







一、实验目的
.
1) 了解KNN的基本概念;
2) 了解如何使用MindSpore进行KNN实验。
.
二、实验任务
.
使用MindSpore在部分wine数据集上进行KNN实验。
实验结果:

实验原理:
k近邻法(k-nearest neighbor,k-NN)是一种基本的分类和回归方法,是监督学习方法里的一种常用方法。k近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例类别,通过多数表决等方式进行预测。k近邻法三要素:距离度量、k值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的pL距离。k值小时,k近邻模型更复杂,容易发生过拟合;k值大时,k近邻模型更简单,又容易欠拟合。因此k值得选择会对分类结果产生重大影响。k值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的k 。分类决策规则往往是多数表决,即由输入实例的k个邻近输入实例中的多数类决定输入实例的类。
KNN算法优点:
简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
预测效果好。
对异常值不敏感
import os
# os.environ['DEVICE_ID'] = '4'
import csv
import numpy as np
import mindspore as ms
from mindspore import context
from mindspore import nn
from mindspore.ops import operations as P
from mindspore.ops import functional as F
context.set_context(device_target="CPU")
with open('wine.data') as csv_file:
data = list(csv.reader(csv_file, delimiter=','))
print(data[56:62]+data[130:133]) # 打印部分数据
X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
Y = np.array([s[0] for s in data[:178]], np.int32)
from matplotlib import pyplot as plt
%matplotlib inline
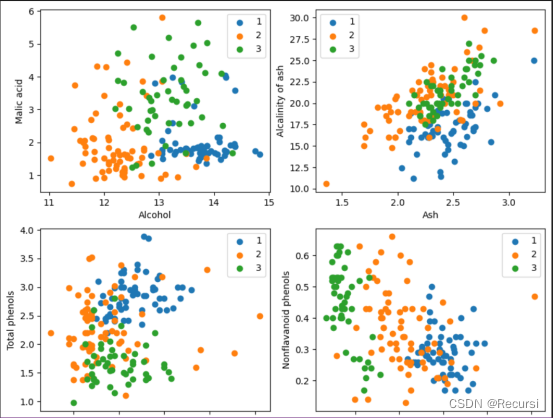
attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
'OD280/OD315 of diluted wines', 'Proline']
plt.figure(figsize=(10, 8))
for i in range(0, 4):
plt.subplot(2, 2, i+1)
a1, a2 = 2 * i, 2 * i + 1
plt.scatter(X[:59, a1], X[:59, a2], label='1')
plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
plt.scatter(X[130:, a1], X[130:, a2], label='3')
plt.xlabel(attrs[a1])
plt.ylabel(attrs[a2])
plt.legend()
plt.show()
train_idx = np.random.choice(178, 128, replace=False)
test_idx = np.array(list(set(range(178)) - set(train_idx)))
X_train, Y_train = X[train_idx], Y[train_idx]
X_test, Y_test = X[testclass KnnNet(nn.Cell):
def __init__(self, k):
super(KnnNet, self).__init__()
self.tile = P.Tile()
self.sum = P.ReduceSum()
self.topk = P.TopK()
self.k = k
def construct(self, x, X_train):
# Tile input x to match the number of samples in X_train
x_tile = self.tile(x, (128, 1))
square_diff = F.square(x_tile - X_train)
square_dist = self.sum(square_diff, 1)
dist = F.sqrt(square_dist)
# -dist mean the bigger the value is, the nearer the samples are
values, indices = self.topk(-dist, self.k)
return indices
def knn(knn_net, x, X_train, Y_train):
x, X_train = ms.Tensor(x), ms.Tensor(X_train)
indices = knn_net(x, X_train)
topk_cls = [0]*len(indices.asnumpy())
for idx in indices.asnumpy():
topk_cls[Y_train[idx]] += 1
cls = np.argmax(topk_cls)
return cls_idx], Y[test_idx]
acc = 0
knn_net = KnnNet(5)
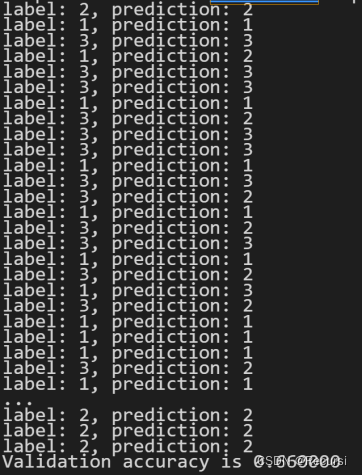
for x, y in zip(X_test, Y_test):
pred = knn(knn_net, x, X_train, Y_train)
acc += (pred == y)
print('label: %d, prediction: %s' % (y, pred))
print('Validation accuracy is %f' % (acc/len(Y_test)))
















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









