






官方文档地址 https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#define-loops
非顺序结构,其内容确实有点乱,而且没有完整可运行的样例。
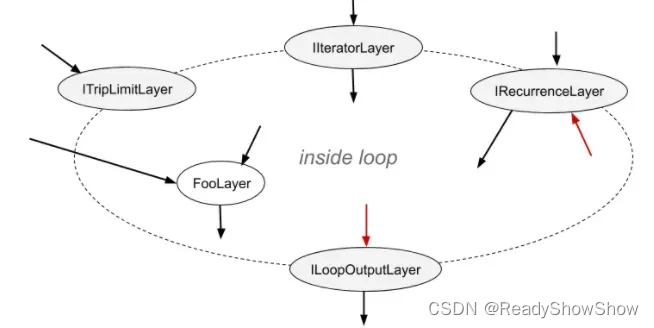
可以有多个IIteratorLayer, IRecurrenceLayer, and ILoopOutputLayer 层,最多有2个ITripLimitLayers层。
这里贴2个可运行的代码样例,分别是2种ITripLimitLayers层(TripLimit::kCOUNT 、 TripLimit::kWHILE),简单可运行的代码以帮助入门:
trt.TripLimit.COUNT
loop.add_trip_limit(trip_limit.get_output(0), trt.TripLimit.COUNT)
trt.TripLimit.WHILE
实现类似于for(i = 0; i<3;i++)
i_init = network.add_constant(shape=(), weights=trt.Weights(np.array([0], dtype=np.dtype("i"))))
i_one = network.add_constant(shape=(), weights=trt.Weights(np.array([1], dtype=np.dtype("i"))))
i_stop = network.add_constant(shape=(), weights=trt.Weights(np.array([num_iterations], dtype=np.dtype("i"))))
iRec = loop.add_recurrence(i_init.get_output(0))
iContinue = network.add_elementwise(iRec.get_output(0), i_stop.get_output(0), op=trt.ElementWiseOperation.LESS)
loop.add_trip_limit(iContinue.get_output(0), trt.TripLimit.WHILE)
iNext = network.add_elementwise(iRec.get_output(0), i_one.get_output(0), op=trt.ElementWiseOperation.SUM)
iRec.set_input(1, iNext.get_output(0))
可运行的完整样例
import numpy as np
import tensorrt as trt
from tensorrt import INetworkDefinition
from trt_inference import TRTInference
logger = trt.Logger(trt.Logger.WARNING)
# class MyLogger(trt.ILogger):
# def __init__(self):
# trt.ILogger.__init__(self)
# def log(self, severity, msg):
# pass # Your custom logging implementation here
# logger = MyLogger()
builder = trt.Builder(logger)
network = builder.create_network(trt.NetworkDefinitionCreationFlag.EXPLICIT_PRECISION)
num_iterations = 3
trip_limit = network.add_constant(shape=(), weights=trt.Weights(np.array([num_iterations], dtype=np.dtype("i"))))
accumaltor_value = network.add_input("input1", dtype=trt.float32, shape=(2, 3))
accumaltor_added_value = network.add_input("input2", dtype=trt.float32, shape=(2, 3))
loop = network.add_loop()
# setting the ITripLimit layer to stop after `num_iterations` iterations
loop.add_trip_limit(trip_limit.get_output(0), trt.TripLimit.COUNT)
# initialzing the IRecurrenceLayer with a init value
rec = loop.add_recurrence(accumaltor_value)
# eltwise inputs are 'accumaltor_added_value', and the IRecurrenceLayer output.
eltwise = network.add_elementwise(accumaltor_added_value, rec.get_output(0), op=trt.ElementWiseOperation.SUM)
# wiring the IRecurrenceLayer with the output of eltwise.
# The IRecurrenceLayer output would now be `accumaltor_value` for the first iteration, and the eltwise output for any other iteration
rec.set_input(1, eltwise.get_output(0))
# marking the IRecurrenceLayer output as the Loop output
loop_out = loop.add_loop_output(rec.get_output(0), trt.LoopOutput.LAST_VALUE)
# marking the Loop output as the network output
network.mark_output(loop_out.get_output(0))
inputs = {}
outputs = {}
expected = {}
inputs[accumaltor_value.name] = np.array(
[
[2.7, -4.9, 23.34],
[8.9, 10.3, -19.8],
])
inputs[accumaltor_added_value.name] = np.array(
[
[1.1, 2.2, 3.3],
[-5.7, 1.3, 4.6],
])
outputs[loop_out.get_output(0).name] = eltwise.get_input(0).shape
expected[loop_out.get_output(0).name] = inputs[accumaltor_value.name] + inputs[accumaltor_added_value.name] * num_iterations
print("Expected:", expected)
builder_config = builder.create_builder_config()
builder_config.set_flag(trt.BuilderFlag.VERSION_COMPATIBLE)
builder_config.set_flag(trt.BuilderFlag.EXCLUDE_LEAN_RUNTIME)
plan = builder.build_serialized_network(network, builder_config)
# v10_runtime = trt.Runtime(logger)
# v8_shim_runtime = v10_runtime.load_runtime('/home/mark.yj/TensorRT-8.6.1.6/bin/trtexec')
# engine = v10_runtime.deserialize_cuda_engine(plan)
trtInfer = TRTInference(plan)
r = trtInfer.infer(inputs, outputs)
print("Prediction:", r)















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









