







为了方便管理集群,可制作一些工具脚本,比如jpsall,xsync等,下面会说明自制过程。
查看集群JVM进程:jpsall
- 创建jpsall脚本
hadoop@ubuntu2:~/Scripts$ vim jpsall
#!/bin/bash
for host in ubuntu2 ubuntu3 ubuntu4
do
echo ============= $host ==========
ssh hadoop@$host /opt/jdk1.8.0_211/bin/jps
done
- 修改脚本jpsall具有执行权限
hadoop@ubuntu2:~/Scripts$ chmod 777 jpsall - 执行脚本jpsall
hadoop@ubuntu2:~/Scripts$ ./jpsall
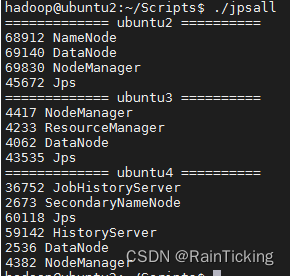
集群文件分发:xsync
- 创建xsync脚本
hadoop@ubuntu2:~/Scripts$ vim xsync
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
if [ -e $1 ]
then
p1=$1
fname=`basename $p1`
echo fname=$fname
else
echo $fname does not exists!
exit;
fi
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for host in ubuntu2 ubuntu3 ubuntu4 ; do
ssh $host "mkdir -p $pdir"
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $host:$pdir
done
- 修改脚本xsync具有执行权限
hadoop@ubuntu2:~/Scripts$ chmod 777 xsync - 执行脚本xsync,分发Spark配置文件
hadoop@ubuntu2:~/Scripts$ ./xsync /opt/spark-3.0.0-bin-hadoop2.8/conf/spark-env.sh
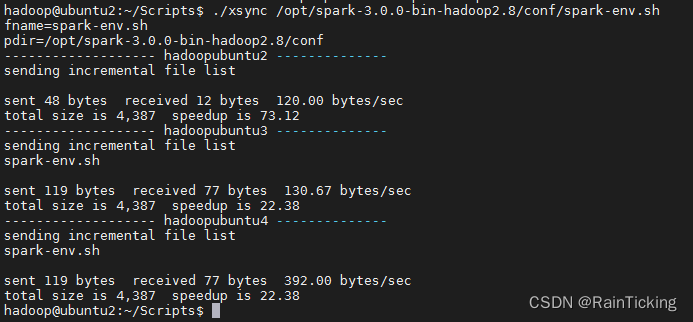
脚本任意位置可执行
要想让脚本在任意位置可执行,就像linux命令ls、pwd等一样,需要将这些命令所对应的可执行文件所在的目录加到 PATH 环境变量里
- 修改环境变量配置文件,添加脚本路径
hadoop@ubuntu2:~$ vim /etc/profile.d/my_env.sh
export SCRIPTS=$HOME/Scripts
export PATH=$SCRIPTS:$PATH
-
使环境变量生效
hadoop@ubuntu2:~$ source /etc/profile -
查看jpsall命令是否其他位置可执行:
hadoop@ubuntu2:~$ jpsall
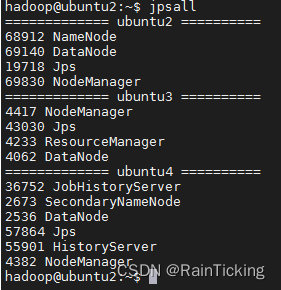
启动集群 start-cluster
#!/bin/bash
# 启动HDFS
/opt/hadoop-2.7.1/sbin/start-dfs.sh
# 启动YARN
ssh hadoop@ubuntu3 /opt/hadoop-2.7.1/sbin/start-yarn.sh
# 启动MR历史服务
ssh hadoop@ubuntu4 /opt/hadoop-2.7.1/sbin/mr-jobhistory-daemon.sh start historyserver
# 启动Spark历史服务
ssh hadoop@ubuntu4 /opt/spark-3.0.0-bin-hadoop2.8/sbin/start-history-server.sh
# 查看已启动服务
jpsall















 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









