







数据类型
什么是数据类型,为什么会有数据类型
数据类型是用于描述不同类型的数据存放在内存中的形式
**以睁眼(1)闭眼(0)形式描述,整数,那英文呢? **
数据类型分类:
1.整型(短整型,整型,长整型,长长整型,无符号短整型,无符号整型,无符号长整形,无符号长长整型)
2.
- 什么是数据?
- 有用的信息称为数据
- 数据如何存储在内存
1. 确认数据的类型 10 3.14 'a' '1' "10" "100" 'a'
2. 根据数据的类型在c语言中确认分配的数据类型 int char float double
3. 确认分配的空间是否满足数据的存放 char:1字节 short 2字节 int 4字节

- 字节(byte B):计算机存储容量的一种单位
- 比特位(bit) :二进制数,cpu计算的基本单位
- 二进制数 0 1
- 1字节 = 8位
- 1个千字节(KB) = 1024字节
- 1M = 1024KB
- 1G = 1024M
- 1T = 1024G
1.整型
-
概念:表达数据类型的数据
-
语法
int a = 123; // 定义一个专门用来存储整数的变量a int = 4个字节 -
需要注意的地方:
-
int 的本意是integer,即整数的意思
-
int a代表在内存中开辟一块区域,称为a,用来存放整数,a称为变量
-
-
变量a所占用的内存大小,在不同的系统中是不一样的,64位系统典型的大小是4字节。
- 变量a有固定的大小,因此也有取值范围,典型的范是:-2147483648到2147483647。
-
整型修饰符
-
short:用来缩短整型变量的尺寸,减少取值范围并节省内存,称为整型。
-
long:用来增长整型变量的尺寸,增大取值范围并占用更多的内存,称为长整型
-
long long:用来增长整型变量的尺寸,增大取值范围并占用更多的内存,称为长长整型
-
unsigned:用来去除整型变量的符号位,使得整型变量只能表达非负整数
short int a; // 短整型 %hd half long int b; // 长整型 %ld long long int c; // 长长整型 %lld unsigned int e; // 无符号整型 %u unsigned short int f; // 无符号短整型 %hu unsigned long int g; // 无符号长整型 %lu unsigned long long int h; // 无符号长长整型 %llu
-
-
使用整型修饰符后,关键字int可以省略:
short a; // 短整型
long b; // 长整型
long long c; // 长长整型
unsigned e; // 无符号整型
unsigned short f; // 无符号短整型
unsigned long g; // 无符号长整型
unsigned long long h; // 无符号长长整型
格式控制符
-
int 整型:%d -2^31 — + 2^31-1
-
short整型:%hd,h代表half,即一半的存储字节 printf(“xxxx”)—>log
-
long整型:%ld
-
long long整型:%lld
-
显示不同进制的前缀 : %#o、%#x
-
符号位:
- 有符号的整型数据,首位为符号位,0表示正数,1表示负数。
- 无符号的整型数据,没有符号位
练习:
定义以上类型的数据19,通过格式控制符输出
#include <stdio.h>
int main(int argc, char const *argv[])
{
// 1字节,8位,最高位为有效位,数据位7位
// 数据范围是 -128 - +127
char a = 10;
printf("%hhd\n",a);//half half
unsigned char a1 = 10;
printf("%hhu\n",a);//half half
char ch = 'a';
printf("%c\n",ch);
printf("%hhd\n",ch);
short b = 10; // short int
printf("%hd\n",b);
unsigned short b1 = 10; // unsigned short int
printf("%hu\n",b);
int c = 10;
printf("%d\n",c);
unsigned int c1 = 10;
printf("%u\n",c1);
long int d = 10;
printf("%ld\n",d);
long long d1 = 10;
printf("%lld\n",d1);
return 0;
}
- 数据类型的取值范围
unsigned char 0~255(1111 1111)
char -128... + 127(0111 1111)
short -32768~32767
unsigned short 0~65535(1111 1111 1111 1111) 2^16-1
unsigned int 0... 2^32-1 4294967295
-
编码形式:
- 原码:正数直接使用二进制来表达,比如a=100,在内存中是00…001100100
- 补码:负数用绝对值取反加一来表达,比如a=-3,在内存中是11…1111111101
-
注意负数的补码在取反加一的时候,符号位是不变的

总结

练习2 : short a = -15
1111 0001
1.当编译器以整型输出的时候%d,是以补码还原的方式解读 -1
2.当cpu将数据进行运算的时候,直接以内存中存放的方式来运行,也就是以补码的方式参与运算
3.%u输出的时候,值区域范围:0-4294967295(有符号转为无符号的时候)
4.%hhu方式打印,值域范围:0-255
(1)
unsigned char a = 255;// 0 - 255
char b = 255; // -128 - +127
printf("%d , %u\n",a,a);// 255 255
printf("%d , %u\n",b,b);// -1 4294967295
(2)
unsigned short a = -1;// 0-65535
int b = a;
printf("a = %d\n",a);//65535
printf("b = %u\n",b);//65535
(3)
unsigned char a = -1;// 0-255
unsigned int b = -1; // 0-4294967295
printf("a = %d,b = %u\n",a,b);//255,4294967295
(1)b
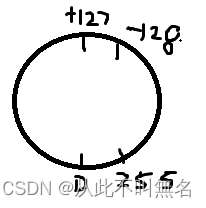
(2)a
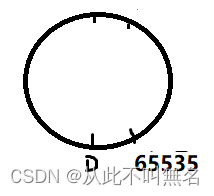
-
溢出:
-
超出数据所能表达的范围,称为溢出,就像汽车里程表,最大值和最小值是相邻的

unsigned char a = 257; char b = 129; printf("a:%hhu\n",a);//half 1 // 练习 printf("b:%hhd\n",b);//-127 // 作业1 printf("b:%hhu\n",b); //129 -
-
进制:源码中可以使用八进制、十进制或者十六进制,但实际数据中一律是二进制
- 十进制(默认),比如1234 %d %u
- 八进制,比如013 %o
- 十六进制,比如0x6FF0A %x
-
进制转换
-
十进制–》二进制、八进制、十六进制
-
十进制转二进制除2取余数,倒序排序,高位补0

十进制转八进制
除8取余,倒叙排序

则12(10)=14(8).
在编程语言中,一般使用0开头来表示八进制,如上例中的十 进制数12就可以写成014。 -
-
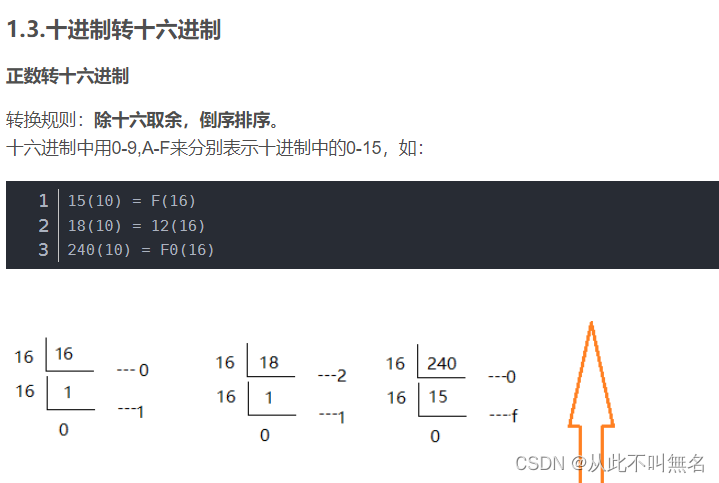
二进制八进制十六进制转十进制
小数转二进制
使用最小二乘法

练习3:(自己总结的常考)
(179)10转2进制
(179)10转8进制
(179)10转16进制
(10011011)2 转十进制
(125)8转十进制
(B78)16转十进制
小数转二进制
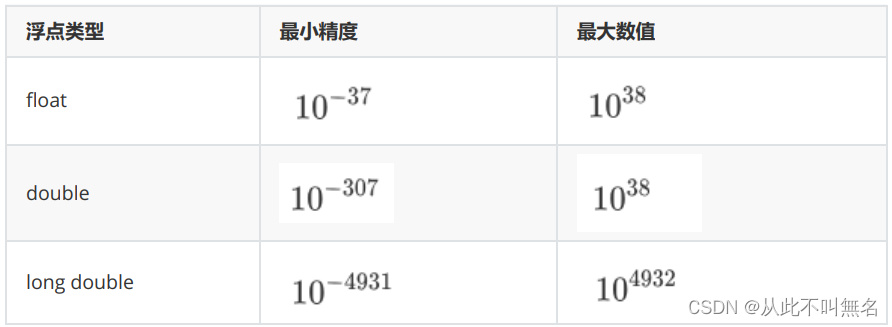
2.浮点型
- 概念:用来表达实数(有理数和无理数)的数据类型
https://www.cnblogs.com/jack-ping/articles/12174949.html
博客园大佬的文章
[浮点数在内存中的存放方式][https://www.cnblogs.com/jack-ping/articles/12174949.html]
-
分类:
- 单精度浮点型(float),典型尺寸是4字节
- 双精度浮点型(double),典型尺寸是8字节
- 长双精度浮点型(long double),典型尺寸是16字节
- 占用内存越多,能表达的精度越高
float f1;//单精度 double f2;//双精度 long double f3;//长双精度
demo
double f1 = 3.1415926; // 8字节
// 默认是四舍五入保持小数点后6位
printf("%lf\n",f1);
// 输出小数点后2两位
printf("%.2lf\n",f1);
// 输出小数点后4位,保留四舍五入的特性
printf("%.4lf\n",f1);
printf("%.7lf\n",f1);
float f2 = 3.1415; // 4字节
printf("%.4f\n",f2);
// 32位系统,占用12字节
// 64位系统,占用16字节
printf("%ld\n",sizeof(long double));
// 因为32系统,适配不上long double 必须要使用64位系统
long double f3 = 3.1415926123;
printf("%.10Lf\n",f3);
「练习1」
指出下列常量的类型
'\b' 字符
1066 整型
99.44 浮点型
0XAA 十六进制的整型
2.0e30 2.0 *10^30
0x00EEABCDUL 十六进制的无符号长整形
3.字符
char ch1 = 'a'; // 'a'是字符常量,代表字母a
char ch2 = '\n'; // '\n'是不可见字符常量,代表回车
计算机中存储都是1和0,因此各种字符都必须被映射位某个数字才能存储到计算机中,这种映射关系形成的表称为ASCII码表。
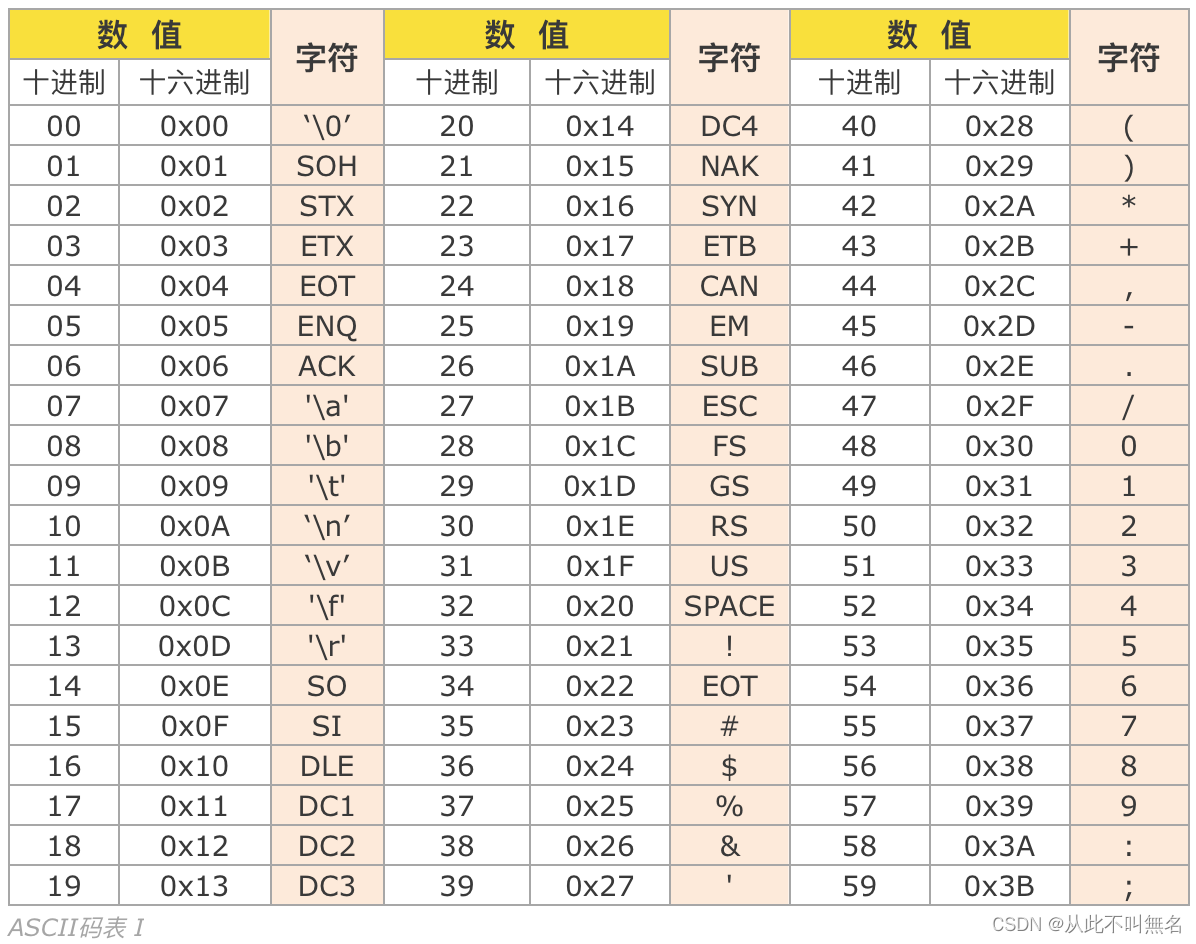
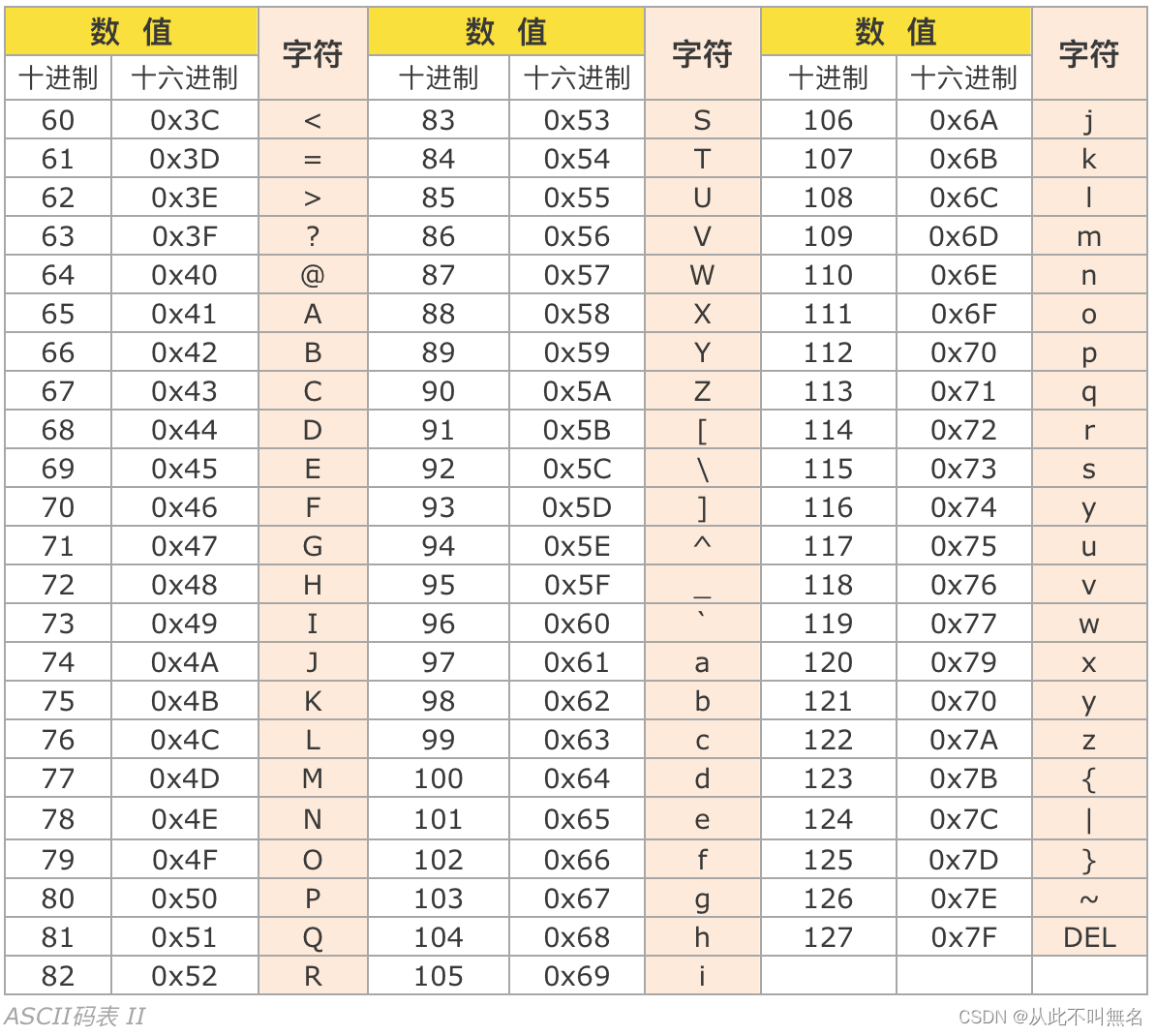
字符本质上就是一个单字节的整型,支持整型所有的运算。比如:
char a = 'a';// 存储在内存中是97
char b = '1';// 存储在内存中是49
char c1 = 20;
char c2 = c1 + 'a'; // 等价于char c2 = 20+97;
printf("%c\n",c2); // 以字符形式输出117,即 'u'
printf("%d\n",c2); // 以整型形式输出117
// 小写字符转大写字符 ' ' = 32
char a7 = 'b'- ' ';
printf("%c\n",a7);
转义字符
转义字符,所有的ASCII码都可以用\加数字(一般是8进制数)来表示,而在C中
定义了一些字母前加\来表示常见的哪些不能显示ASCII字符,如\0,\t,\n称为转义字符,因为后面的字符,都不是它本来的ASCII字符意思
当编译器遇到转义字符的时候,会用特殊的方式进行处理,'\n'表示换行
'\b' : 表示退格符
printf("abcd\b");
printf("bcde\n");
'\a': 表示告警,主板蜂鸣器
'\t': tab键
'\ddd' ddd 表示八进制数,打印出来的是该数字对应的ascii码
格式为'\'后面有三个数,每个数的范围在 0 - 7
printf("%c\n",'\102');// 八进制
printf("%d\n",'\102');
'\xhh'hh 表示十六进制 打印出来的是该数字对应的ascii码
printf("%c\n",'\41');//A
4.字符串
- 定义
// 字符串的定义方式有两种:指针和数组
char *s1 = "abcd"; // 使用字符指针来表示字符串
char s2[5]= "abcd"; // 使用字符数组来表示字符串
// 注意,使用数组来定义字符串时,方括号[]里面的数字可以省略
// 不省略也可以,但必须必字符串实际占用的内存字节数要大,比如:
char s3[] = "apple";
-
在内存中的存储
- 在内存中实际上是多个连续字符的组合
- 任何字符串都以一个’\0’作为结束标记,例如:"funny story"的内存如下

字符串的内部存储细节
demo:
#include <stdio.h>
int main(int argc, char const *argv[])
{
char *s1 = "abcd";
s1 = "def";
// 输出s1与def的d的地址
printf("%p,%p,%c\n",s1,"def", *(s1+ 1));
//*(s1+1) = 'o'; // 错误的,不能修改常量的值
printf("%s\n",s1); // 输出字符串遇到'\0'结束
char s2[] = "def";
*(s2+1) = 'o';
printf("%s\n",s2); // 输出字符串遇到'\0'结束
return 0;
}
5.布尔类型数据
- 概念:布尔型数据只有真、假两种取值,非零为真,零为假。
- 语法:
bool a = 1; // 逻辑真,此处1可以取其他任何非零数值
bool b = 0; // 逻辑假 c
#include <stdio.h>
#include <stdbool.h>
int main(int argc, char const *argv[])
{
// bool类型表示0为假,非0为真
bool flage = true; // true 为1
flage = false; // false 为0
printf("%d\n",flage);
flage = -2;
printf("%d\n",flage);
return 0;
}
-
注意:
- 逻辑真除了 1 之外,其他任何非零数值都表示逻辑真,等价于 1。
- 使用布尔型 bool 定义变量时需要包含系统头文件 stdbool.h。
-
布尔型数据常用语逻辑判断、循环控制等场合。
6.常量与变量
- 概念:不可改变的内存称为常量,可以改变的内存称为变量
- 举例:
int a = 100; // a是变量,而100是整型常量
float f = 3.14; // f是变量,而3.14是浮点常量
char s[] = "abcd"; // s是变量,"abcd"是字符串常量
char ch = 'a';// ch是变量,'a'是字符常量
- 常量的类型
| 常量举例 | 说明 | 类型 |
|---|---|---|
| 100 | 整型 | int |
| 100L | 长整型 | long |
| 100LL | 长长整型 | long long |
| 100ULL | 无符号长长整型 | unsigned long long |
| 3.14 | 双精度浮点型 | double |
| 3.14L | 长双精度浮点型 | long double |
| ‘a’ | 字符型 | char |
| “abcd” | 字符指针(字符串) | char * |
#include <stdio.h>
int main(int argc, char const *argv[])
{
printf("%d\n",100);
printf("%ld\n",100L);
printf("%lld\n",100LL);
printf("%u\n",100U);
printf("%lu\n",100UL);
printf("%f\n",3.14);
printf("%Lf\n",3.14L);
return 0;
}
7.标准输入
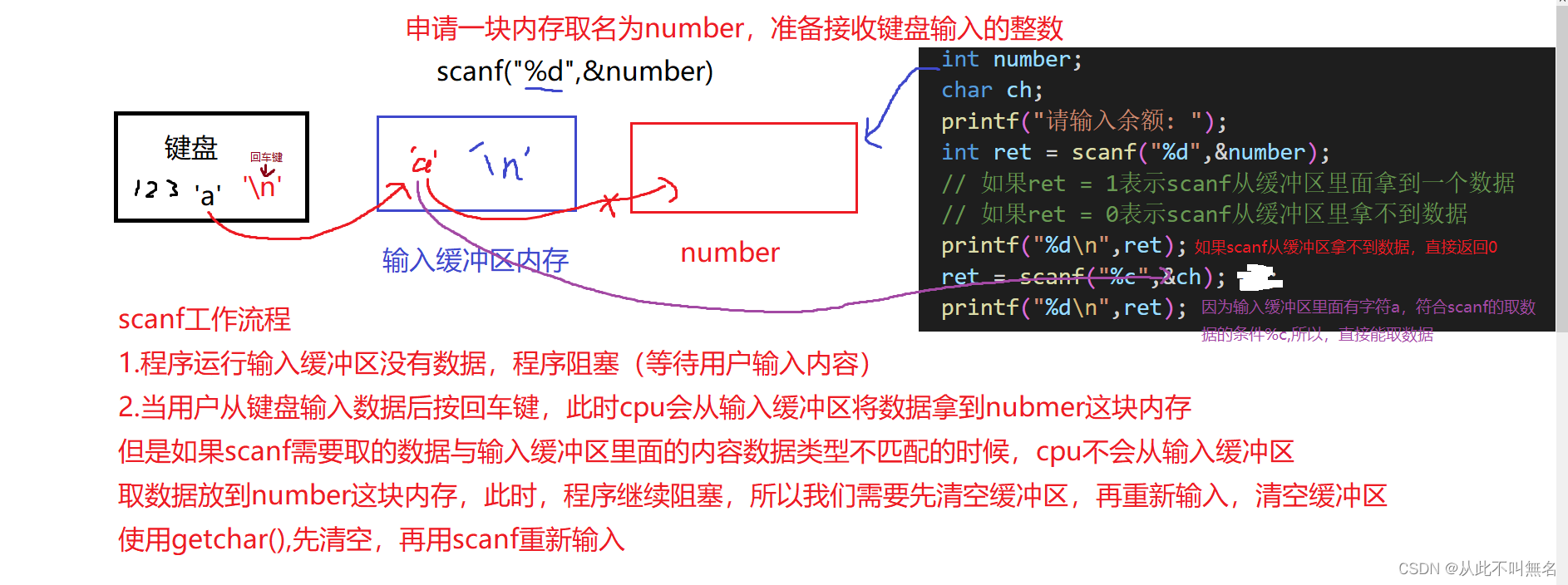
- 概念:键盘是系统的标准输入设备,从键盘中输入数据被称为标准输入
- 相关函数:
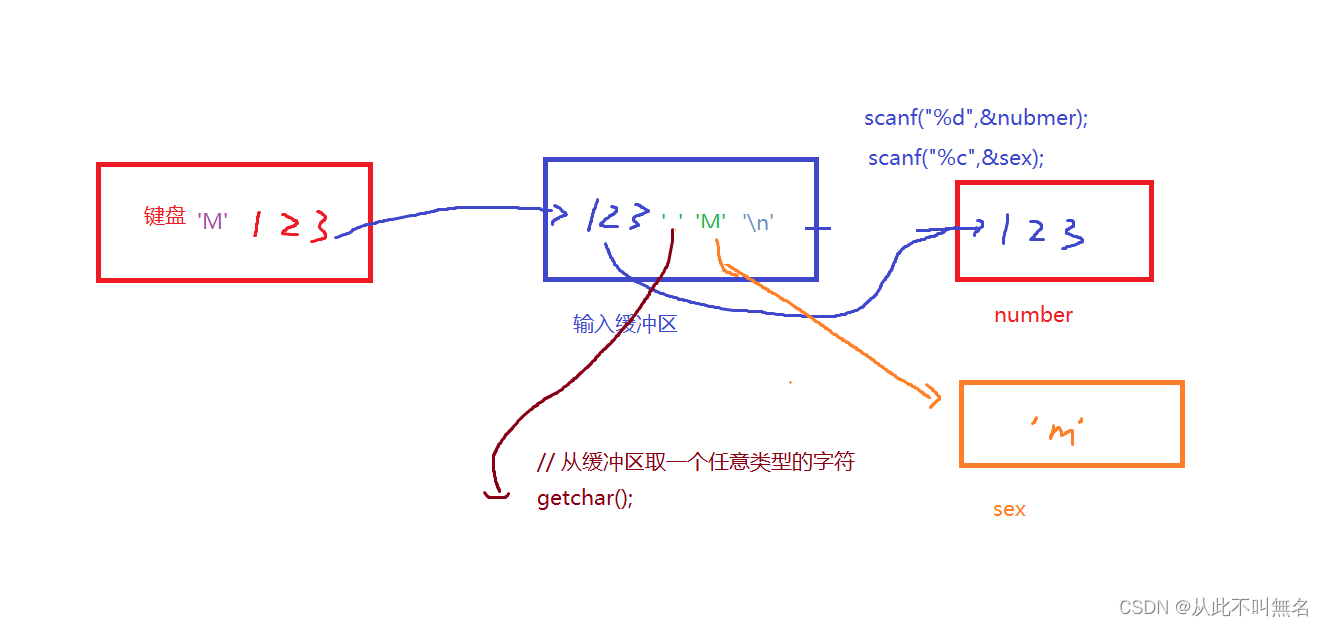
scanf(); // 格式化输入函数
fgets(); // 字符串输入函数
int a;
float f;
scanf("%d", &a); // 从键盘输入一个整型,放入指定的内存地址 &a 中
scanf("%f", &f); // 从键盘输入一个浮点数,放入指定的内存地址 &f 中
// 从键盘依次输入一个整型和一个浮点型数据,用空白符隔开
scanf("%d%f", &a, &f);
char c;
char s[10];
// 从键盘输入一个字符,放入指定的内存地址 &f 中
scanf("%c", &c);
// 从键盘输入一个单词,放入指定的数组 s 中(注意不是&s)
scanf("%s", s );
fgets(s, 10, stdin); // 从键盘输入一行字符串,放入数组 s 中
- 注意1:
- scanf() 与 printf() 不同,scanf() 的格式控制串不可乱写,尤其是结尾处的 \n
- 用户必须完全按照 scanf() 中描述的输入格式控制串来输入数据,否则将出错。
- 示例:
// 此处输入时必须带逗号
scanf("%d,%d", &a, &b);
// 此处必须先输入a=,然后才能输入整数
scanf("a=%d", &a);
// 此处结束输入时按下的回车符将被scanf()误以为格式控制符,无法正常结束输入
scanf("%d\n", &a);
- 注意2:
- scanf() 的返回值,代表成功从键盘读取的数据的个数
- 无法匹配 scanf() 指定格式的数据,将被遗留在输入缓冲区中,不会消失
- 示例:
// scanf() 试图从键盘读取两个整数
// 返回值 n 代表成功读取的个数,比如:
// 输入100 200,则 n 将等于2
// 输入100 abc,则 n 将等于1
// 输入abc xyz,则 n 将等于0;输入abc 200,n也将等于0
int n = scanf("%d%d", &a, &b);
// 根据 scanf() 的返回值,判断用户是否输入了正确的格式
while(n != 2)
{
// 需要清空缓冲区并提示用户重新输入
char s[50];
fgets(s, 50, stdin);
printf("请重新输入两个整数\n");
n = scanf("%d%d", &a, &b);
}
「练习2」
编程实现如下功能:
- 如果用户输入大小写字母,则输出字母对应的ASCII码值。
- 如果用户输入ASCII码值,则输出对应的大小写字母。
#include <stdio.h>
int main(void)
{
char ch;
printf("请输入小写字母: ")
scanf("%c",&ch);
// 输出对应的大写字母
printf("%c\n",ch-' ');
//printf("%d\n",ch);
}
8.类型转换
- 概念:不一致但相互兼容的数据类型,在同一表达式中将会发生类型转换。
- 转换模式:
- 隐式转换:系统按照隐式规则自动进行的转换
- 强制转换:用户显式自定义进行的转换
- 隐式规则:从小类型向大类型转换,目的是保证不丢失表达式中数据的精度

隐式转换示例代码
char a = 'a';
int b = 12;
float c = 3.14;
float x = a + b - c; // 在该表达式中将发生隐式转换,所有操作数被提升为float
- 强制转换:用户强行将某类型的数据转换为另一种类型,此过程可能丢失精度
char a = 'a';
int b = 12;
float c = 3.14;
float x = a + b - (int)c; // 在该表达式中a隐式自动转换为int,c被强制转为int
不管是隐式转换,还是强制转换,变换的都是操作数在运算过程中的类型,是临时的,操作数本身的类型不会改变,也无法改变。
数据类型的本质
- 概念:各种不同的数据类型,本质上是用户与系统对某一块内存数据的解释方式的约定。
- 推论:
- 类型转换,实际上是对先前定义时候的约定,做了一个临时的打破。
- 理论上,可以对任意的数据做任意的类型转换,但转换之后的数据解释不一定有意义。
整型数据尺寸
- 概念:整型数据尺寸是指某种整型数据所占用内存空间的大小
- C语言标准并未规定整型数据的具体大小,只规定了相互之间的 “ 相对大小 ” ,比如:
- short 不可比 int 长
- long 不可比 int 短
- long 型数据长度等于系统字长
- 系统字长:CPU 一次处理的数据长度,称为字长。比如32位系统、64位系统。
- 典型尺寸:
- char 占用1个字节
- short 占用2个字节
- int 在16位系统中占用2个字节,在32位和64位系统中一般都占用4个字节
- long 的尺寸等于系统字长
- long long 在32位系统中一般占用4个字节,在64位系统中一般占用8个字节
- 存在问题:long int data = 2^63-1;
- 同样的代码,放在不同的系统中,可能会由于数据尺寸发生变化而无法正常运行。
- 因此,系统标准整型数据类型,是不可移植的,这个问题在底层代码中尤为突出。
可移植性整型
- 概念:不管放到什么系统,尺寸保持不变的整型数据,称为可移植性整型
- 关键:typedef
typedef int int32_t; // 将类型 int 取个别名,称为 int32_t
typedef long int64_t; // 将类型 long 取个别名,称为 int64_t
- 思路:
- 为所有的系统提供一组固定的、能反应数据尺寸的、统一的可移植性整型名称
- 在不同的系统中,为这些可移植性整型提供对应的 typedef 语句
- 系统预定义的可移植性整型:
int8_t
int16_t
int32_t
int64_t
uint8_t
uint16_t
uint32_t
uint64_t
练习:自定义以上数据类型
pid_t
time_t
size_t
... ...
demo:
#include <stdio.h>
// 可移植数据类型
typedef long long int long_32_t;
typedef long int long64_t;
// 系统自动切换
#if win64
typedef long64_t long;
#elif win32
typedef long_32_t long;
#endif
int main(int argc, char const *argv[])
{
// 问题:在32位系统中long占用4字节
// 在64位系统中long占用8字节
// 如果32位系统存放的数据大于4字节会导致内存泄漏
printf("%ld\n",sizeof(long int ));
printf("%ld\n",sizeof(long long int));
// 通过移植数据类型解决
//long_32_t data = 123456789;
long64_t data = 123456789; // 2^63-1
printf("%d\n",data);
return 0;
}
vi /usr/include/stdint.h

「练习3」
有时候我们需要使用 int32_t 类型变量代替 int 类型变量的原因是什么?
int类型是基本的数据类型,但是系统的字长不一致可能会导致使用int分配的空间大小不一致从而导致内存泄漏,不利于程序的可移植性,所以一般我们会使用系统给给我们重新定义的类型比如int_32_t,或者是我们自定的类型,一般linux系统会帮我们定义了一套根据系统的字长而确认的数据类型,一般在/usr/include/stdint.h















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









