







机器学习算法按照学习方式分类,可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、半监督学习(Semi-supervised Learning)、强化学习(Reinforcement Learning)。
按照学习策略分类,可以分为机械学习、示教学习、类比学习、基于解释的学习、归纳学习。
按照学习任务分类,可以分为分类、回归、聚类。
按照应用领域分类,可以分为自然语言处理、计算机视觉、机器人、自动程序设计、智能搜索、数据挖掘和专家系统。
监督学习
监督学习的定义
监督学习是指在给定的训练集中“学习”出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入和输出,即特征值和目标值(标签),训练集中数据的目标值(标签)是由人工事先进行标注的。
监督学习流程图如下图所示,其中包括准备数据、数据预处理、特征提取和特征选择、训练模型和评价模型。
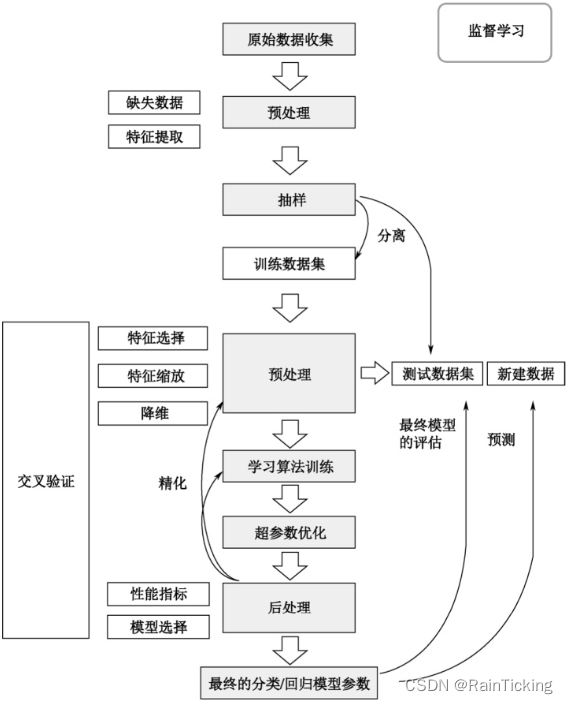
Step1:准备数据。
监督学习首先要准备数据,没有现成的数据就需要采集数据或者爬取数据,或者从网站上下载数据。可以将准备好的数据集分为训练集、验证集和测试集。训练集是用来训练模型的数据集,验证集是确保模型没有过拟合的数据集,测试集是用来评估模型效果的数据集。
Step2:数据预处理。
数据预处理主要包括重复数据检测、数据标准化、数据编码、缺失值处理、异常值处理等。
Step3:特征提取和特征选择。
特征提取是结合任务自身特点,通过结合和转换原始特征集,构造出新的特征。特征选择是从大规模的特征空间中提取与任务相关的特征。特征提取和特征选择都是对原始数据进行降维的方法,从而去除数据的无关特征和冗余特征。
Step4:训练模型。
模型就是函数,训练模型就是利用已有的数据&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









