









目录
1.部署所需环境
- JDK
- zookeeper
- hadoop
2.集群规划
| 机器 | 服务 |
|---|---|
| 192.168.179.131 (01.weisx.com) | Master、Worker |
| 192.168.179.132 (02.weisx.com) | Worker |
| 192.168.179.133 (03.weisx.com) | Worker |
以下第3到8步操作在192.168.179.131服务器上操作
3.解压,配置环境变量
1 )拷贝Spark安装包到01节点~/tools/目录
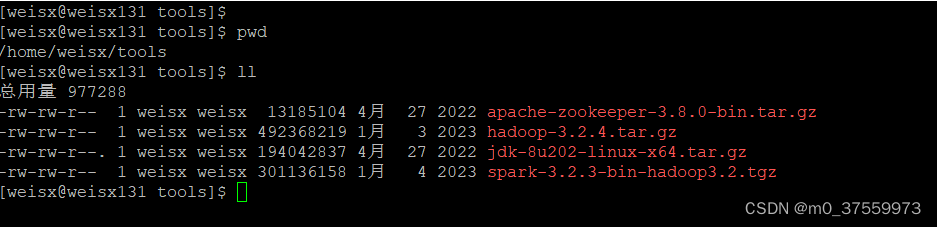
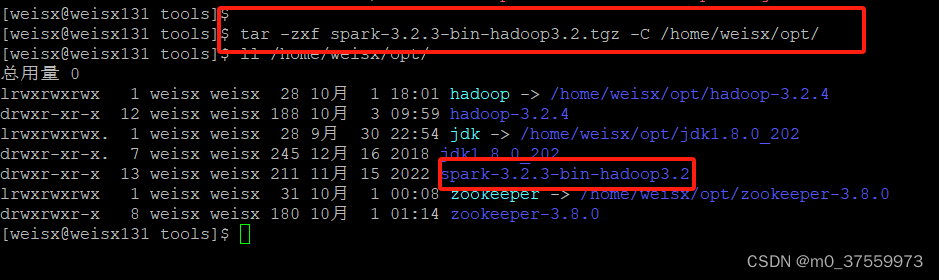
2)解压到~/opt/目录
tar -zxf spark-3.2.3-bin-hadoop3.2.tgz -C /home/weisx/opt/
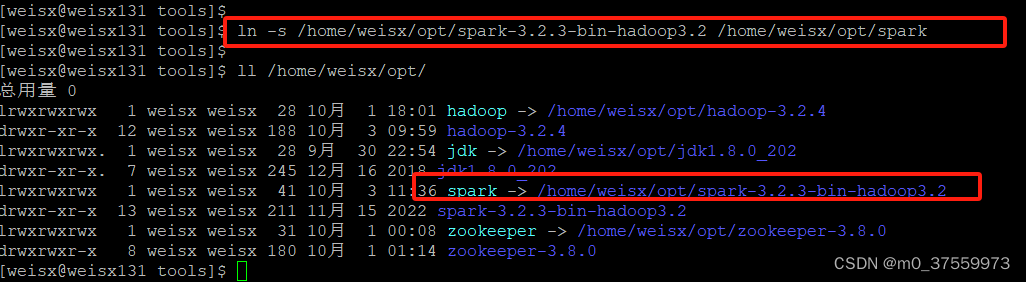
3)创建Spark软链接
ln -s /home/weisx/opt/spark-3.2.3-bin-hadoop3.2 /home/weisx/opt/spark
4 )配置环境变量
vi ~/.base_profile
#使环境变量生效: source ~/.bash_profile
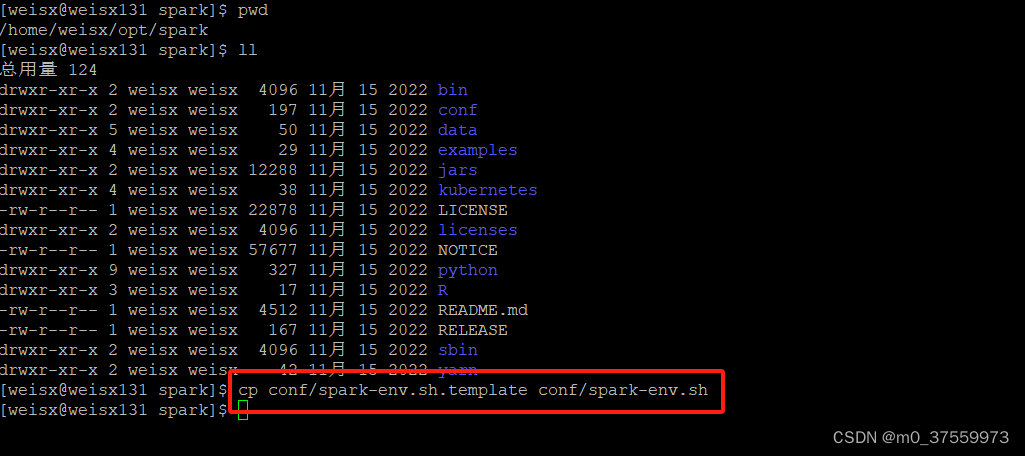
5.配置Master
1) 将spark-env.sh.template 文件复制一份并命名为 spark-env.sh
2)配置JAVA_HOME环境变量及master节点信息,Standalone模式还需要设置SPARK_LOCAL_IP变量


6.配置Worker
1) 将slaves.template 文件复制一份并命名为 slaves

2)配置worker节点信息

7.配置历史服务
1)将spark-defaults.conf.template 文件复制一份并命名为spark-defaults.conf

2) 修改spark-defaults.conf文件,配置日志存储路径

注意:hadoop的 spark-log目录需要提前创建
3)修改 spark-env.sh 文件, 添加日志配置

参数1:WEB UI 访问的端口号为 18080
参数2:指定历史服务器日志存储路径
参数3:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
8.分发Spark到其他worker服务器
scp -r /home/weisx/opt/spark-3.2.3-bin-hadoop3.2 02.weisx.com:~/opt
scp -r /home/weisx/opt/spark-3.2.3-bin-hadoop3.2 03.weisx.com:~/opt
以下第9步操作在192.168.179.132服务器上操作
9.配置第二台服务器的Spark
1 ) 创建Spark软链接
ln -s /home/weisx/opt/spark-3.2.3-bin-hadoop3.2 /home/weisx/opt/spark

2)修改SPARK_LOCAL_IP变量

3)配置环境变量
vi ~/.base_profile
#使环境变量生效: source ~/.bash_profile
以下第10步操作在192.168.179.133服务器上操作
10.配置第三台服务器的Spark
1 ) 创建Spark软链接
ln -s /home/weisx/opt/spark-3.2.3-bin-hadoop3.2 /home/weisx/opt/spark

2)修改SPARK_LOCAL_IP变量

3)配置环境变量
vi ~/.base_profile
#使环境变量生效: source ~/.bash_profile
以下第11步操作在192.168.179.131服务器上操作
11.启动Spark集群
1)执行启动脚本:./sbin/start-all.sh(hadoop也有start-all.sh和stop-all.sh脚本,如果spark和hadoop部署在同一台服务器,需要脚本路径)

2)启动历史服务: ./sbin/start-history-server.sh

3)Web 端查看 Spark的 Master信息
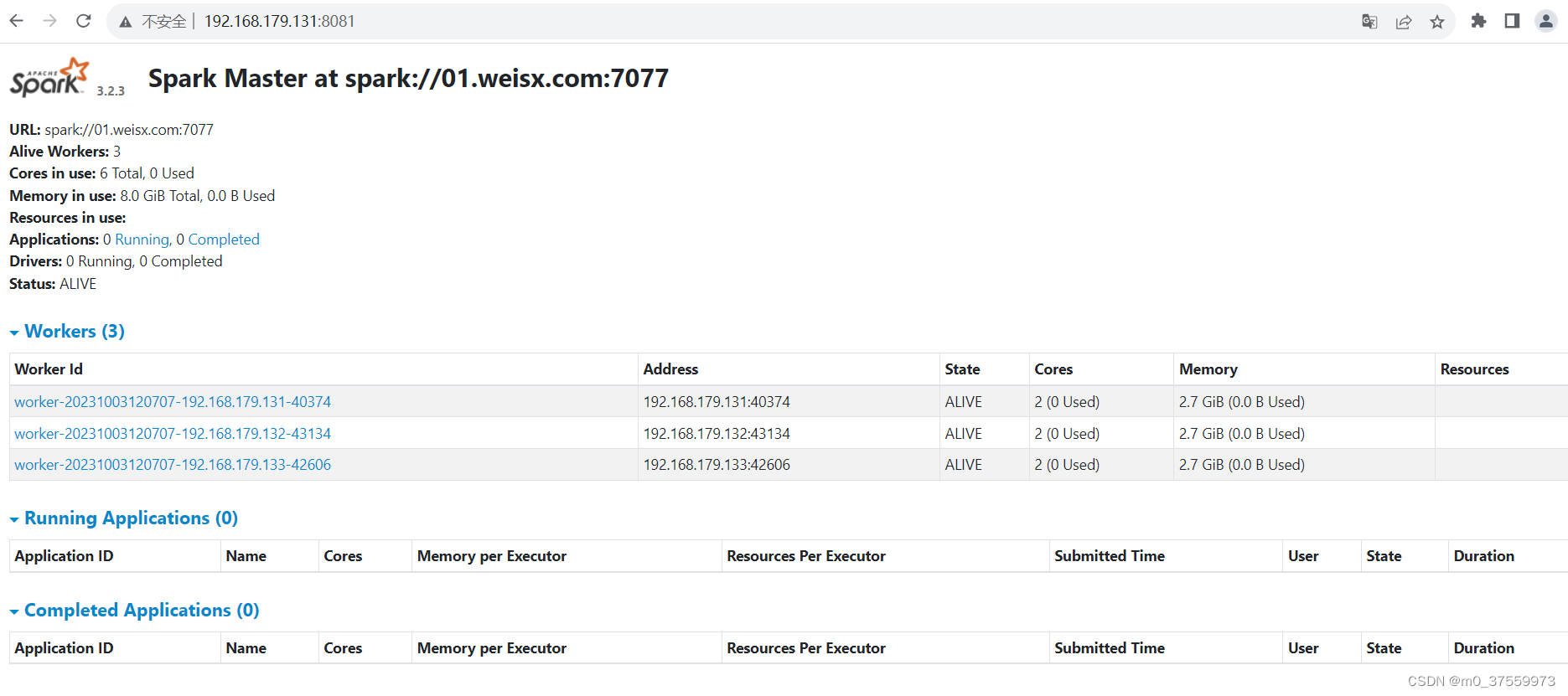
4)Web 端查看 Spark的 历史信息

12.测试Spark集群
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://01.weisx.com:7077 ./examples/jars/spark-examples_2.12-3.2.3.jar 10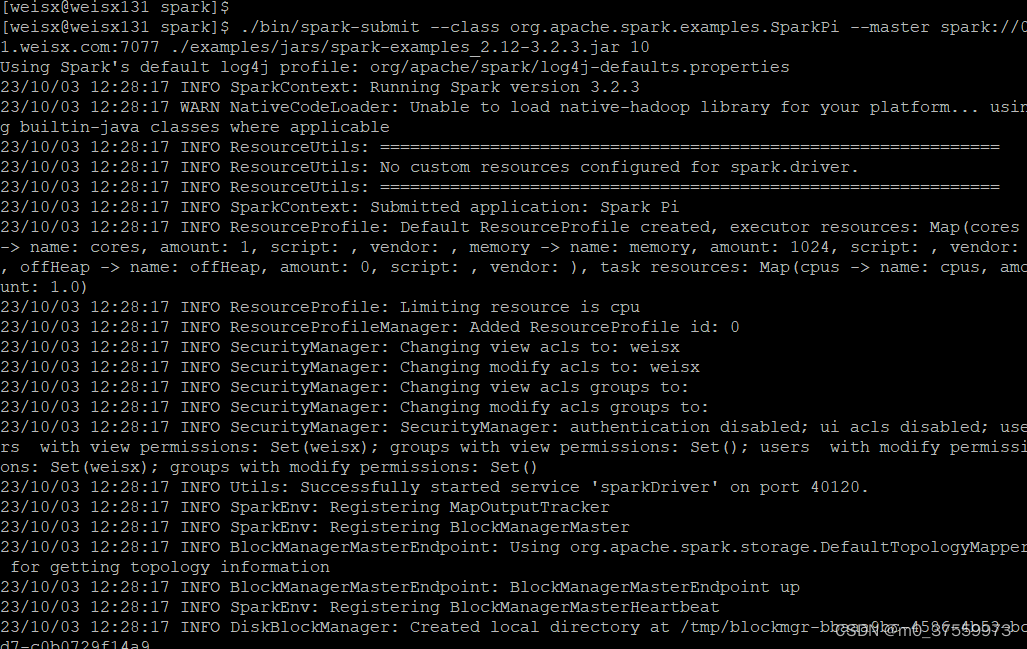
1) --class 表示要执行程序的主类
2) --master spark://01.weisx.com:7077 独立部署模式,连接到 Spark 集群
3) spark-examples_2.12-3.2.3.jar 运行类所在的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量















 4328
4328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











