







作者:RayChiu_Labloy
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
目录
labelme安装这里就不多说了,方式差不多,建议 pip install方式
labelimg安装:
方式一:
安装:
pip install labelimg打开:
labelimg
方式二:
从github 下载zip包 地址:https://github.com/tzutalin/labelImg
安装三方依赖库:
conda install pyqt=5
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple/
解压labelimg进入其根目录,检查发现没有resources.py 但是有resources.qrc,将原来的resources.qrc文件转换成resources.py文件:
Pyrcc5 -o resources.py resources.qrc
将我们刚刚的labelImg-master文件夹里面的resources.py文件移动到libs里面:
在labelimg根目录执行命令打开工具:
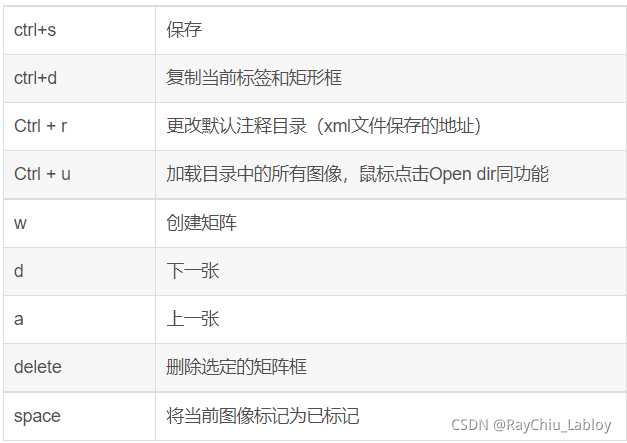
python labelimg.pylabelimg快捷键
labelme安装这里就不多说了,方式差不多,建议 pip install方式
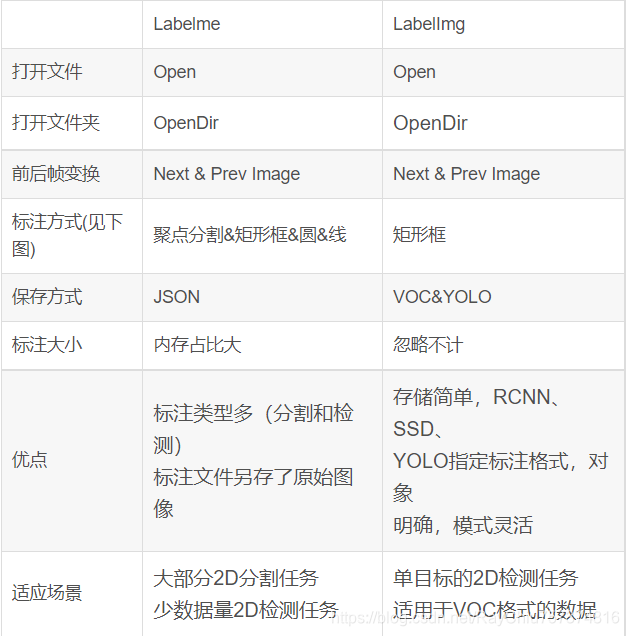
然后重点是两者的对比和区别:
先上图:

表格整理对比:
|
|
|


参考: Labelme和LabelImg使用(Win10)_Along1617188的博客-CSDN博客:
labelimg标注某张图片生成的xml文件:
<?xml version='1.0' encoding='utf-8'?>
<annotation>
<folder>JPEGImages</folder>
<filename>1.bmp</filename>
<path>E:\projects\pyHome\about_yolo\yolov5_bottleCap_defect_detection\VOCData\JPEGImages\1.bmp</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1280</width>
<height>960</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>defect</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>1</difficult>
<bndbox>
<xmin>589</xmin>
<ymin>411</ymin>
<xmax>701</xmax>
<ymax>480</ymax>
</bndbox>
</object>
</annotation>labelme标注一张图片生成的json文件:
{
"version": "4.5.9",
"flags": {},
"shapes": [
{
"label": "normal",
"points": [
[
584.6122448979592,
412.3061224489796
],
[
708.0816326530612,
484.7551020408163
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
}
],
"imagePath": "1.bmp",
"imageData": "iVBORw0KGgoAAA ...(省略一万字符) CYII=",
"imageHeight": 960,
"imageWidth": 1280
}关于图片素材标注质量:
数据、算力、算法齐驱人工智能的三大马车我认为数据更重要,数据是人工智能的核心竞争力。算法再厉害,没有数据,也是巧妇难为无米之炊。每个家企业的算法虽有区别,但是算法通过数据不断投喂,可以不断学习进化,会越来越聪明,从而呈现出马太效应,强者恒强的效应。模型训练人员利用标注好的数据训练出模型算法,但人工标注的数据,往往甚至不可避免的会存在一些错标的数据,尤其是在对标注准则或者流程不完善时,错标就更常见了,所以有个岗位叫数据审核师
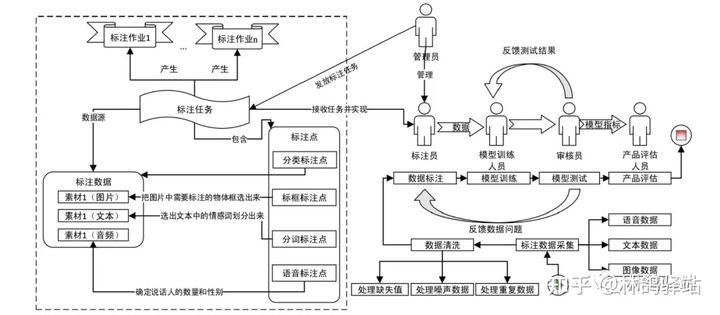
训练数据的质量对于模型表现至关重要。我们用一致性和标注数据准确率来评估质量。
这里说的数据包含了素材的数量、质量、和标注框的质量,这里重点说一下标注框质量是如何影响模型的准确性的。
目标矩形框太大、太小、位置是否偏移、目标类型标错,相当于你不断告诉神经网络目标是这样的那样的类型是什么什么,最后低质量的数据让神经网络真的"神经"了,影响了神经网络对矩形方框中真实内容的判断。实践证明,即使数据的数量和质量都很好,标注的框质量比较差也会导致模型效果越来越差。
保证标注框质量较高的几个点:框的大小合适、位置合适;类型准确;不要漏掉小目标;目标切断显示不全的也不要漏标;模糊的人无法判定的就不要了;标注多角度的目标(高质量的数据会包含多角度的素材)
参考: 改变标注质量,数据审核让人工智能变得更加精准 - 知乎
【如果对您有帮助,交个朋友给个一键三连吧,您的肯定是我博客高质量维护的动力!!!】

















 7204
7204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









