







第十三章 集合(Collection、数据结构、List、泛型深入)
文章目录
前言
一、集合概述
集合和数组都是容器。
数组的特点

- 数组定义完成并启动后,类型确定、长度固定。
- 在进行增删数据操作的时候,数组是不太合适的,增删数据都需要放弃原有数组或者移位。
数组适合的场景
- 当业务数据的个数是固定的,且都是同一批数据类型的时候,可以采用定义数组存储。
举例说明
存储四种花色

集合是Java中存储对象数据的一种容器。
集合的特点

- 集合的大小不固定,启动后可以动态变化,类型也可以选择不固定。集合更像气球。
- 集合非常适合做元素的增删操作。
注意:集合中只能存储引用类型数据,如果要存储基本类型数据可以选用包装类。
集合适合的场景
- 数据的个数不确定,需要进行增删元素的时候。

二、Collection集合的体系特点
集合类体系结构
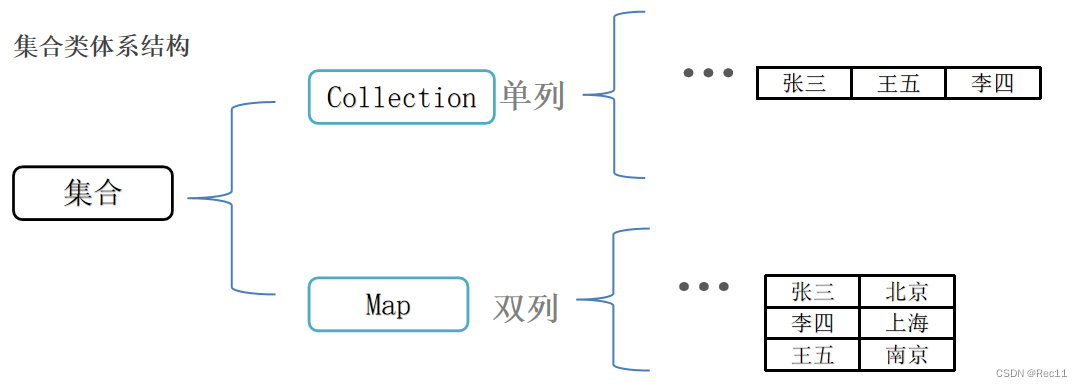
- Collection单列集合,每个元素(数据)只包含一个值。
- Map双列集合,每个元素包含两个值(键值对)。
注意:前期先掌握Collection集合体系的使用。
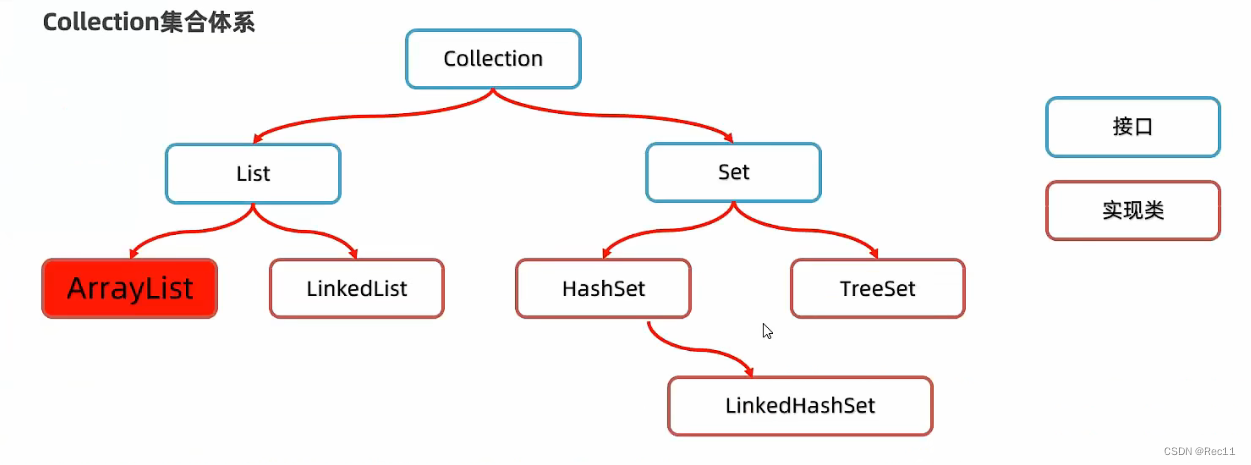
Collection集合特点
- List系列集合:添加的元素是有序、可重复、有索引。
▲ArraysList、LinkedList:有序、可重复、有索引。 - Set系列集合:添加的元素是无序的、不重复、无索引。
▲HashSet:无序、不重复、无索引;LinkedHashSet:有序、不重复、无索引。
▲TreeSet:按照大小默认升序排序、不重复、无索引。
集合对于泛型的支持
- 集合都是支持泛型的,可以在编译阶段约束集合只能操作某种数据类型

注意:集合和泛型都只能支持引用数据类型,不支持基本数据类型,所以集合中存储的元素都认为是对象。


三、Collection集合常用API
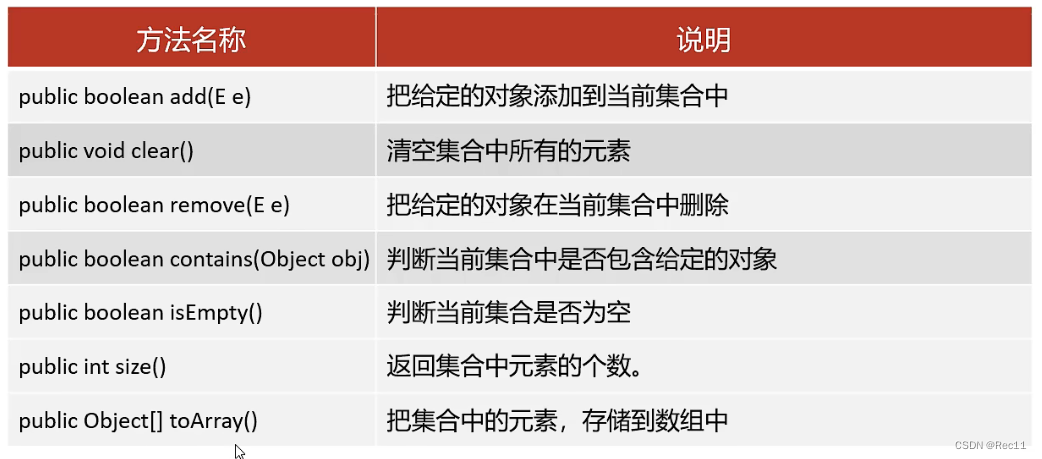
Collection集合
- Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的。
Collection API如下:
四、Collection集合的遍历方式
方式一:迭代器
迭代器遍历概述
- 遍历就是一个一个的把容器中的元素访问一遍。
- 迭代器在Java中的代表是Iterator,迭代器是集合的专用遍历方式。
Collection集合获取迭代器

Iterator中的常用方法


方式二:foreach / 增强for循环
增强for循环
- 增强for循环:既可以遍历集合也可以遍历数组。
- 它是JDK 5之后出现的,其内部原理是一个Iterator迭代器,遍历集合相当于是迭代器的简化写法。
- 实现Iterable接口的类才可以使用迭代器和增强for,Collection接口已经实现了Iterable接口。
格式


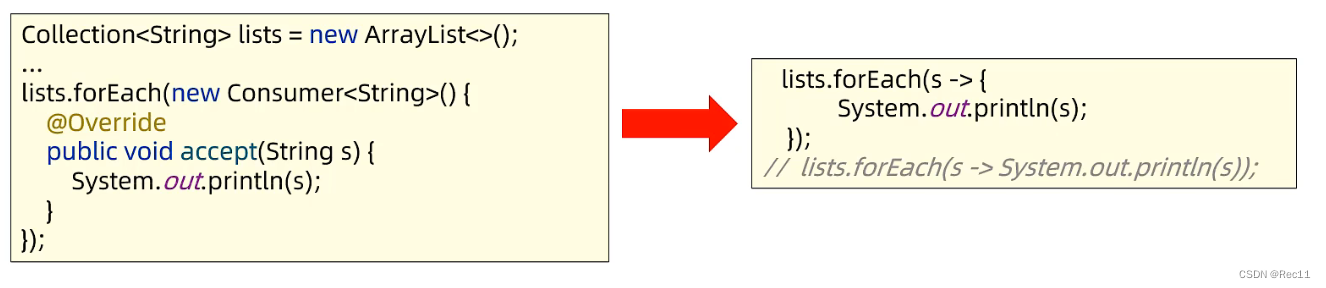
方式三:lambda表达式
Lambda表达式遍历集合
- 得益于JDK 8开始的新技术Lambda表达式,提供了一种更简单、更直接的遍历集合的方式。
Collection结合Lambda便利的API

五、Collection集合存储自定义类型的对象

Movie.java
public class Movie {
private String name;
private double score;
private String actor;
public Movie() {
}
public Movie(String name, double score, String actor) {
this.name = name;
this.score = score;
this.actor = actor;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
public String getActor() {
return actor;
}
public void setActor(String actor) {
this.actor = actor;
}
}
TestDemo.java
import java.util.ArrayList;
import java.util.Collection;
public class TestDemo {
public static void main(String[] args) {
// 1、定义一个电影类
// 2、定义一个集合对象存储3部电影对象
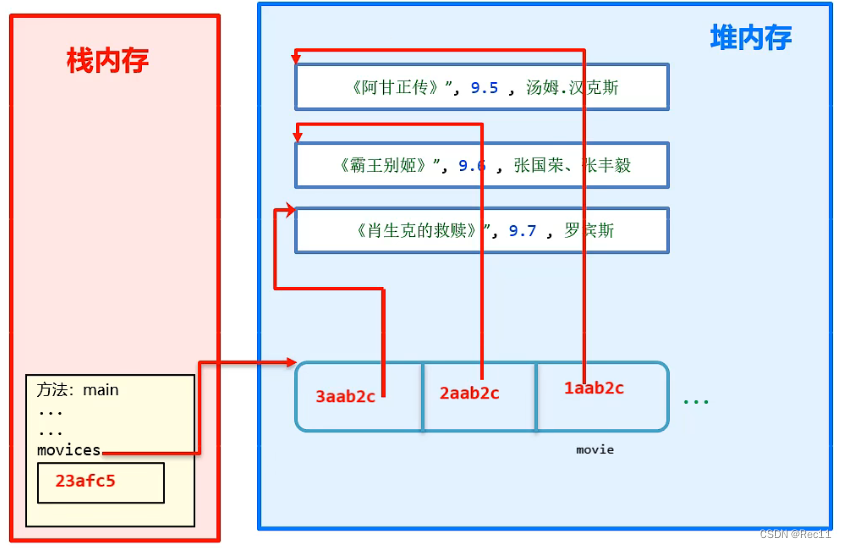
Collection<Movie> movies = new ArrayList<>();
movies.add(new Movie("《你好,李焕英》", 9.5, "张小斐,贾玲,沈腾,陈赫"));
movies.add(new Movie("《唐人街探案》", 8.5, "王宝强,刘昊然,美女"));
movies.add(new Movie("《刺杀小说家》",8.6, "雷佳音,杨幂"));
System.out.println(movies);
// 3、遍历集合容器中的每个电影对象
for (Movie movie : movies) {
System.out.println("片名:" + movie.getName());
System.out.println("评分:" + movie.getScore());
System.out.println("主演:" + movie.getActor());
}
}
}

六、常见数据结构
1、数据结构概述、栈、队列
数据结构概述
- 数据结构是计算机底层存储、组织数据的方式。是指数据相互之间是以什么方式排列在一起的。
- 通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率
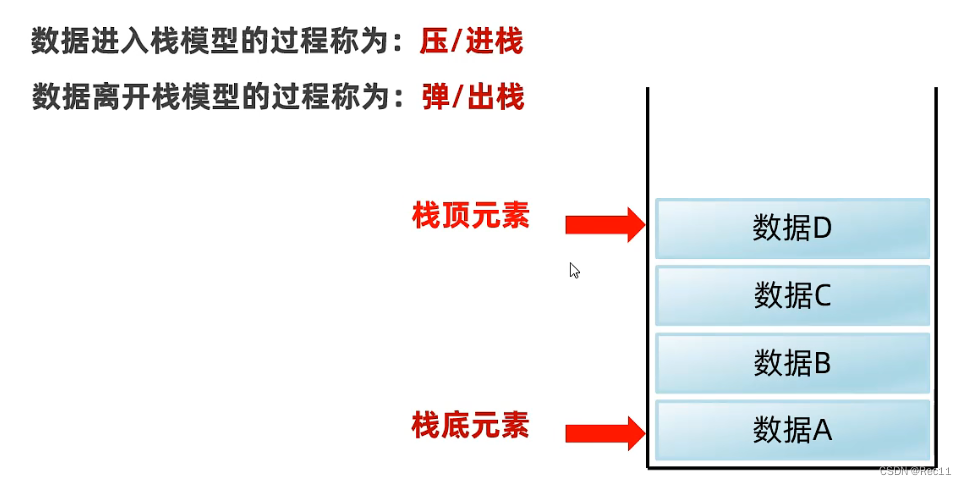
栈数据结构的执行特点
- 后进先出,先进后出
常见数据结构之队列
- 先进先出,后进后出

2、数组
数组是一种查询快,增删慢的模型。
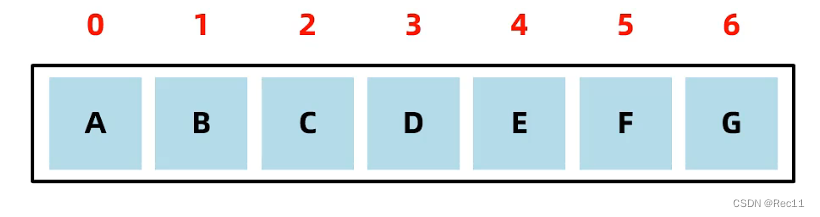
- 查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同。(元素在内存中是连续存储的)
- 删除效率低:要将原始数据删除,同时后面每个数据前移。
- 添加效率极低:添加位置后的每个数据后移,再添加元素。
3、链表
链表的特点
- 链表中的元素是在内存中不连续存储的,每个元素节点包含数据值和下一个元素的地址。
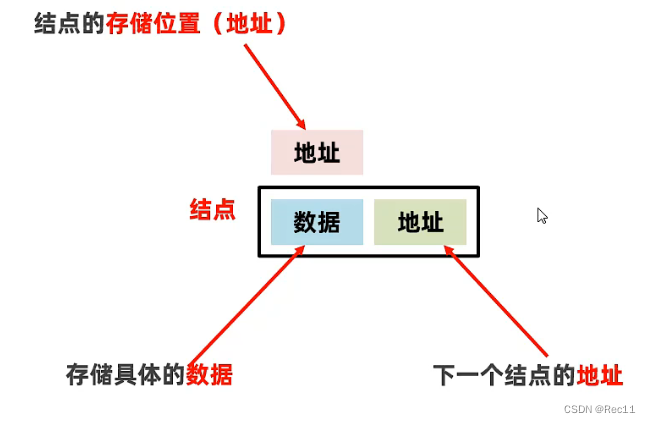
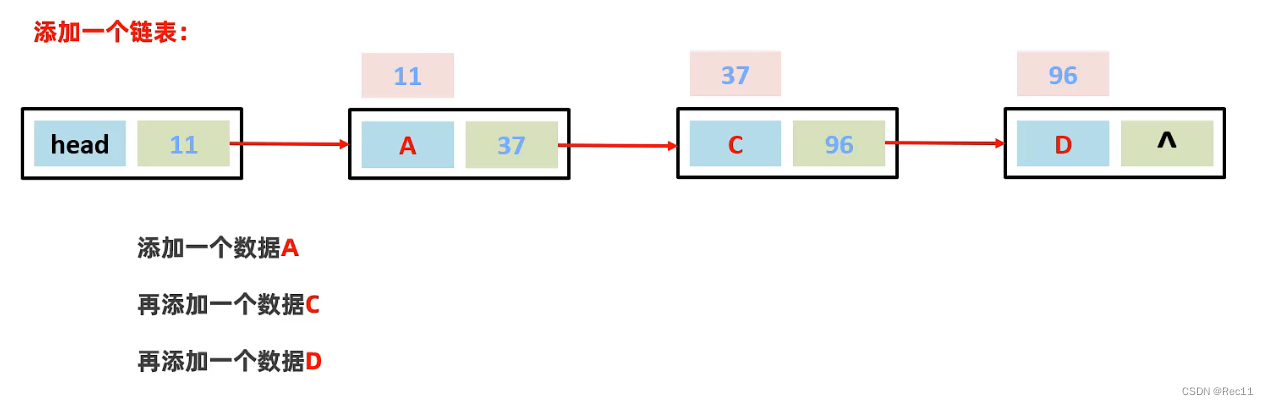
- 链表中的元素是游离存储的,每个元素节点包含数据值和下一个元素的地址。
- 链表查询慢。无论查询哪个数据都要从头开始找
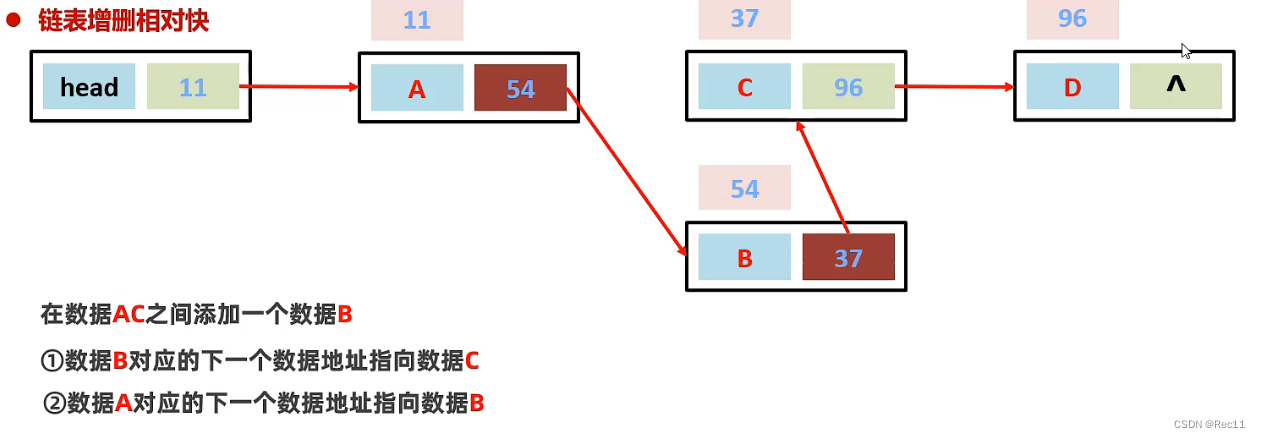
- 链表增删相对快。

4、二叉树、二叉查找树
二叉树概述
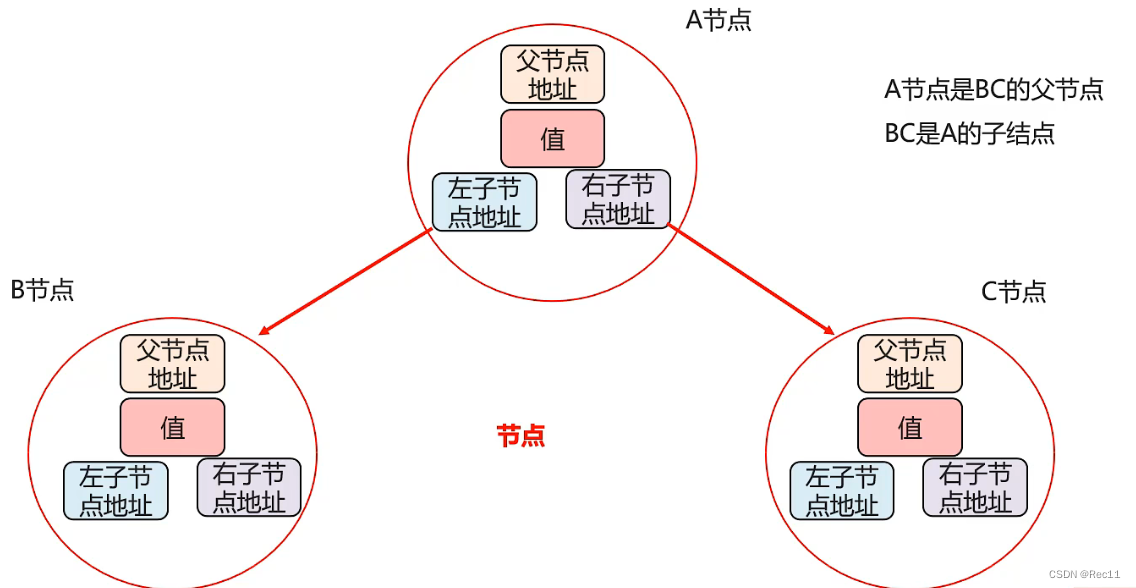
二叉树的特点
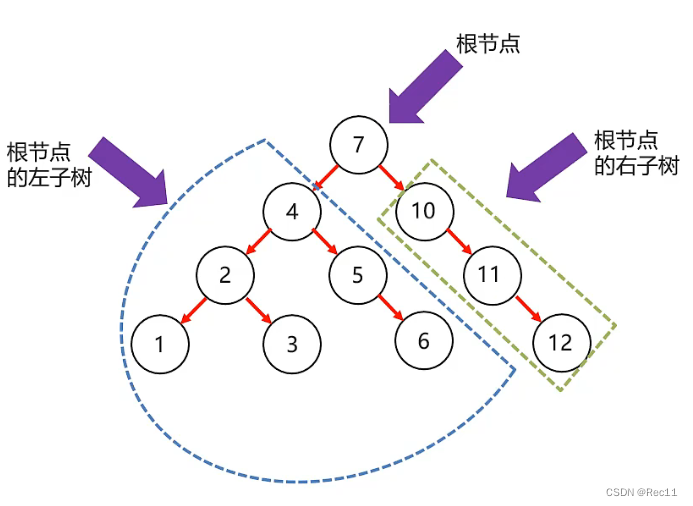
- 只能有一个根节点,每个节点最多支持2个直接子节点。
- 节点的度:节点拥有的子树的个数,二叉树的度不大于2
叶子节点:度位0的节点,也称之为终端结点。 - 高度:叶子结点的高度位1.叶子结点的父节点高度为2,以此类推,根节点的高度最高。
- 层:根节点在第一层,以此类推
- 兄弟节点:拥有共同父节点的节点互称为兄弟节点。
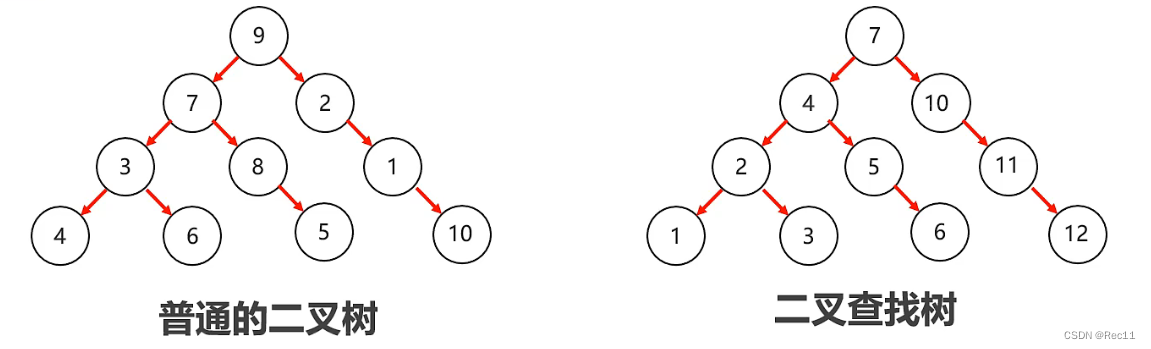
二叉查找树又称二叉排序树或者二叉搜索树。
目的:提高检索数据的性能。
特点:
- 每一个节点上最多有两个子节点
- 左子树上所有节点的值都小于根节点的值
- 右子树上所有节点的值都大于根结点的值
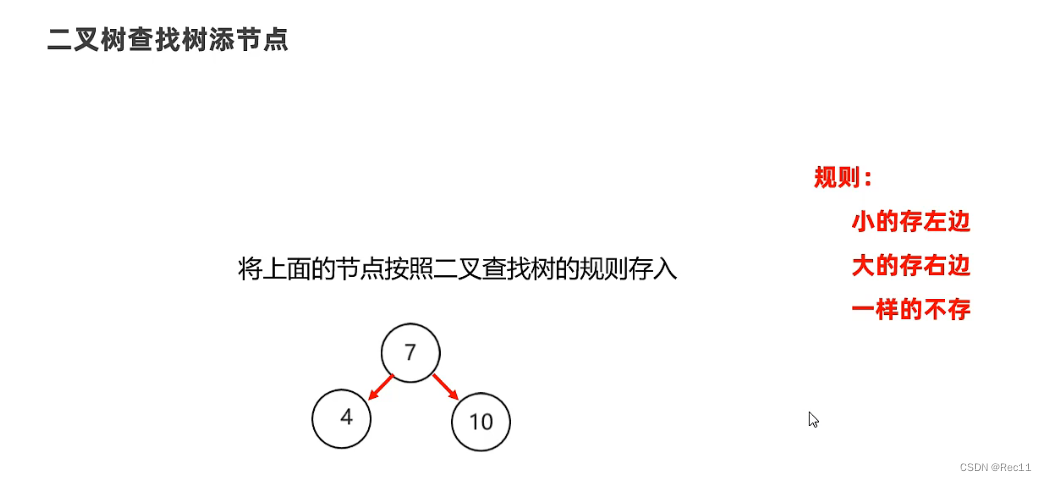
5、平衡二叉树
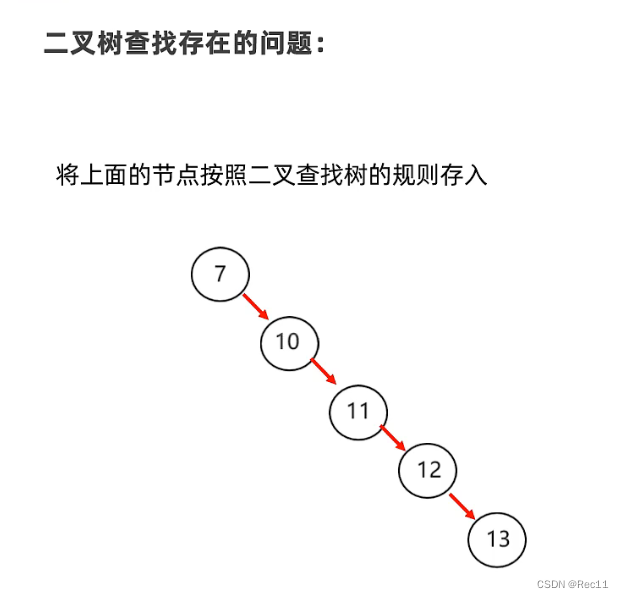
问题:出现瘸子现象,导致查询的性能与单链表一样,查询速度变慢!
数据结构–平衡二叉树
- 平衡二叉树实在满足查找二叉树的大小规则下,让树尽可能矮小,以此提高查数据的性能。
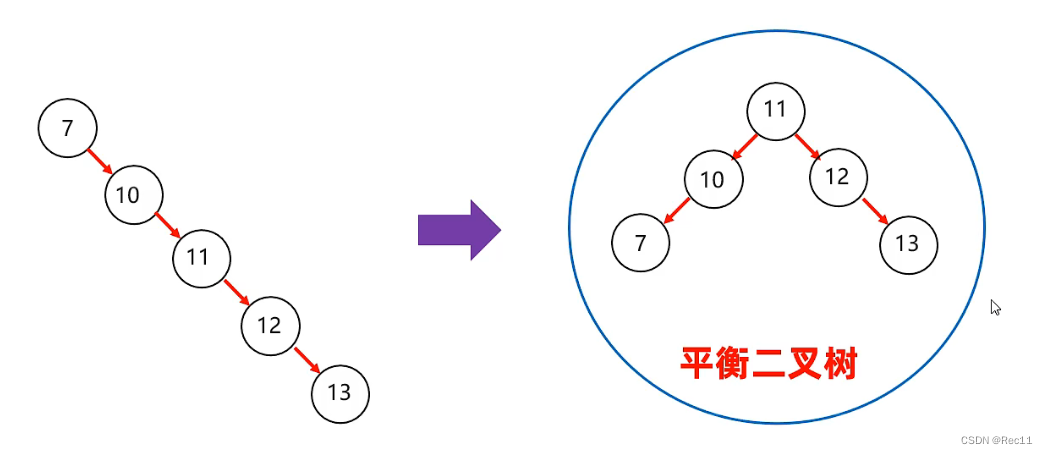
平衡二叉树的要求
- 任意节点的左右两个子树的高度差不超过1,任意节点的左右两个子树都是一颗平衡二叉树
平衡二叉树在添加元素后可能导致不平衡
- 基本策略是进行左旋,或者右旋保证平衡。
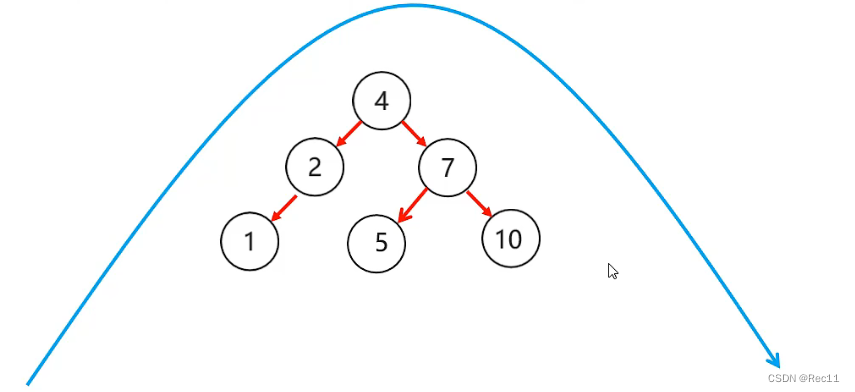
平衡二叉树–左左
- 左左
当根节点左子树的左子树有节点插入,导致二叉树不平衡
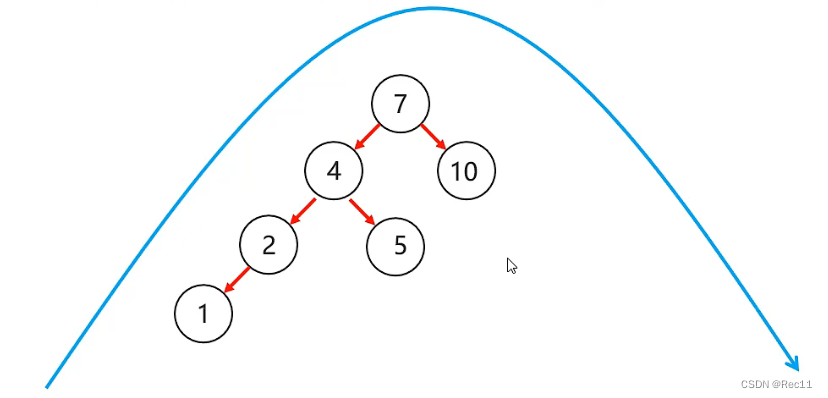
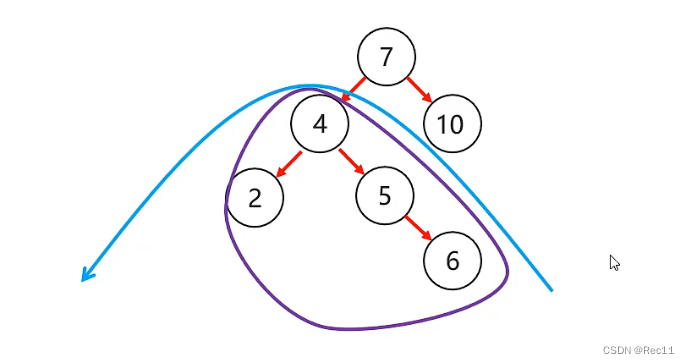
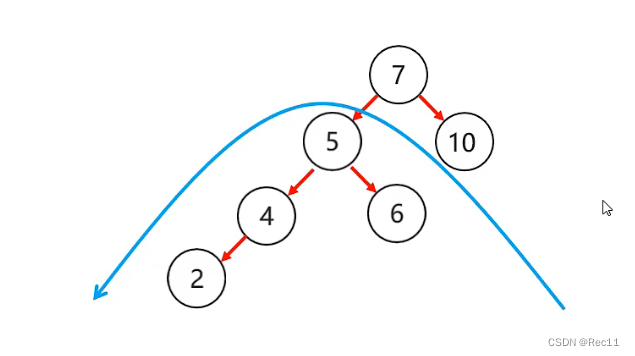
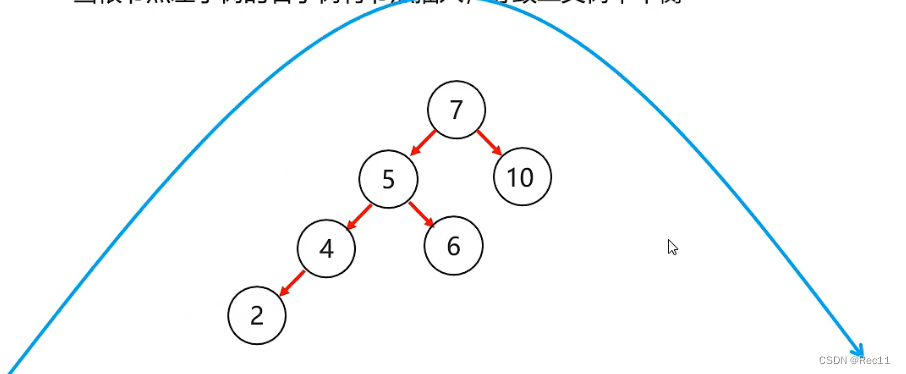
平衡二叉树–左右
- 左右
当根节点左子树的右子树有节点插入,导致二叉树不平衡
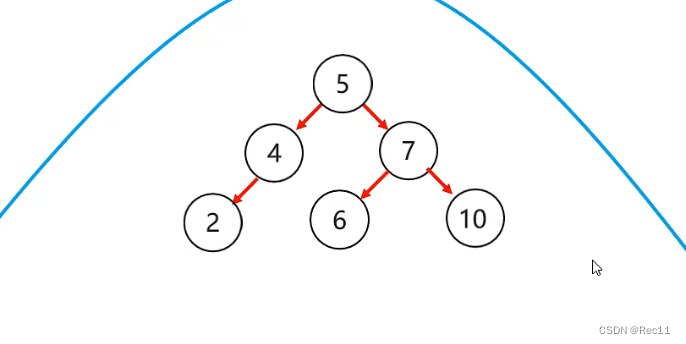
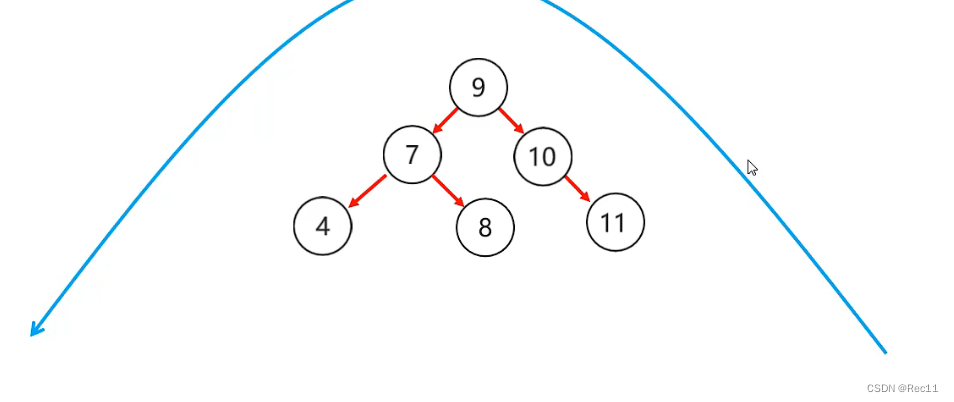
平衡二叉树–右右
- 右右
当根节点右子树的右子树有节点插入,导致二叉树不平衡
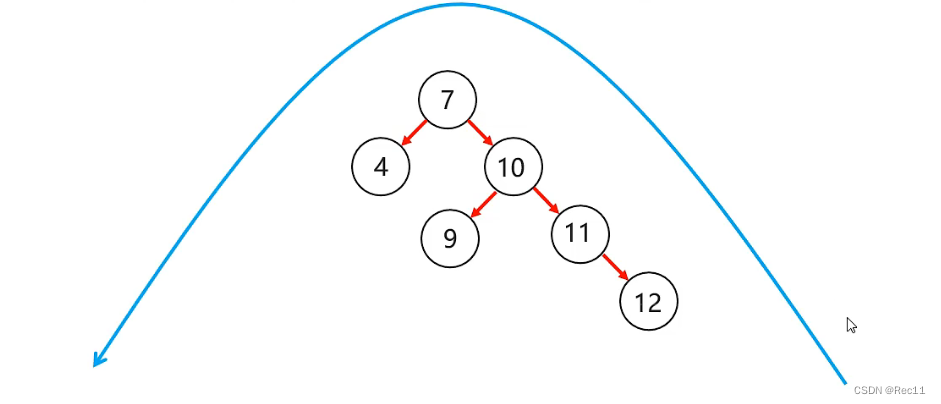
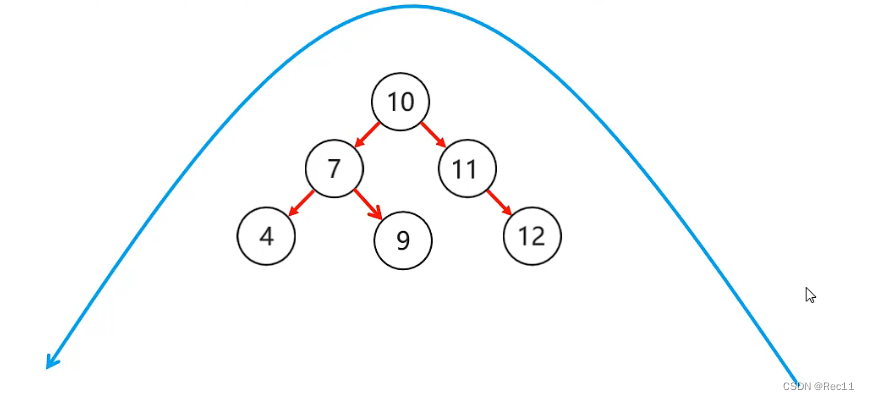
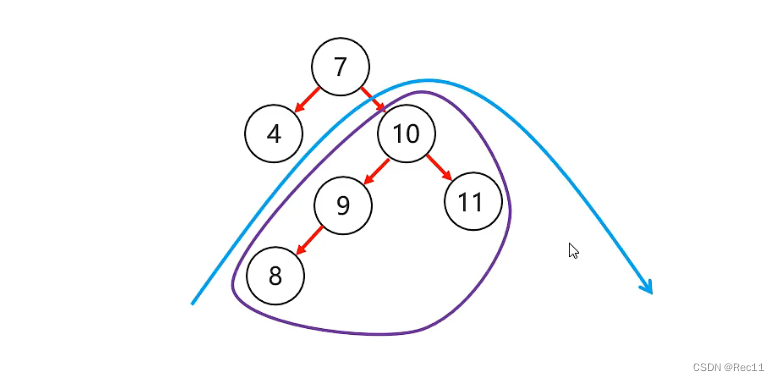
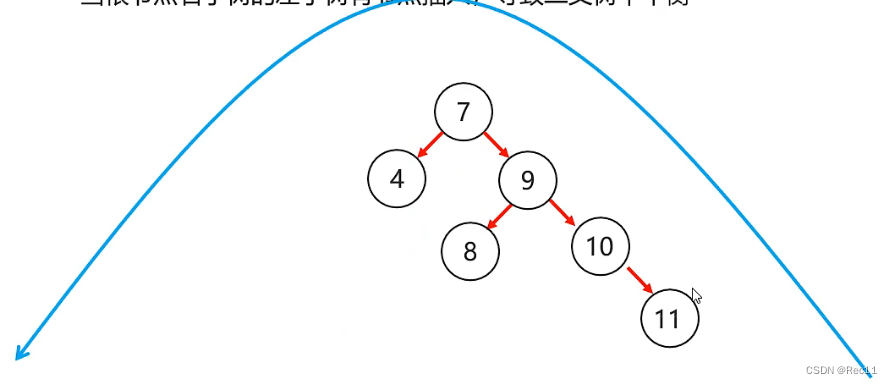
平衡二叉树–右左
- 右左
当根节点右子树的左子树有节点插入,导致二叉树不平衡
6、红黑树
红黑树概述
- 红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构。
- 1972年出现,当时被称之为平衡二叉B树。1978年被修改位如今的“红黑树”。
- 每一个节点可以是红或者黑;红黑树不是通过高度平衡的,它的平衡是通过“红黑规则”进行实现的。
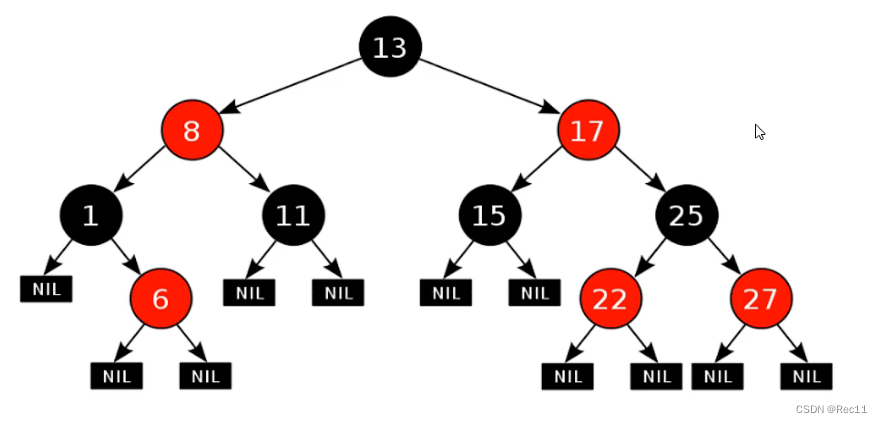
红黑规则
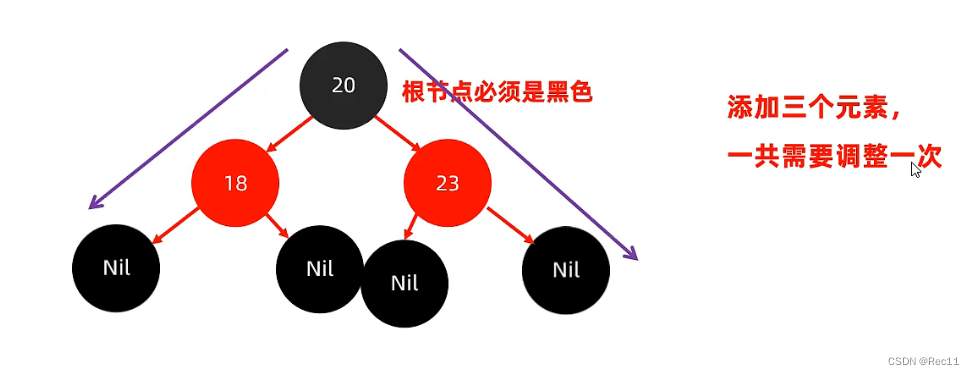
- 每一个节点或是红色的,或者是黑色的,根节点必须是黑色。
- 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值位Nil,这些Nil视为叶节点,叶节点是黑色的。
- 如果某一节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)。
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点。
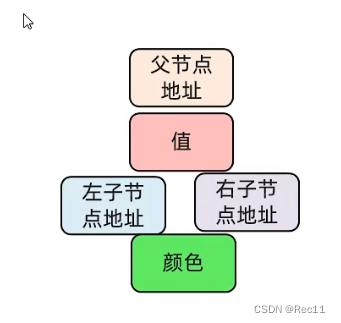
添加节点 - 添加的节点的颜色,可以是红色的,也可以是黑色的。
- 默认用红色效率高。
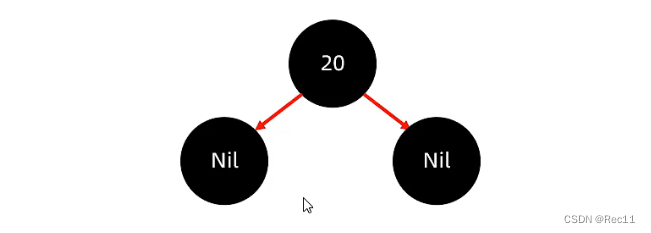
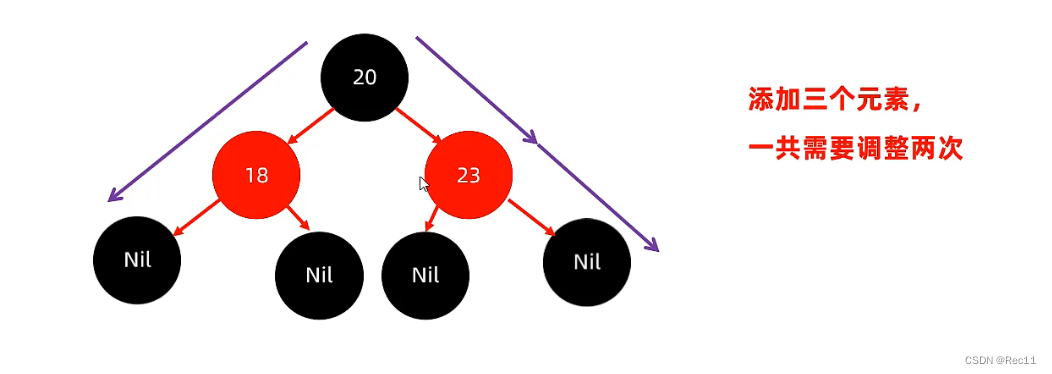
默认用红色

七、List系列集合
1、List集合特点、特有API
List系列集合特点
- ArrayList、LinkedList:有序,可重复,有索引。
- 有序:存储和取出的元素顺序一致
- 有索引:可以通过索引操作元素
- 可重复:存储的元素可以重复
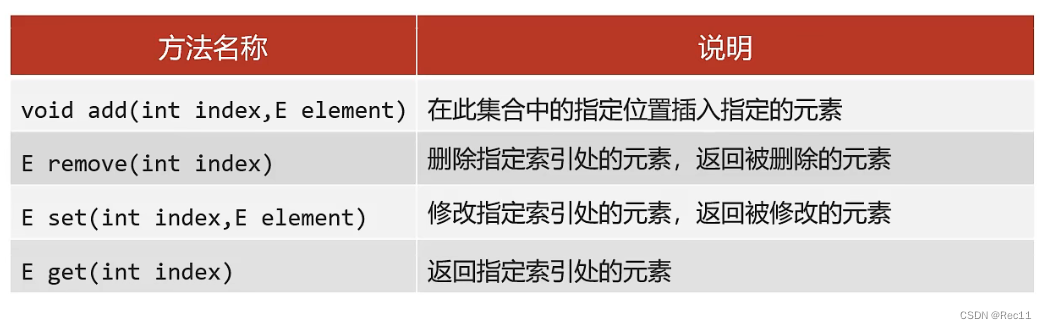
List集合特有方法
- List集合因为支持索引,所以多了索引操作的独特API,其他Collection的功能List也都继承了。

2、List集合的遍历方式小结
List集合的遍历方式有几种?
- 迭代器
- 增强for循环
- Lambda表达式
- for循环(因为List集合存在索引)
3、ArrayList集合的底层原理
ArrayList集合的底层原理
- ArrayList底层是基于数组实现的;根据索引定位元素快,增删需要做元素的一位操作。
- 第一次创建集合并添加第一个元素的时候,在底层创建一个默认长度位10的数组。
size:当前集合中元素的个数
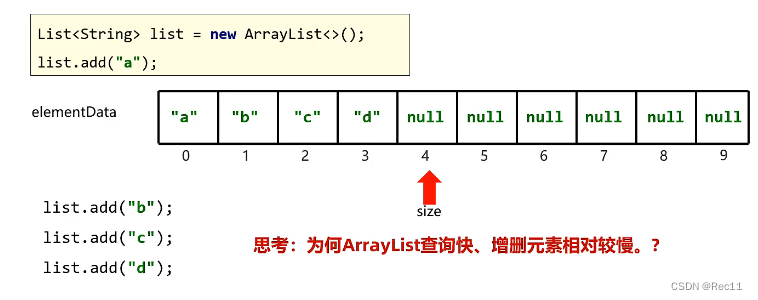
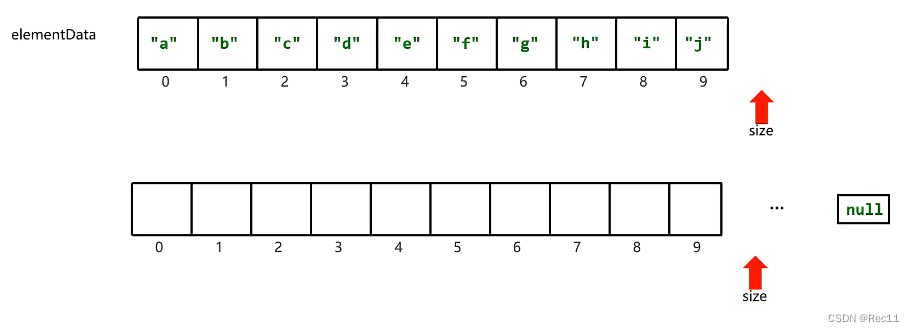
List集合存储的元素要超过容量怎么办?
当size>10,则会以1.5倍扩容,并迁移元素
4、LinkedList集合的底层原理
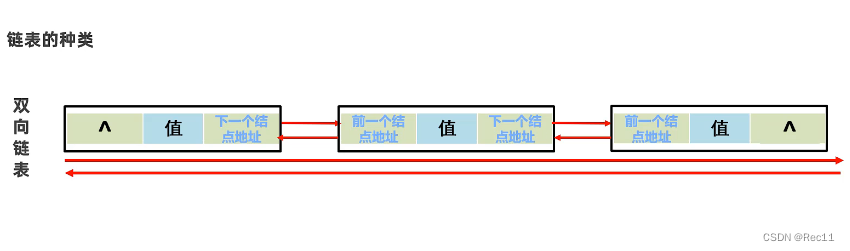
LinkedList的特点
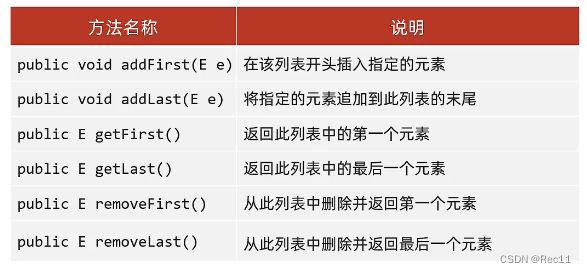
- 底层数据结构是双链表,查询慢,首尾操作的速度是极快的,所以多了很多首尾操作的特有API。
LinkedList集合的特有功能
补充知识:集合的并发修改异常问题
问题引出
- 当我们从集合中找出某个元素并删除的时候可能出现一种并发修改异常问题。
哪些遍历存在问题?
- 迭代器遍历集合且直接用集合删除元素的时候可能出现。
- 增强for循环遍历集合且直接用集合删除元素的时候可能出现。
哪种遍历且删除元素不出问题
- 迭代器遍历集合但是用迭代器自己的删除方法操作可以解决。
- 使用for循环遍历删除元素不会存在这个问题。
补充知识:泛型深入
1、泛型的概述和优势
泛型概述
- 泛型:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
- 泛型的格式:<数据类型>;泛型只能支持引用数据类型。
- 集合体系的全部接口和实现类都是支持泛型的使用的。
泛型的好处:
- 统一数据类型。
- 把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为编译阶段类型就能确定下来。
泛型可以在很多地方进行定义:
2、自定义泛型类
泛型类的概述
- 定义类时同时定义了泛型的类就是泛型类。
- 泛型类的格式:修饰符class 类名<泛型变量>{}

- 此处泛型变量T可以随便写为任意标识,常见的如E、T、K、V等。
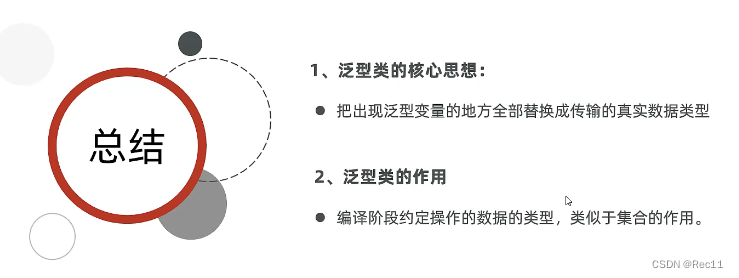
- 作用:编译阶段可以指定数据类型,类似于集合的作用。

泛型类的原理:
- 把出现泛型变量的地方全部替换成传输的真实数据类型。
3、自定义泛型方法
泛型方法的概述
- 定义方法时同时定义了泛型的方法就是泛型方法。
- 泛型方法的格式:修饰符<泛型变量> 方法返回值 方法名称(形参列表){}

- 作用:方法中可以使用泛型接收一切实际类型的参数,方法更具备通用性。

泛型方法的原理:
- 把出现泛型变量的地方全部替换成传输的真实数据类型。

4、自定义泛型接口
泛型接口的概述
- 使用了泛型定义的接口就是泛型接口。
- 泛型接口的格式:修饰符 interface 接口名称<泛型变量>{}

- 作用:泛型接口可以让实现类选择当前功能需要操作的数据类型

泛型接口的原理:
- 实现类可以在实现接口的时候传入自己操作的数据类型,这样重写的方法都将是针对于该类型的操作。

5、泛型通配符、上下限
通配符:?
- ?可以在 “使用泛型” 的时候代表一切类型。
- E T K V 是在定义泛型的时候使用的。
















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









