







使用高级分析算法(如大规模机器学习、图形分析和统计建模等)来发现和探索数据是当前流行的思路,在IDF16技术课堂上,英特尔公司软件开发工程师王以恒分享了《基于Apache Spark的机器学习及神经网络算法和应用》的课程,介绍了大规模分布式机器学习在欺诈检测、用户行为预测(稀疏逻辑回归)中的实际应用,以及英特尔在LDA、Word2Vec、CNN、稀疏KMeans和参数服务器等方面的一些支持或优化工作。
当前的机器学习/深度学习库很多,用Spark支撑分布式机器学习和深度神经网络,主要是基于两点考虑:
- 大数据平台的统一性。因为随着Spark特性,分析团队越来越喜欢用Spark作为大数据平台,而机器学习/深度学习也离不开大数据。
- 其他的一些框架(主要是深度学习框架,如Caffe)对多机并行支持不好。
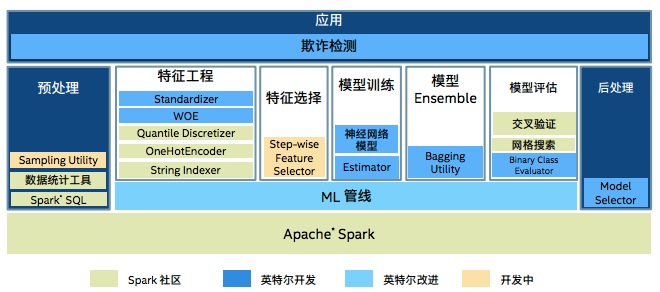
在某顶级支付公司的端到端大数据解决方案中,英特尔开发的Standardizer、WOE、神经网络模型、Estimator、Bagging Utility等都被应用,并且ML管线也由英特尔改进。
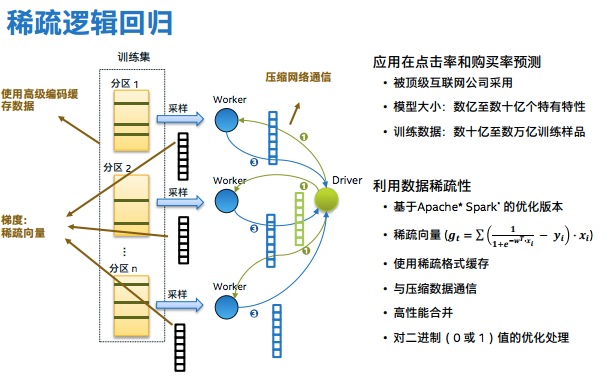
稀疏逻辑回归主要解决了网络和内存瓶颈的问题,因为大规模学习,每次迭代广播至每个Worker的的权重和每个任务发送的梯度都是双精度向量,非常巨大。英特尔利用数据稀疏性,使用高级编码缓存数据(使用稀疏格式缓存),压缩数据通信,并对二进制值优化处理,最后得到的梯度是稀疏向量。
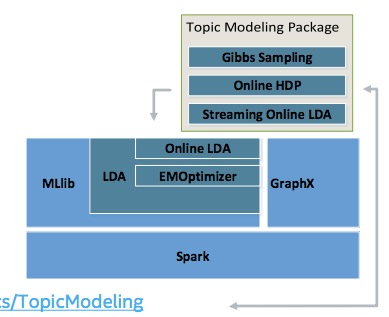
基于Apache Spark的大规模主题模型正在开发中(https://github.com/intel-analytics/TopicModeling)。
Spark上的分布式神经网络,Driver广播权重和偏差到每个Worker,这与稀疏逻辑回归有类似之处,英特尔将神经网络与经过优化的英特尔数学核心函数库(支持英特尔架构加速)集成。
面向Spark的参数服务器的工作,包括数据模型、支持的操作、同步模型、容错、集成GraphX等,通过可变参数作为系统上的补充,实现更好的性能和容错性,相当于将两个架构仅仅做系统整合(Yarn之上)。由于模型并行的复杂性,英特尔团队目前也还没有考虑模型并行的工作。















 2437
2437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









