据假设。这种方法一次利用一小部分数据,在下一次观测数据到来之前丢掉它们,可以用在实时学习脚本中。
如果我们的目标是预测下一次抛硬币实验的结果的话,那我们必须要在以观测到的数据集
D
上估计
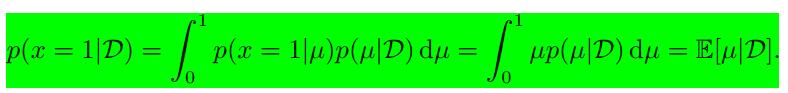
得到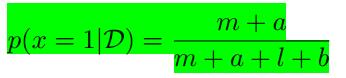
我们可以发现,当
m,l
趋于无穷时,上式的结果就会变成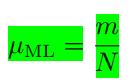
对于有限的数据集来说,
μ
值介于先验与最大似然估计之间。
我们也可以从上边Figure2.2中看到,随着观测次数的增加,后验分布变得越来越尖锐。
事实上,当我们观察的数据越来越多时,后验分布的不确定性将逐步消失。
2.2 Multinominal Variables
使用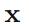
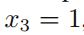
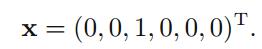
上式满足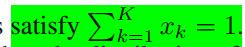


其中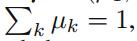
相应的有
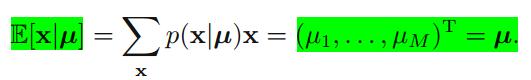
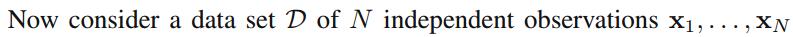
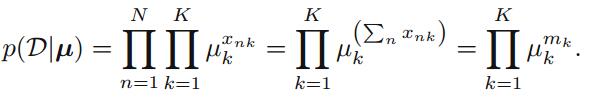
其中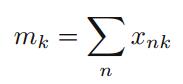
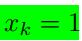
为了找到关于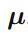
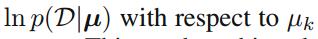
这里使用拉格朗日乘数
λ
来最大化
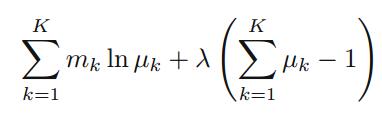
对上式求关于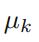
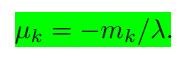
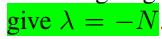
得到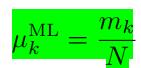
进而我们可以得到多项式分布:
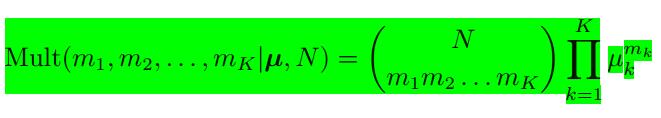
其中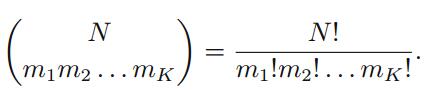
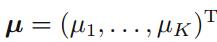
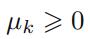
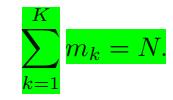
2.2.1 The Dirichlet distribution
对于多项式分布中的一族参数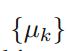
我们可以得到共轭先验的形式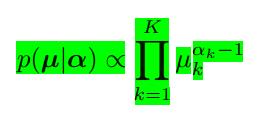
这里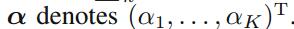
由于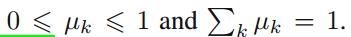
所以
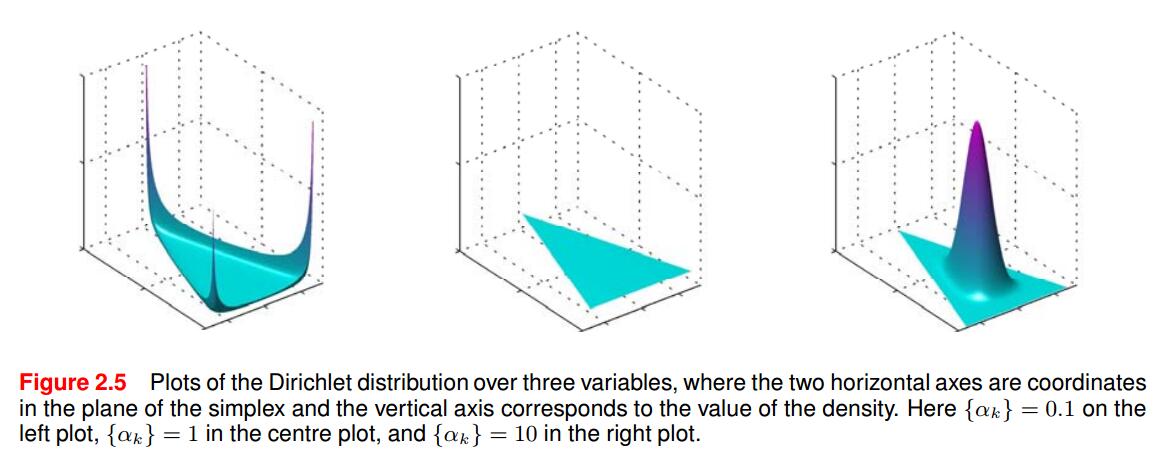
下图为
K=3
时候的情况

归一化后的狄利克雷分布为:
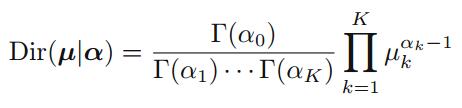
其中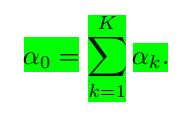
对于
先验与似然相乘就得到了后验:
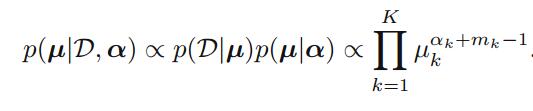
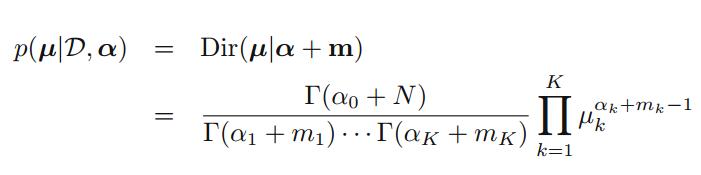
其中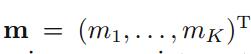
而且可以发现beta分布是
K=2
时的Dirichlet分布















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









