







1. 结构体基本概念
C语言提供了众多的基本数据类型,但现实生活中的对象一般都不是单纯的整型、浮点型或字符串,而是这些基本类型的综合体。比如一个学生,典型的应该拥有学号(整型)、姓名(字符串)、分数(浮点型)、性别(枚举)等不同侧面的属性,这些所有的属性都不应该被拆分开来,而是应该组成要一个整体,代表一个完整的学生。
在C语言中,可以使用结构体来将多种不同的数据类型组装起来,形成某种现实意义的自定义的变量类型。结构体本质上是一种自定义类型。
学生信息
{
姓名
性别
年龄
成绩
...
}
结构体的定义:
struct 结构体标签
{
成员1;
成员2;
...
};
struct 结构体名
{
成员类型1 成员名1;
成员类型2 成员名2;
成员类型3 成员名3;
};
// 结构体声明,一定是在全局变量或者在头文件,声明结构体不占用空间
struct student
{
char name[256];// 姓名
char sex; //性别
unsigned char age;//年龄
unsigned int ID;//学号
unsigned short int score; //成绩
}; // 定义完结构体一定要添加分号结束
- 语法:
- 结构体标签,用来区分各个不同的结构体
- 成员,是包含在结构体内部的数据,可以是任意的数据类型
- 示例:
// 定义一种称为struct node的结构体类型
struct node
{
int a;
char b;
double c;
};
int main()
{
// 定义结构体变量
struct node n;
}
2. 结构体初始化
结构体跟普通变量一样,设计定义、初始化、赋值、取地址等等操作,这些操作绝大部分都跟普通变量别无二致,只有少数操作有些特殊。这其实也是结构体这种组合类型的设计初衷,就是让开发者用起来比较顺手,不跟普通变量产生态度差异。
- 结构体定义和初始化
- 由于结构体内部拥有多个不同类型的成员,因此初始化采用与类似列表方式
- 结构体的初始化有两种方式:①普通初始化;②指定成员初始化。
- 为了能使用结构体类型的升级迭代,一般建议采用指定成员初始化。
- 示例:
//1.普通初始化
// 普通初始化,申请的是栈空间 int a = 10;
// 缺陷是按部就班赋值,如下
struct student st = {"jack", 'm', 18};
printf("%s,%c,%d\n",st.name, st.sex, st.age);
// 2.指定成员初始化
// 指定成员初始化
// 不需要按部就班赋值
struct student st1 = {
.age = 19,
.name = "rose",
.sex = 'g'
};
printf("%s,%c,%d\n",st1.name, st1.sex, st1.age);
-
指定成员初始化的好处:
- 成员初始化的次序可以改变
-
可以初始化一部份成员
- 结构体新增了成员之后初始化语句仍然可
-
定义结构体初始化
struct student { char name[100]; // 姓名 char sex; // 性别 unsigned short age; // 年龄 }st={"jack",'m',18}; // 静态区.data段 void func(void) { printf("%s,%c,%d\n",st.name, st.sex, st.age); } int main(int argc, char const *argv[]) { printf("%s,%c,%d\n",st.name, st.sex, st.age); func(); return 0; } -
多结构体嵌套
#include <stdio.h> struct date { int y; int m; int d; }; struct student { char name[100]; // 姓名 char sex; // 性别 unsigned short age; // 年龄 struct date birthday; // 生日 }; int main(int argc, char const *argv[]) { struct student st = { .age = 18, .sex = 'm', .name = "jack", .birthday.y = 2000, .birthday.m = 1, .birthday.d = 1 }; printf("%s,%c,%d,%d-%d-%d\n",st.name, st.sex, st.age, st.birthday.y,st.birthday.m,st.birthday.d); return 0; }「课堂练习」
思考以下问题:
- 结构体初始化的基本语法是怎样的?
1. 普通初始化
2. 指定成员初始化
- 什么叫做指定成员初始化?这样做有什么好处?
- 指定成员初始化的好处:
- 成员初始化的次序可以改变
- 可以初始化一部份成员
- 结构体新增了成员之后初始化语句仍然可
3. 结构体成员引用(先定义结构体,再使用)
结构体相当于一个集合,内部包含了众多成员,每个成员实际上是独立的变量,都可以被独立的引用,引用结构体成员非常简单,只需要使用一个成员引用符即可:
结构体.成员
示例:
n.a = 200;
n.b = 'y';
n.c = 2.22;
printf("%d, %c, %lf\n", n.a, n.b, b.c);
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
struct student
{
char name[100]; // 姓名
//char *name;
unsigned short age; // 年龄
char sex; // 性别
};
int main(int argc, char const *argv[])
{
// 1. 申请栈空间
struct student st;
st.age = 18;
st.sex = 'm';
// 先定义在使用,数组不能直接赋值
//st.name = "jack";
// 字符串拷贝
strcpy(st.name, "jack");
printf("%s,%d,%c\n",st.name,st.age,st.sex);
// 2. 申请堆空间
struct student *pst = malloc(sizeof(struct student));
if(pst == NULL)
{
perror("malloc failed:");
return -1;
}
// 结构体指针使用的是->
pst->age = 19;
pst->sex = 'g';
strcpy(pst->name,"rose");
printf("%s,%d,%c\n",pst->name,pst->age,pst->sex);
// 释放空间
free(pst);
pst = NULL;
return 0;
}
3. 结构体指针与数组
跟普通变量别无二致,可以定义指向结构体的指针,也可以定义结构体数组。
- 结构体指针:
struct node n = {100, 'x', 3.14};
struct node *p = &n;
// 以下语句都是等价的
printf("%d\n", n.a);
printf("%d\n", (*p).a);
printf("%d\n", p->a); // 箭头 -> 是结构体指针的成员引用符
printf("%d\n", (&n)->a);// 将n转为地址
- 结构体数组:
struct node s[5];
s[0].a = 300;
s[0].b = 'z';
s[0].c = 3.45;
int a[5]; a[0] = 1; a[1] = 2; a[2] = 3;
struct student class[5];
// 结构体数组普通初始化
struct student
{
char name[20];
int age;
int score;
}st[3] = {
{"jack",18,80},
{"Rose",17,85},
{"xiaoming",19,60}
};
void main()
{
printf("%s,%d,%d\n",st[0].name,st[0].age,st[0].score);
printf("%s,%d,%d\n",st[1].name,st[1].age,st[1].score);
printf("%s,%d,%d\n",st[2].name,st[2].age,st[2].score);
}
// 结构体数组指定成员初始化
struct student1
{
char name[20];
int age;
int score;
};
void main()
{
// 指定成员初始化
struct student class[3] = {
//class[0]
{
.name = "jack",
.age = 18,
.score = 90
},
//class[1]
{
.name = "jack",
.age = 18,
},
//class[2]
{
.name = "jack",
.score = 18,
}
};
printf("%s,%d,%d\n",class[0].name,class[0].age,class[0].score);
printf("%s,%d,%d\n",class[1].name,class[1].age,class[1].score);
printf("%s,%d,%d\n",class[2].name,class[2].age,class[2].score);
}
// 引用结构体数组里面的成员
struct student1
{
char name[20];
int age;
int score;
};
void main()
{
struct student class1[3];
strcpy(class1[0].name,"jack");
class1[0].age = 18;
class1[0].score = 90;
printf("%s,%d,%d\n",class1[0].name,class1[0].age,class1[0].score);
scanf("%s%d%d",(class1+1)->name,&class1[1].age,&class1[1].score);
scanf("%s%d%d",(*(class1+1)).name,&class1[1].age,&class1[1].score);
printf("%s,%d,%d\n",class1[1].name,class1[1].age,class1[1].score);
}
作业:
定义一个学生信息结构体数组(数组元素的个数由用户决定),依次从键盘输入每个学生
信息(姓名,成绩),按成绩的降序输出每个学生的信息,降序算法最好是自己封装函数
- 结构体封装
将结构体的声明放在头文件
#ifndef _MAIN_H
#define _MAIN_H
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct
{
char name[100];
int score; // 成绩
}student_type,*pstudent_type;
#endif
- 结构体交换
#include "main.h"
void score_sort(pstudent_type st,int count)
{
for(int i = 0; i < count-1; i++)
{
for(int j = 0; j < count-i-1; j++)
{
if(st[j].score < st[j+1].score)
{
student_type temp = st[j];
st[j] = st[j+1];
st[j+1] = temp;
}
}
}
}
int main(int argc, char const *argv[])
{
student_type st[3] = {
{"jack",88},
{"rose",95},
{"ken",80}
};
score_sort(st,3);
for(int i = 0; i < 3; i++)
{
printf("%s成绩%d\n",st[i].name,st[i].score);
}
printf("\n");
return 0;
}
练习:
编写一个头文件,头文件定义结构体,通过 typedef改别名为普通类型和指针类型
在main.c 分配用栈和堆实现数据的存储并输出
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// 将sruct student改别名为student_type,类型为普通结构体类型
// 将sruct student改别名为*pstudent_type,类型为结构体指针类型
typedef struct student
{
char name[100]; // 姓名
unsigned short age; // 年龄
char sex; // 性别
}student_type,*pstudent_type;
int main(int argc, char const *argv[])
{
//struct student st;
student_type st;
st.age = 18;
printf("%d\n",st.age);
// 结构体指针类型,注意malloc分配空间的时候注意结构体空间大小
//struct student *pst;
pstudent_type pst = malloc(sizeof(student_type));
pst->age = 19;
printf("%d\n",pst->age);
struct student st1;
st.age = 25;
printf("%d\n",st.age);
printf("%d,%d\n",sizeof(student_type),sizeof(pstudent_type));
return 0;
}
总结:
typedef 修饰结构体,可以将一个结构体类型改为普通变量类型,定义此类型的时候不需要再添加struct关键字,也能修饰结构体指针类型,好处是使用结构体变量的时候代码更加简洁,增加代码的可读性,使用灵活.
CPU字长
字长的概念指的是处理器在一条指令中的数据处理能力,当然这个能力还需要搭配操作系统的设定,比如常见的32位系统、64位系统,指的是在此系统环境下,处理器一次存储处理的数据可以达32位或64位。
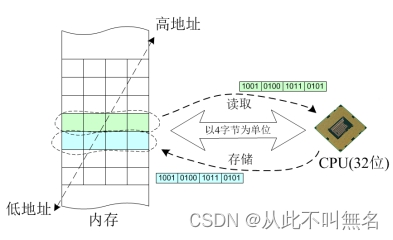
cpu字长含义
地址对齐
cpu字长确定后,相当于明确了系统每次存取内存数据时的边界,以32位系统为例,32位意味着cpu每次存取都以4字节位边界,因此每4字节可以认为是cpu存取数据的一个单元。
如果存取数据刚好落在所需单元之内,那么我们就说这个数据的地址是对齐的,如果存取的数据跨越了边界,使用了超过所需单元的字节,那么我们就说这个数据的地址是未对齐的。
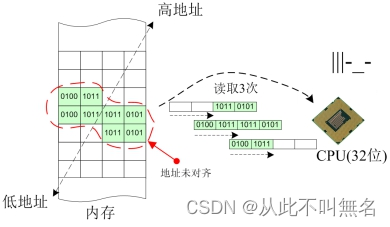
地址未对齐的情形
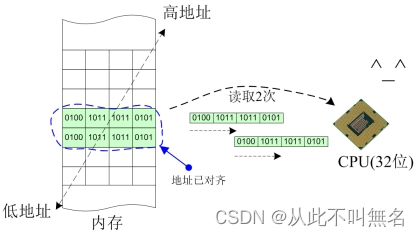
地址已对齐的情形
从图中可以明显看出,数据本身占据了8个字节,在地址未对齐的情况下,CPU需要分3次才能完整地存取完这个数据,但是在地址对齐的情况下,CPU可以分2次就能完整地存取这个数据。
总结:
如果一个数据满足以最小单元数存放在内存中,则称它地址是对齐的,否则是未对齐的。地址对齐的含义用大白话说就是1个单元能塞得下的就不用2个;2个单元能塞得下的就不用3个。
如果发生数据地址未对齐的情况,有些系统会直接罢工,有些系统则降低性能。
普通变量的m值
以32位系统为例,由于CPU存取数据总是以4字节为单元,因此对于一个尺寸固定的数据而言,当它的地址满足某个数的整数倍时,就可以保证地址对齐。这个数就被称为变量的m值。
根据具体系统的字长,和数据本身的尺寸,m值是可以很简单计算出来的。
- 举例:
char c; // 由于c占1个字节,因此c不管放哪里地址都是对齐的,因此m=1
short s; // 由于s占2个字节,因此s地址只要是偶数就是对齐的,因此m=2
int i; // 由于i占4个字节,因此只要i地址满足4的倍数就是对齐的,因此m=4
double f; // 由于f占8个字节,因此只要f地址满足4的倍数就是对齐的,因此m=4(32位系统),64位系统m=8
printf("%p\n", &c); // &c = 1*N,即:c的地址一定满足1的整数倍
printf("%p\n", &s); // &s = 2*N,即:s的地址一定满足2的整数倍
printf("%p\n", &i); // &i = 4*N,即:i的地址一定满足4的整数倍
printf("%p\n", &f); // &f = 4*N,即:f的地址一定满足4的整数倍
- 注意,变量的m值跟变量本身的尺寸有关,但它们是两个不同的概念。
注意:
32位系统的m值最大值为4,比如 double m值为4
64位系统的m值最大值为结构体变量的最大值 比如m值为8
m值为空间的边界格子的个数
- 手工干预变量的m值:
char c __attribute__((aligned(32))); // 将变量 c 的m值设置为32
- 语法:
- attribute 机制是GNU特定语法,属于C语言标准语法的扩展。
- attribute 前后都是双下划线,aligned两边是双圆括号。
- attribute 语句,出现在变量定义语句中的分号前面,变量标识符后面。
- attribute 机制支持多种属性设置,其中 aligned 用来设置变量的 m 值属性。
- 一个变量的 m 值只能提升,不能降低,且只能为正的2的n次幂。
结构体的M值
- 概念:
- 结构体的M值,取决于其成员的m值的最大值。即:M = max{m1, m2, m3, …};
- 结构体的和地址和尺寸,都必须等于M值的整数倍。
- 示例:
// 32位系统
struct node
{
short a; // 尺寸=2,m值=2
double b; // 尺寸=8,m值=4
char c; // 尺寸=1,m值=1
};
struct node n; // M值 = max{2, 4, 1} = 4;
// 64位系统
struct node
{
short a; // 尺寸=2,m值=2
double b; // 尺寸=8,m值=8
char c; // 尺寸=1,m值=1
};
struct node n; // M值 = max{2, 8, 1} = 8;
- 以上结构体成员存储分析:
- 结构体的M值等于4,这意味着结构体的地址、尺寸都必须满足4的倍数。
- 成员a的m值等于2,但a作为结构体的首元素,必须满足M值约束,即a的地址必须是4的倍数
- 成员b的m值等于4,因此在a和b之间,需要填充2个字节的无效数据(一般填充0)
- 成员c的m值等于1,因此c紧挨在b的后面,占一个字节即可。
- 结构体的M值为4,因此成员c后面还需填充3个无效数据,才能将结构体尺寸凑足4的倍数。
- 以上结构体成员图解分析:
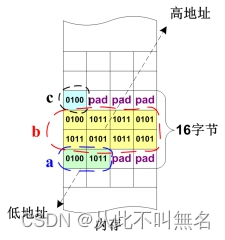
可移植性
可移植指的是相同的一段数据或者代码,在不同的平台中都可以成功运行。
- 对于数据来说,有两方面可能会导致不可移植:
- 数据尺寸发生变化
- 数据位置发生变化
第一个问题,起因是基本的数据类型在不同的系统所占据的字节数不同造成的,解决办法是使用教案04讨论过的可移植性数据类型即可。本节主要讨论第二个问题。
考虑结构体:
struct node
{
int8_t a;
int32_t b;
int16_t c;
};
以上结构体,在不同的的平台中,成员的尺寸是固定不变的,但由于不同平台下各个成员的m值可能会发生改变,因此成员之间的相对位置可能是飘忽不定的,这对数据的可移植性提出了挑战。
解决的办法有两种:
- 第一,固定每一个成员的m值,也就是每个成员之间的塞入固定大小的填充物固定位置:
struct node
{
int8_t a __attribute__((aligned(1))); // 将 m 值固定为1
int64_t b __attribute__((aligned(8))); // 将 m 值固定为8
int16_t c __attribute__((aligned(2))); // 将 m 值固定为2
};
- 第二,将结构体压实,也就是每个成员之间不留任何空隙:
struct node
{
int8_t a;
int64_t b;
int16_t c;
} __attribute__((packed));















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









