







1.概念
对链表而言,双向遍历数据节点相较于单向而言方便许多,因此双向链表在实际运用中是最常见的链式形态。
2.双向链表

1. 基本操操作
-
设计节点
-
创建数据节点
// 创建数据节点 struct node { dataType data; struct node *prev;// 指向上一个节点 struct node *next;// 指向下一个节点 }; 2.
2.创建头节点
// 创建头节点 struct headNode { struct node *first; // 指向首节点 struct node *last; // 指向最后一个节点 int nodeNumber; // 记录节点数 };1. 初始化空链表// 创建头节点 struct headNode *create_head() { // 创建头节点 struct headNode *head = malloc(sizeof(struct headNode)); if(head == NULL) { perror("create head failed:"); return NULL; } head->first = NULL; head->last = NULL; head->nodeNumber = 0; return head; } // 创建新节点 struct node *create_new_node(dataType data) { struct node *pnew = malloc(sizeof(struct node)); if(pnew == NULL) { perror("create new node failed:"); return NULL; } pnew->data = data; pnew->prev = NULL; pnew->next = NULL; } -
-
增删节点
struct headNode *add_node_list(struct headNode *head,dataType newData,dataType data) { // 创建新节点 struct node *pnew = create_new_node(newData); if(pnew == NULL) return NULL; // 找节点 struct node *p = head->first; while(p) { if(p->data == data) break; else { p = p->next; } } // 如果找的是第一个节点 if(p->data == head->first->data) { addHead(pnew,head); } else if(p == NULL) { addTail(pnew,head); } else { pnew->next = p; pnew->prev = p; p->prev->next = pnew; pnew->prev = pnew; } head->nodeNumber++; return head; } struct headNode *del_node(struct headNode *head,dataType data) { // 找节点 struct node *p = head->first; while(p) { if(p->data == data) break; else p = p->next; } // 如果是第一个节点 if(head->first->data == data) { head->first->next->prev = head->first; head->first = p->next; p->next = NULL; p->prev = NULL; free(p); } else if(p->data == head->last->data) { p->prev->next = NULL; p->prev = NULL; free(p); } else if(p == NULL) { printf("没有可删除的节点\n"); } else { p->next->prev = p->prev; p->prev->next = p->next; p->prev = NULL; p->next = NULL; free(p); } head->nodeNumber--; return head; } -
链表遍历
void showList(struct headNode *head) { for(struct node *p = head->first;p != head->last->next;p = p->next) { printf("%d\t",p->data); } printf("\n"); printf("节点数为:%d\n",head->nodeNumber); }
5.销毁节点
// 销毁链表
struct headNode * distory_list(struct headNode *head)
{
if(isEmpty(head))
return false;
// 逐一删除节点
struct node *p = NULL;
for(struct node *tmp = head->first;tmp != NULL; tmp = p)
{
p = tmp->next;
free(tmp);
head->nodeNumber--;
}
return head;
}
3.双向循环链表
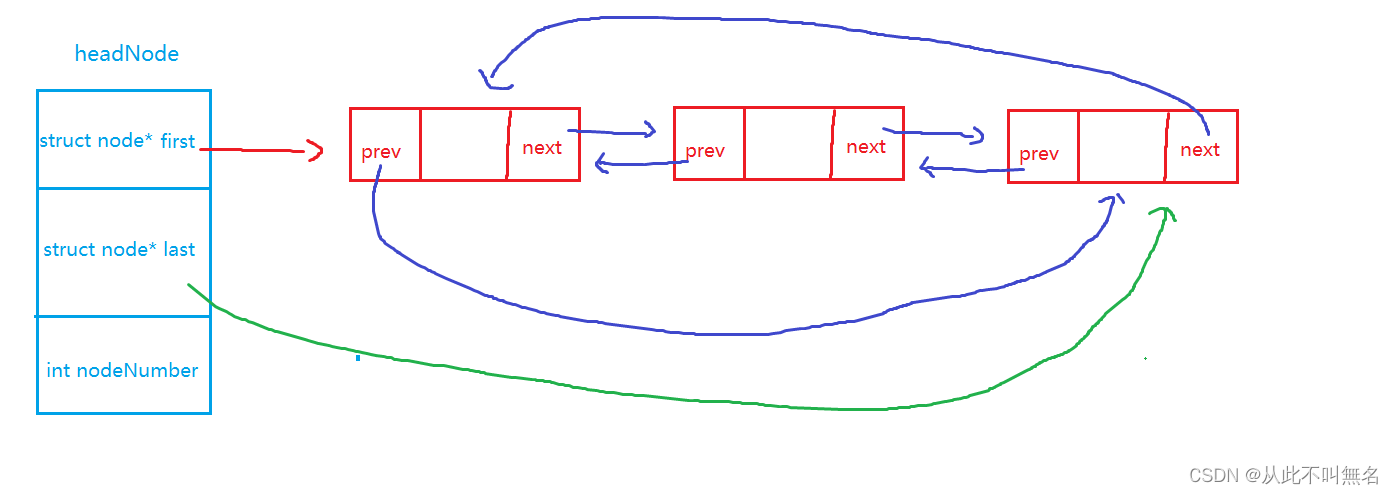
// 如果还有节点,首尾相连
if(head->nodeNumber != 0)
{
head->last->next = head->first;
head->first->prev = head->last;
}
4.适用场合
经过单向链表、双向链表的学习,可以总结链表的适用场合:
1.适合用于节点数目不固定,动态变化较大的场合
2.适合用于节点需要频繁插入,删除的场合
3.适合用于对节点查找效率不十分敏感的场合
作业1:
1.实现循环链表删除节点
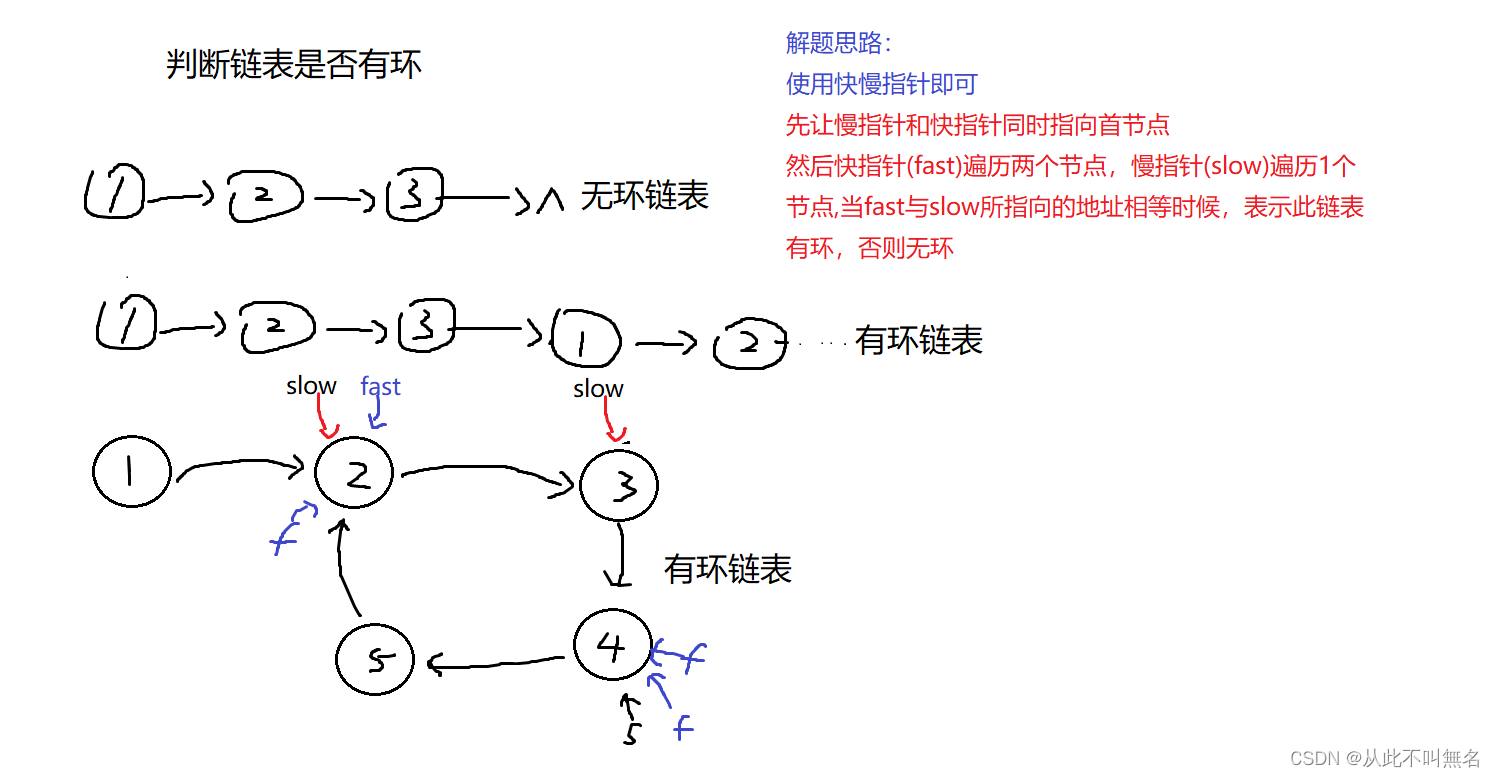
2.判断链表是否有环
附加题:合并两个链表,按从小到大排序(拆链表,比较节点,插入节点到新链表)
同志们 加油啊!















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









