







global-to-local memory pointer networks for task-oriented dialogue
论文解决的问题:在任务型对话系统中有效地利用外部知识库信息
模型:使用GLMP全局到本地记忆指针网络解决上述问题
Introduction
目前对话系统面临的一个问题是,端到端的学习很难将外部的知识库和生成的系统回复结合起来。主要原因是一个大型的动态知识库很难去编码和解码。而且在任务型对话中,对于外部知识库的依赖变得很大,很多时候回答中是直接复制了知识库中的知识。现有的Mem2Seq还有copy机制都有效地解决了这个问题,但是有时候生成的回复显得有些机器化。文中提出了GLMP模型来解决更有效地利用外部知识库的问题。
GLMP模型
文中提出的GLMP包括3个部分,全局内存编码器,本地内存编码器,共享外部知识库。
系统的输入是知识库B,对话历史X
输出是系统回答Y
第一步,全局内存编码器使用context RNN来编码对话历史,并且将它的隐藏层写入外部的知识库;其中最后一个隐藏层可以同时读外部知识库并且生成全局内存指针。
另一边,在解码阶段,本地内存解码器首先使用sketch RNN生成一个简略的回答。然后全局内存指针和sketch RNN的隐藏层传到外部知识库中作为筛选和查询器。本地内存指针从外部知识返回时可以将外部知识中的text复制到sketch标签上来生成一个最终的系统回答
共享外部知识库
共享外部知识库包含全局上下文表示,是编码器和解码器共享的,由两个部分组成:知识库KB,对话历史。
全局上下文表示
- 知识条目
每个知识条目都以三元组的形式呈现,(Subject, Relation, Object)。如:星巴克的地址是xxx,那么相应的条目就是(Starbucks,address, 792 Bedoin St) - 对话历史
每个对话中的一句话都被按照一种特定格式来编码,也是以一种三元组的形式表示,比如有一句话是:I need gas。那么就会被编码为 {( u s e r , t u r n 1 , I ) , ( user, turn1, I), ( user,turn1,I),(user, turn1, need), ($user, turn1, gas)}
对于这两个部分,都采用Bow词袋表示。在引用外部知识时,会将object部分提取出来放到生成的句子中。
读取和写入知识
外部知识是由一组可训练的嵌入矩阵组成的,
K是memory network中的最大跳数(这里不是很懂,涉及到了另外一篇论文)。V是词库的大小,Demb是embedding的维度。将外部知识库用M=[B : X] = {m1, m2, …, }来表示。每一个m就是上面所说的三元组。为了读取相应的条目,需要传给外部知识一个起始查询向量q1,通过循环k跳来计算权重
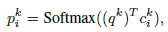
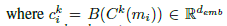
c是位置i处的embedding向量,q是第k跳的查询向量,B是Bow函数。这里pk是一个软的记忆,体现了查询向量的相关性。然后,通过如下的计算来更新查询向量
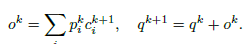
全局内存编码器

上下文RNN用于对序列依赖性进行建模并对上下文X进行编码。再将隐层状态写入外部知识。然后,最后一个编码器的隐层状态当作查询读取外部知识并获得两个输出,即全局内存指针(the global memory pointer)和内存读出(the memory readout)。
将隐藏状态写入外部知识可以提供序列和上下文信息。所以我们的指针可以正确地复制外部知识中的单词,并且可以减轻常见的OOV问题
ContextRNN
使用双向GRU将对话历史编码为隐藏层状态H,最后一个隐藏层状态h作为对话历史的编码用来查询外部知识库。同时,H将被存到知识库中的对话历史中,保存的方式是把原始的存储表示和相应的隐藏层状态相加。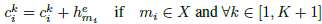
全局内存指针
全局内存指针 ,其中的每一个分量都是0至1间的浮点数,与注意力机制不同的地方在于,所有的分量和不是1,每个分量都是独立的。首先使用上边的对话历史中最后一个隐藏层状态h来查询外部知识,直到最后一跳,然后做内积,过sigmoid函数。这样获得的内存分布就是全局内存指针G,将会被传递到解码器。最后Qk+1就是编码后的知识信息。
,其中的每一个分量都是0至1间的浮点数,与注意力机制不同的地方在于,所有的分量和不是1,每个分量都是独立的。首先使用上边的对话历史中最后一个隐藏层状态h来查询外部知识,直到最后一跳,然后做内积,过sigmoid函数。这样获得的内存分布就是全局内存指针G,将会被传递到解码器。最后Qk+1就是编码后的知识信息。
为了进一步增强全局指针的能力,作者增加了辅助的损失函数来对全局内存指针进行多分类任务训练。发现有助于提高模型表现。
本地内存指针
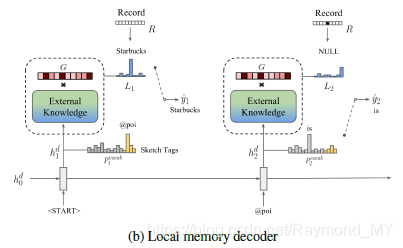
给出编码好的对话历史信息h(也就是contextRNN中的最后一个隐藏层状态),编码好的知识库信息q,还有全局内存指针G。本地内存指针首先利用h和q的拼接来生成一个简略回复,比如,生成了 “@poi is @distance away”。在解码阶段的每一步中,sketch RNN隐藏层状态有两个用途
- 1.和标准的序列到序列模型学习相同,预测下一个词汇表中的标记
- 2.作为查询外部知识的向量。
sketch RNN
使用GRU来生成回答的简略描述,注意生成的回复中是没有插入槽的,但是回生成一些特殊的符号,比如以@开头,比如,生成了 “@poi is @distance away”,其中带有@的词就会被外部知识替换,其余的词保持原样。
本地内存指针
本地内存指针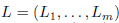 包含一系列时序的指针。在每个时间t,全局内存指针用它的注意力权重首先修改全局上下文表示
包含一系列时序的指针。在每个时间t,全局内存指针用它的注意力权重首先修改全局上下文表示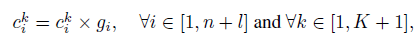
然后用context RNN的隐藏状态h来查询外部知识。最后一跳中的内存注意对应的就是本地内存指针Lt,其表示为在时间步骤t上的内存分布。
为了训练本地内存指针,增加了对外部知识中最后一跳memory attention的监督。我们首先在解码时间步骤t中定义本地内存指针L的位置标签。
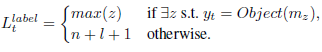
位置n+l+1是memory中的空标记,即使外部知识中不存在相应的y,也可以来计算损失函数。 另外,利用记录  来防止多次复制相同的实体。 也就是说R中的所有元素在开始时初始化为1, 在解码阶段如果指向了存储位置,则其在R中的相应位置将被屏蔽掉。 在推理期间, y 被定义为
来防止多次复制相同的实体。 也就是说R中的所有元素在开始时初始化为1, 在解码阶段如果指向了存储位置,则其在R中的相应位置将被屏蔽掉。 在推理期间, y 被定义为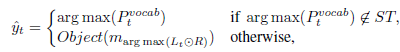
实验
略














 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









