







这段时间做动作识别,由于硬件设备的要求,测试了许多特征和分类器来完成动作识别,到现在为止,虽然还没有找到一个有效的方法解决当前的问题,但是还是要把这些知识汇总一下,作为归纳学习总结,各位看官走过、路过,鄙人属于菜鸟一枚,如果有问题请指点出来,轻拍。
尝试过的特征有hog特征、hu距、LBP和一个芯片自带的BinaryFeature特征,先从最简单的BinaryFeature说起吧:
void getBinaryFeature2(cv::Mat &grayImg, double *pfBinaryfeature)
{
char line[512];
ofstream predict_txt("feature.txt");//把预测结果存储在这个文本中
int i, j;
int m, n;
int u16FeatureNum = 0;
/*int sum = 0;*/
cv::Mat_<uchar>im = grayImg;
for (i = 0; i < grayImg.rows - STEP + 1; i += STEP)
{
for (j = 0; j < grayImg.cols - STEP + 1; j += STEP)
{
int sum = 0;
for (m = i; m < i + STEP; m++)
{
for (n = j; n < j + STEP; n++)
{
sum += im(m, n);
}
}
pfBinaryfeature[u16FeatureNum] = (double)sum / (STEP*STEP * 255);
std::sprintf(line, "%f ", pfBinaryfeature[u16FeatureNum]);
predict_txt << line;
u16FeatureNum++;
}//pfBinaryfeature中存放每幅图像的4*4特征
}
predict_txt.close();
}
2. LBP特征
由于芯片中自带的有LBP特征接口,所以有考虑到使用这个特征。原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。后来研究人员又对LBP算子做了许多改进,在这里就不一一讲述了。
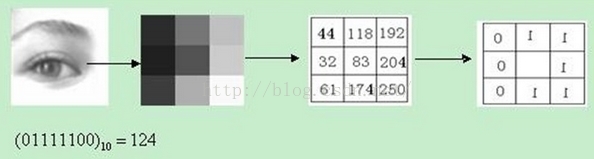
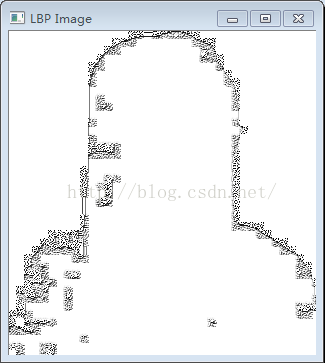
使用该特征时,由于mei图像本身已是二值图像,对其处理后得到的是一幅类似于边缘的图像,按理书也可以使用,但是由于进行测试的大小为64*64(太小则效果很差)得到的LPB的特征值个数为(64-2)*(64-2),已经超过了芯片要求的256范围,所以此处无法使用。下图为原始图像和用LBP算子处理后的图像。

template <typename _Tp> static
void lbp_(InputArray _src, OutputArray _dst) {
// get matrices
Mat src = _src.getMat();
// allocate memory for result
_dst.create(src.rows - 2, src.cols - 2, CV_8UC1);
Mat dst = _dst.getMat();
// zero the result matrix
dst.setTo(0);
cout << "rows " << src.rows << " cols " << src.cols << endl;
cout << "channels " << src.channels();
//getchar();
// calculate patterns
for (int i = 1; i<src.rows - 1; i++) {
//cout << endl;
for (int j = 1; j<src.cols - 1; j++) {
_Tp center = src.at<_Tp>(i, j);
//cout<<"center"<<(int)center<<" ";
unsigned char code = 0;
code |= (src.at<_Tp>(i - 1, j - 1) >= center) << 7;
code |= (src.at<_Tp>(i - 1, j) >= center) << 6;
code |= (src.at<_Tp>(i - 1, j + 1) >= center) << 5;
code |= (src.at<_Tp>(i, j + 1) >= center) << 4;
code |= (src.at<_Tp>(i + 1, j + 1) >= center) << 3;
code |= (src.at<_Tp>(i + 1, j) >= center) << 2;
code |= (src.at<_Tp>(i + 1, j - 1) >= center) << 1;
code |= (src.at<_Tp>(i, j - 1) >= center) << 0;
dst.at<unsigned char>(i - 1, j - 1) = code;
}
}
}int main()
{
Mat face2 = imread("D:\\CapVideoProc\\test_img\\76.jpg", CV_LOAD_IMAGE_ANYDEPTH | CV_LOAD_IMAGE_ANYCOLOR);//hand_up91
Mat lbp_face2 = Mat::zeros(face2.size(), face2.type());
lbp_<uchar>(face2, lbp_face2);
namedWindow("image", 1);
imshow("image", face2);
namedWindow("LBP Image", 1);
imshow("LBP Image", lbp_face2);
waitKey();
return 0;
}3. Hu距
关于Hu距,使用Hu距的主要原因是因为其阶数只有七阶,也就是说用这个为SVM分类器训练生成.xml文件时,其向量维数为7,满足芯片的维数要求,可是问题就出来了,我用Hu做特征使用贝叶斯分类器时,其结果良好,可以接近准确的识别站立、举手动作,换成SVM分类器时其结果就很差。仔细研究了一下是因为我为SVM训练生成xml文件时样本数量太少了,别人都用几千几万个样本,而我为了便于芯片实现,节省代码执行时间只用了百十来个,所以导致结果很差(所有动作都识别为同一个动作),其次因为考虑到要在硬件芯片上实现和Hu距起主要作用的是前三阶距的缘故,我计算Hu距时我只计算了前三阶,可能训练的向量维数太少对SVM的预测结果影响也很大,考虑由于这两个原因导致我的识别结果很差。
参考代码:点击打开链接















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









