







算法教程学习–深度优先搜索(DFS)
深度优先搜索(DFS)意指从一个节点出发不断向一个方向搜索直到此方向到达终点或者不能继续搜索为止。为了可以完整地从搜索出一个节点的所有道路,需要考虑回溯的方法。
简单的递归版DFS大致实现:
def rec_dfs(G, s, S): # G表示图,s表示开始的节点,S表示访问的队列
S.add(s)
for u in G[s]:
if s in S: # 如果已经访问过,则不再访问
continue
rec_dfs(G, u, S)
具体实现:
#coding:utf-8
def rec_dfs(G, s, S):
S.add(s)
for u in G[s]:
if s in G:
continue
rec_dfs(G, u, S)
def main():
a, b, c, d, e, f, g, h = range(8)
S = list()
G ={
a : {b, e},
b : {c, d},
c : {},
d : {},
e : {f, g},
f : {h},
g : {},
h : {}
}
rec_dfs(G, a, S)
print(S)
if __name__ == "__main__":
main()
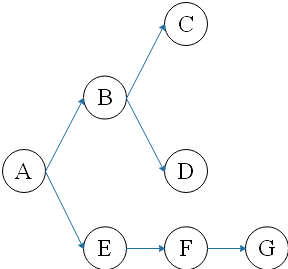
其中,G所构成的图如下所示:
递归版的实现就会需要计算机本身使用栈,当这个递归层次非常大的时候,使用递归就会产生一些负担。所幸,可以把递归版的实现改成迭代操作来实现,也就是要用一个栈来模拟计算机本身的操作,具体到这个算法,迭代的部分就是对将要访问的节点的迭代操作。
迭代版本的DFS实现:
def iter_DFS(G, s, S):
stack = list() # 模拟栈
stack.append(s)
while stack: # 当栈非空时
u = stack.pop() # 弹出一个将要访问的元素
S.append(s)
for item in G[u]:
if item in S: # 如果已经访问过,则不再访问
contiune
stack.append(item)
以上便是DFS两种实现(递归版和迭代版),因为存在回溯的行为,所有节点的子节点都会早与其祖先节点先完成全部探索。例如图中的F节点再被完全探索完成,即程序递归完成后,E节点才会接着被递归完成。所以在DFS探索树中,就会有一条重要的性质:任意节点的子孙节点在被探索到和结束探索的这一时间区间一点是在祖先节点的时间区间中的。可以把祖先节点和子孙节点之间看做是一种依赖关系,这样,就可以使用DFS来实现topsort排序。
首先还是对图G中节点开始被探索的时间和结束探索时间进行标记,以便有个直观的印象:
def dfs(G, s, S, startTime, endTime, t):
S.append(s)
startTime[s] = t
t += 1
for u in G[s]:
if u in S:
continue
t = dfs(G, u, S, startTime, endTime, t)
endTime[s] = t
t += 1
return t

现在可以将DFS用于topsort排序了。
def topsort_dfs(G, s, S, res):
def recurse(u):
if u in S:
return
S.append(u)
for v in G[u]:
recurse(v)
res.append(u)
for u in G:
recurse(u)
return res.reverse()
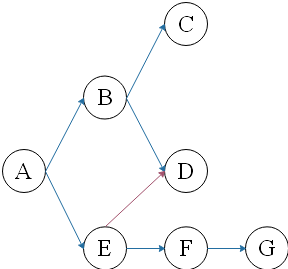
个人认为两种比较特殊的情况:
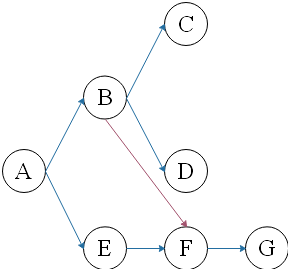
左图相当于把F节点从E处截断,把F当做B的子节点。
右图(我们假设探索的顺序从上到下),下面支路的探索完成时间肯定是晚于上面,最后用reverse()函数翻转,也不会影响topsort排序。















 1809
1809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









