






前言

图片来自作者:Flow 展示了量化的必要性。(笑脸和生气脸图片来自Yan Krukau)
在我解释上面的图表之前,让我先介绍一下您将在本文中学习的重点内容。
- 首先,您将了解量化是什么以及为什么量化。
- 接下来,您将深入了解如何通过一些简单的数学推导来实现量化。
- 最后,我们将在 PyTorch 中一起编写一些代码来执行 LLM 权重参数的量化和反量化
让我们一起来一一解开吧。
1. 什么是量化?为什么需要它?
量化是一种将较大尺寸的模型(LLM 或任何深度学习模型)压缩为较小尺寸的方法。量化的主要目的是量化模型的权重参数和激活。让我们进行一个简单的模型大小计算来验证我们的陈述。

作者提供的图片:左图:以 GB 为单位的基本模型大小计算,右图:以 GB 为单位的量化模型大小计算
在上图中,基础模型 Llama 3 8B 的大小为 32 GB。经过 Int 8 量化后,大小减小到 8Gb(减少了 75%)。通过 Int4 量化,大小进一步减小到 4GB(减少了约 90%)。这是模型大小的大幅减少。这确实很神奇!不是吗?这要归功于量化论文的作者,我对数学的力量深表赞赏。
现在您已经了解了什么是量化,让我们继续讨论为什么。
让我们看一下图 1,作为一名有抱负的 AI 研究人员、开发人员或架构师,如果您想对数据集或推理执行模型微调,很可能由于内存和处理器的限制,您将无法在机器或移动设备上执行此操作。
可能和我一样,您也会像选项 1b 一样怒气冲冲。这将我们带到了选项 1a,您可以让云提供商为您提供所需的所有资源,并且可以轻松地使用任何您想要的模型完成任何任务。
但这会花费您很多钱。如果你能负担得起,那就太好了。但如果您的预算有限,好消息是您还有选项 2 可用。在这里,您可以执行量化方法来减小模型的大小并方便地在您的用例中使用它。如果您的量化做得好,您将获得与原始模型大致相同的准确度。
注意:如果您想将模型投入生产,一旦您在本地机器上对模型完成微调或其他任务,我建议您将模型托管在云中,以便为您的客户提供可靠、可扩展和安全的服务。ParagogerAI训练营 2img.ai
2. 量化是如何实现的?一个简单的数学推导。
从技术上讲,量化将模型的权重值从较高精度(例如 FP32)映射到较低精度(例如 FP16|BF16|INT8)。虽然有许多量化方法可用,但在本文中,我们将学习一种广泛使用的量化方法,即线性量化方法。线性量化有两种模式:A.非对称量化和B.对称量化。我们将逐一了解这两种方法。
A.非对称线性量化:非对称量化方法 将原始张量范围(Wmin,Wmax)中的值映射到量化张量范围(Qmin,Qmax)中的值。

作者图片:非对称线性量化
- Wmin、Wmax:原始张量的最小值和最大值(数据类型:FP32,32 位浮点数)。大多数现代 LLM 中权重张量的默认数据类型为 FP32。
- Qmin、Qmax:量化张量的最小值和最大值(数据类型:INT8,8 位整数)。我们还可以选择其他数据类型(如 INT4、INT8、FP16 和 BF16)进行量化。我们将在示例中使用 INT 8。
- 比例值(S):在量化过程中,比例值会缩小原始张量的值,得到量化张量。在反量化过程中,比例值会放大量化张量的值,得到反量化值。比例值的数据类型与原始张量相同,均为 FP32。
- 零点 (Z):零点是量化张量范围内的非零值,直接映射到原始张量范围内的值0。零点的数据类型为 INT8,因为它位于量化张量范围内。
- 量化:图表的“ A ”部分显示了量化过程,将 [Wmin, Wmax] 映射到 [Qmin, Qmax]。
- 反量化:图的“B”部分显示了反量化过程,该过程映射 [Qmin, Qmax] -> [Wmin, Wmax]。
那么,我们如何从原始张量值导出量化张量值呢?这很简单。如果你还记得高中数学,你可以轻松地理解下面的推导。让我们一步一步来(我建议你在推导方程时参考上面的图表,以便更清楚地理解)。
我知道你们中的许多人可能不想经历下面的数学推导。但相信我,它肯定会帮助你理清概念,并在后期为量化编码时节省大量时间。我在研究这个问题时也有同样的感受。


- 潜在问题 1:如果 Z 的值超出范围该怎么办?解决方案:使用简单的 if-else 逻辑,如果 Z 的值小于 Qmin,则将其更改为 Qmin;如果 Z 的值大于 Qmax,则将其更改为 Qmax。下图 4 中的图 A 对此进行了很好的描述。
- 潜在问题 2:如果 Q 值超出范围该怎么办?解决方案:在 PyTorch 中,有一个名为clamp 的函数,它会调整值以保持在特定范围内(在我们的示例中为 -128, 127)。因此,如果 Q 值低于 Qmin,则 clamp 函数会将 Q 值调整为 Qmin;如果 Q 值高于 Qmax,则将 Q 值调整为 Qmax。问题解决了,让我们继续。
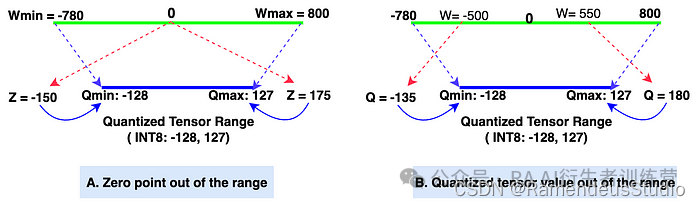
作者的图片:零点和量化张量超出范围
附注:对于 INT8(有符号整数数据类型),量化张量值的范围为 (-128, 127)。如果量化张量值的数据类型为 UINT8(无符号整数),则范围为 (0, 255)。
B. 对称线性量化:在对称方法中,原始张量范围中的 0 点映射到量化张量范围中的 0 点。因此,这被称为对称。由于 0 在范围的两侧都映射到 0,因此对称量化中没有 Z(零点)。整体映射发生在原始张量范围的 (-Wmax, Wmax) 和量化张量范围的 (-Qmax, Qmax) 之间。下图显示了量化和去量化情况下的对称映射。

作者图片:对称线性量化
由于我们已经定义了非对称段中的所有参数,因此这里也同样适用。让我们进入对称量化的数学推导。

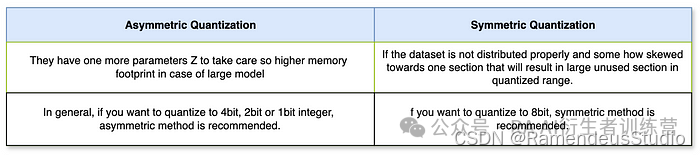
非对称量化和对称量化之间的区别:
现在您已经了解了线性量化是什么、为什么和如何,这将引导我们进入文章的最后一部分,即编码部分。ParagogerAI训练营 2img.ai
3. 在PyTorch中编写代码来执行LLM权重参数的量化和反量化。
正如我之前提到的,量化也可以在模型的权重、参数和激活上进行。但是,为了简单起见,我们将在编码示例中仅量化权重参数。在开始编码之前,让我们快速看一下 Transformer 模型中量化后权重参数值的变化情况。我相信这会让我们的理解更加清晰。

作者提供的图片:Transformer 架构中权重参数的量化
当我们仅对 16 个原始权重参数从 FP32 量化到 INT8 后,内存占用就从 512 位减少到了 128 位(减少了 25%)。这证明对于大模型的情况,减少会更加显著。
下面,您可以看到 FP32、Signed INT8 和 Unsigned UINT8 等数据类型在实际内存中的分布。我已经以 2 的补码进行了实际计算。您可以自行练习计算并验证结果。

作者提供的图片:FP32、INT8、UINT8 数据类型分布及计算示例
现在,我们已经介绍了开始编码所需的一切。我建议您继续学习以熟悉推导。
A.非对称量化代码:我们一步一步来编码。
步骤 1:我们首先为原始权重张量分配随机值(大小:4x4,数据类型:FP32)# !pip install torch; 如果尚未安装 torch 库,请先安装
# import torch library
import torch
original_weight = torch.randn(( 4 , 4 ))
print (original_weight)

FP32 中的 original_weight 张量
第 2 步:我们将定义两个函数,一个用于量化,另一个用于反量化。def asymmetric_quantization(original_weight):
# define the data type that you want to quantize. In our example, it's INT8.
quantized_data_type = torch.int8
# Get the Wmax and Wmin value from the orginal weight which is in FP32.
Wmax = original_weight.max().item()
Wmin = original_weight.min().item()
# Get the Qmax and Qmin value from the quantized data type.
Qmax = torch.iinfo(quantized_data_type).max
Qmin = torch.iinfo(quantized_data_type).min
# Calculate the scale value using the scale formula. Datatype - FP32.
# Please refer to math section of this post if you want to find out how the formula has been derived.
S = (Wmax - Wmin)/(Qmax - Qmin)
# Calculate the zero point value using the zero point formula. Datatype - INT8.
# Please refer to math section of this post if you want to find out how the formula has been derived.
Z = Qmin - (Wmin/S)
# Check if the Z value is out of range.
if Z < Qmin:
Z = Qmin
elif Z > Qmax:
Z = Qmax
else:
# Zero point datatype should be INT8 same as the Quantized value.
Z = int(round(Z))
# We have original_weight, scale and zero_point, now we can calculate the quantized weight using the formula we've derived in math section.
quantized_weight = (original_weight/S) + Z
# We'll also round it and also use the torch clamp function to ensure the quantized weight doesn't goes out of range and should remain within Qmin and Qmax.
quantized_weight = torch.clamp(torch.round(quantized_weight), Qmin, Qmax)
# finally cast the datatype to INT8.
quantized_weight = quantized_weight.to(quantized_data_type)
# return the final quantized weight.
return quantized_weight, S, Z
def asymmetric_dequantization(quantized_weight, scale, zero_point):
# Use the dequantization calculation formula derived in the math section of this post.
# Also make sure to convert quantized_weight to float as substraction between two INT8 values (quantized_weight and zero_point) will give unwanted result.
dequantized_weight = scale * (quantized_weight.to(torch.float32) - zero_point)
return dequantized_weight
步骤 3:我们将通过调用asymmetric_quantization函数来计算量化权重、比例和零点。您可以在下面的屏幕截图中看到输出结果,请注意,quantized_weight 的数据类型为 int8,scale 为 FP32,zero_point 为 INT8。quantized_weight, scale, zero_point = asymmetric_quantization(original_weight)
print(f"quantized weight: {quantized_weight}")
print("\n")
print(f"scale: {scale}")
print("\n")
print(f"zero point: {zero_point}")
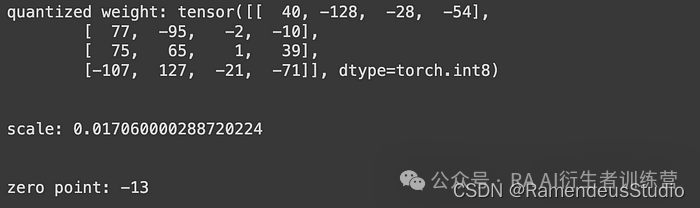
量化的重量、尺度和零点值
步骤 4:现在我们已经有了量化权重、比例和零点的所有值。让我们通过调用 asymmetric_dequantization 函数来获取反量化权重值。请注意,反量化权重值为 FP32。dequantized_weight = asymmetric_dequantization(quantized_weight, scale, zero_point)
打印(dequantized_weight)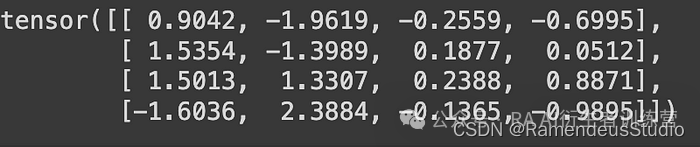
去量化权重值
步骤5:让我们通过计算它们之间的量化误差来找出最终的去量化权重值与原始权重张量相比的准确度。quantization_error = (dequantized_weight - original_weight).square().mean()
print(quantization_error)

输出结果:quantization_error 少了很多。因此,我们可以说非对称量化方法做得很好。
B. 对称量化代码:我们将使用与非对称方法相同的代码。对称方法唯一需要做的改变是始终确保 zero_input 的值为 0。这是因为在对称量化中,zero_input 值始终映射到原始权重张量中的 0 值。我们无需编写额外代码即可继续操作。
就这样!
我们到了这篇文章的结尾。我希望这篇文章能帮助你对量化建立坚实的直觉,并清楚地理解数学推导部分。
我最后的想法是……
- 在这篇文章中,我们涵盖了参与任何 LLM 或深度学习量化相关任务所需的所有必要主题。
- 虽然,我们已经成功地对权重张量进行了量化,并且也取得了良好的精度。在大多数情况下,这已经足够了。但是,如果你想对更大的模型应用更高精度的量化,你需要执行通道量化(量化权重矩阵的每一行或列)或组量化(在行或列中分成更小的组并分别量化它们)。这些技术更复杂。我将在即将发布ParagogerAI训练营 2img.ai中介绍它们。
欢迎你分享你的作品到我们的平台上. http://www.shxcj.com 或者 www.2img.ai 让更多的人看到你的才华。
创作不易,觉得不错的话,点个赞吧!!!















 1947
1947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









