






声音的基础
声音是穿过可压缩介质的压力波(pressure wave)
- 声音的特性
- 振幅:使用电压水平测量某个位置的压力
- 频率:一秒内周期性振动的次数
- 耳蜗将鼓膜感受到的气压信号转化为大脑解释的声音
耳蜗 ---- 我们内耳中的一个器官,通过三个小骨头与鼓膜相连 耳蜗由充满液体的螺旋组织和数千根细毛组成
-
向下进入耳蜗时,毛发会变小
-
每根毛发都连接到一条神经,该神经馈送到通往大脑的听觉神经束
-
较长的毛发与较低频率的声音产生共鸣,较短的毛发与较高频率的声音产生共鸣
- 音频是人类可以听到的声音
-
频率响应(frequency response): 指频率范围
-
人类听觉20Hz-20kHz,人类对低频(3-4kHz)更敏感
-
幅度范围: 描述从最柔和到最响亮的声音幅度的频谱. 人类听觉可以容纳超过数百万倍的范围. 人类感知声音的范围很大,声音频率到了上限会让人类感到痛苦
- 语音(speech)是人类可以发出的声音
- 人耳在600Hz至6kHz范围内最敏感
- 人类可以非常有效地调整自己以适应不同的说话者及其言语习惯 :
语音分析: 说话人识别 ---- 识别说话者并进行验证。 语音识别 ---- 分析所说内容 以及某个陈述是如何说的 说话者依赖系统(speaker dependent system) : 更高的识别度15,000 个单词. 说话者独立系统(许多说话人): 识别率较低~500 个单词
获取数字化声音需要的步骤
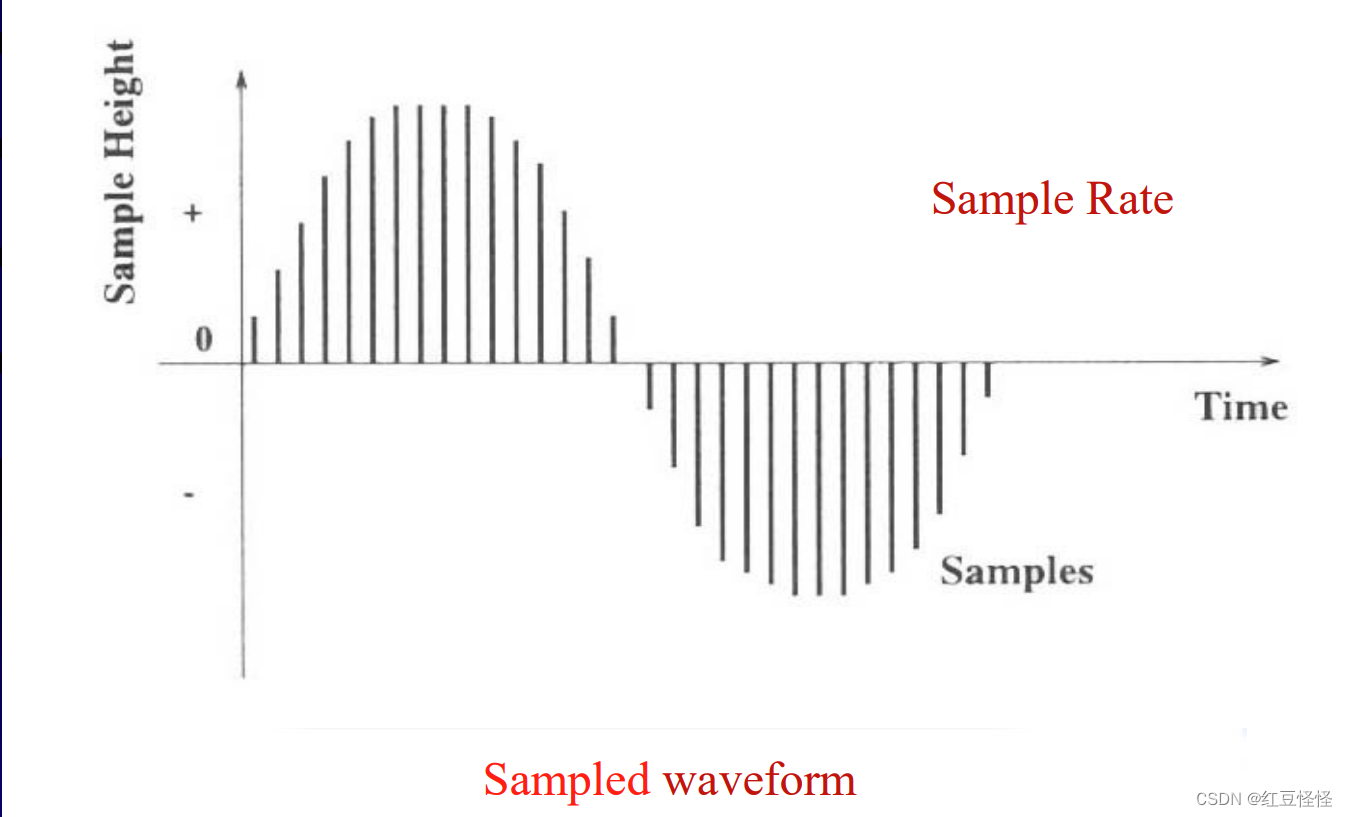
信号在每个维度上都被数字化:时间和幅度
• 采样:频率响应(多久一次?)
– 将连续时间转换为离散时域
– 音频典型采样率:8KHZ ~ 48KHz
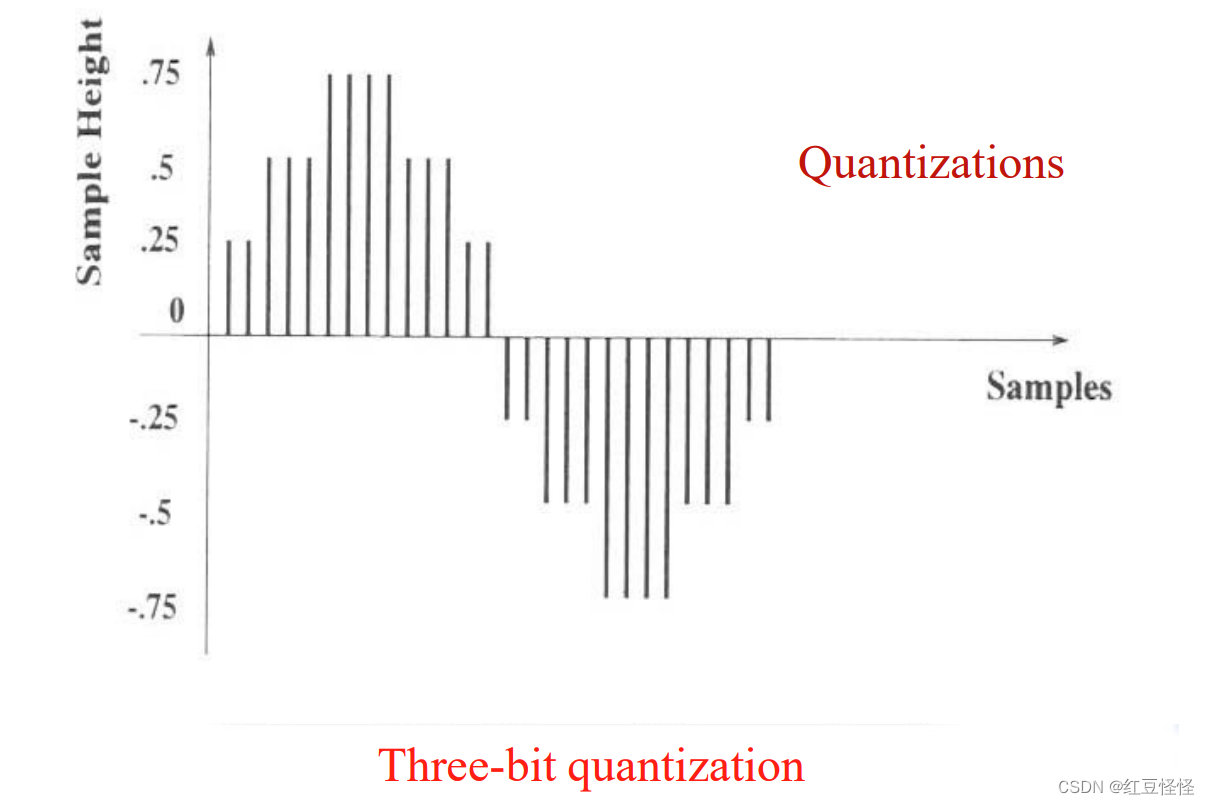
• 量化:幅度范围(多强?)
– 将连续样本值转换为离散值

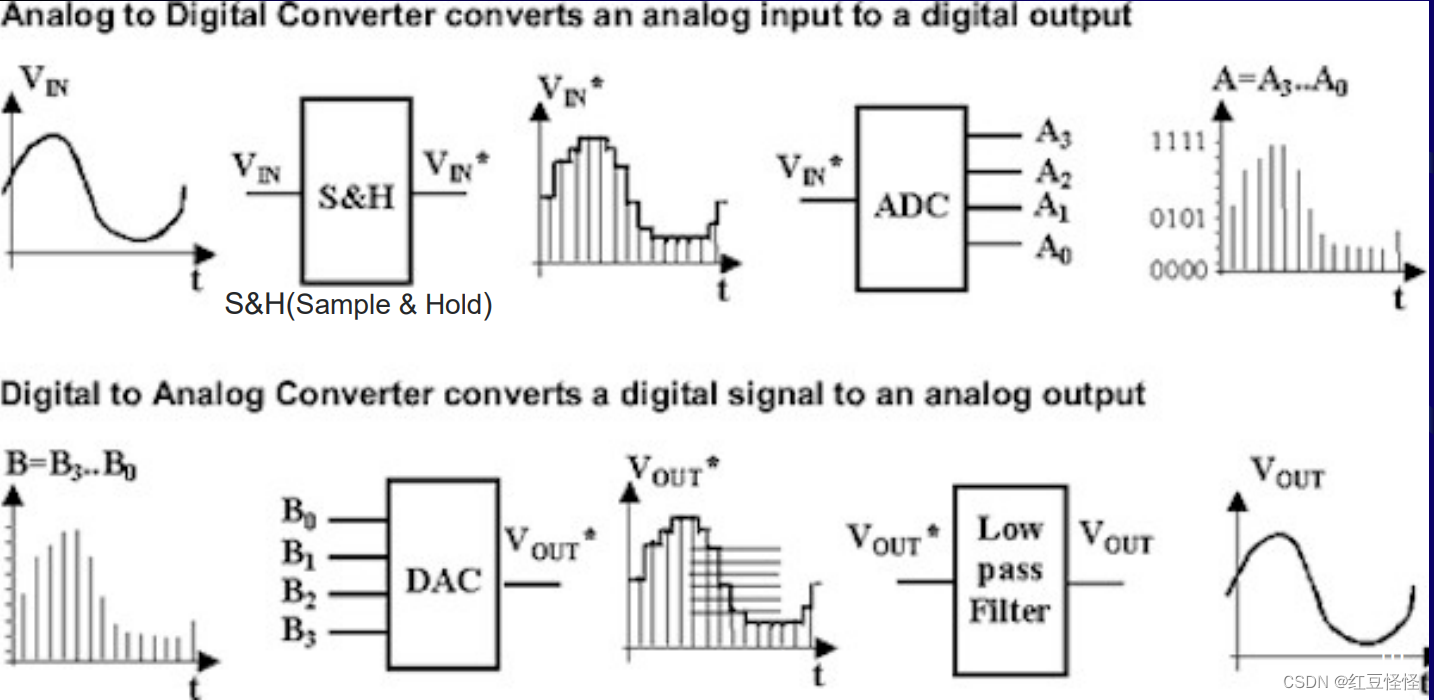
Digital 数字电子的 Analog 现实中自然发生的,连续的
Digital
⇔
\Leftrightarrow
⇔ Analog Converters
- A/D (转换 audio signal to digital signal)
- D/A (转换 digital signal to audio signal)
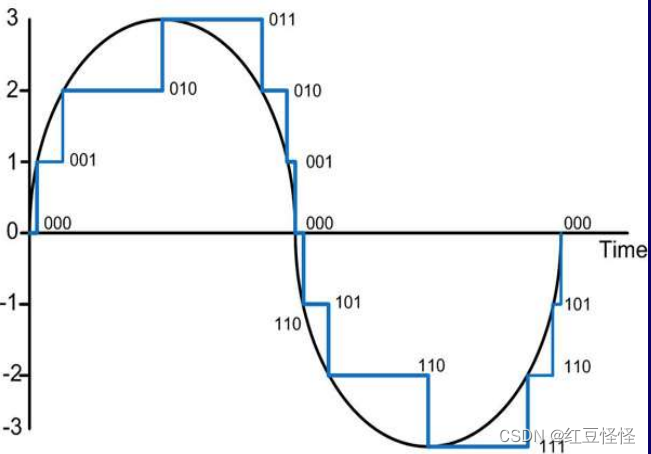
• 抽样
– 将连续时间转换为离散时域的过程
– 关键参数:采样率(通常在整个过程中是固定的)
– 输出:例如,在时间 t1 时幅度为 3.756
• 量化
– 将真实样本值转换为离散值的过程
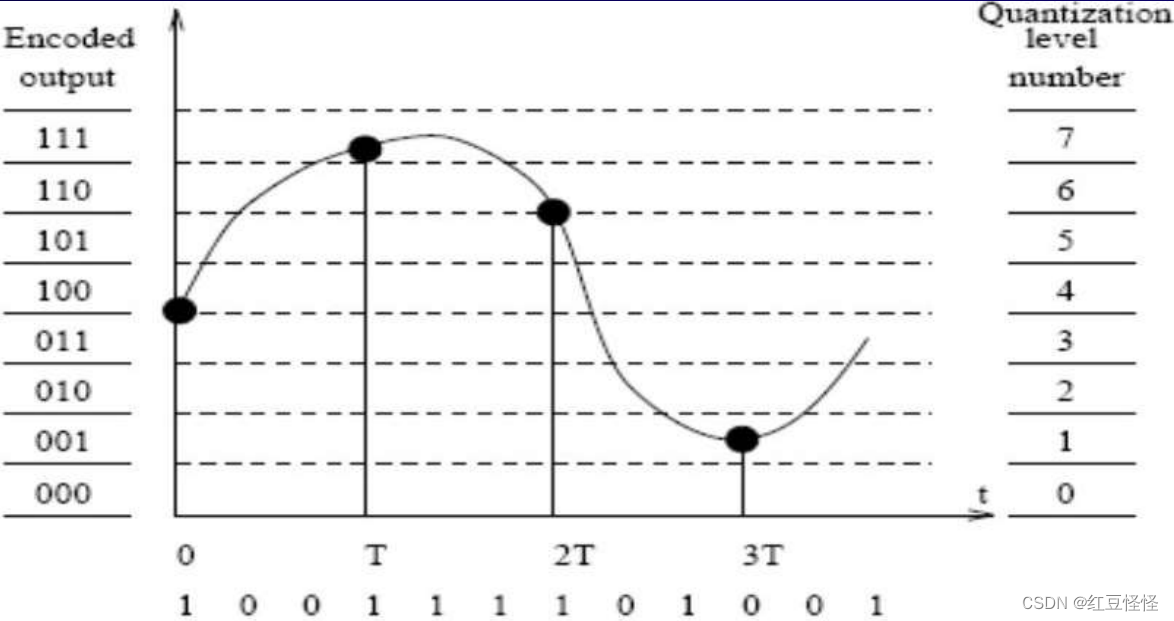
– 关键参数:量化间隔的大小或使用多少位? 例如,8 位将垂直轴分为 256 个级别。
– 输出:例如,在时间 t1 时幅度为 4
• 编码
– 以数字方式表示量化值的过程
– 输出:例如,幅度为
(
100
)
2
(100)_2
(100)2
抽样频率
奈奎斯特采样定理(Nyquist sampling theorem)
– 对于无损数字化,采样率:2
×
\times
× 最大频率响应
– 44,100 Hz 的采样率只能表示高达 22,050 Hz 的频率,该边界更接近人类听觉的边界(20 Hz - 20,000 Hz)。

取决于要转换的信号的最大频率
f
m
f_m
fm
• 根据奈奎斯特定理,采样率至少应为
f
m
f_m
fm的两倍,即
2
f
m
2f_m
2fm Hz(临界采样)
• 这就是为什么我们的语音采样频率为8kHz(语音频率:300Hz-3400Hz) CD 音频为 44.1kHz(人类听觉频率高达 22,050Hz)
• 如果采样率低于2fm Hz,将会出现混叠效应(aliasing effect)
量化值的确定
量化(样本的值是离散的,就像离散时间一样)
– 每个样本的位数 - 电话为 8 位 – 更高的量化意味着更准确的波形
– 较低意味着波形不太清晰 – 量化
×
\times
×采样率 = 每秒所需的位数(数据速率)。 对于电话 8 × 8,000 = 64kb/s
• 音频格式
– 语音质量:8 位
×
\times
× 8 kHz
– CD 质量:44.1 kHz x 16 位(PCM:Pulse Code Modulation 脉冲编码调制)
| 应用 | 样本速度 | 每个样本位数 | 单声道/多声道 | 数据速率(未压缩) |
|---|---|---|---|---|
| 数字电话 | 8kHz | 8 | Mono | 8kbytes/s |
| AM 收音机 | 11.025kHz | 8 | Mono | 11kbytes/s |
| FM 收音机 | 22.050kHz | 16 | Stereo | 88.2kbytes/s |
| CD 音频 | 44.1kHz | 16 | Stereo | 176.4kBytes/s |
| DAT | 48kHZ | 16 | Stereo | 192.0kBytes/s |
DAT: Digital Audio Tape (数字音频磁带)
AM: Amplitude Modulation (调幅)
FM: Frequency Modulation(调频)
CD: Compact Disc(激光唱片)
数字音频的表示(representation)
动作刺激空气分子,空气分子开始以不断扩大的振动波振动。
• 振动的空气分子以高度重复的模式移动,称为波形。
• 耳膜根据我们感知到的声音模式而振动。
• 模式图是连续或模拟波形。
模拟波形具有两个特征:
- 幅度:声音的强度或音量,对应于从基线到信号顶部或底部的垂直距离。
- 频率:由周期决定,周期是波形中任意点与其下一个出现点之间的距离。 频率是每秒的周期数,以赫兹 (Hz) 为单位进行测量。人类听觉的平均范围是从 20Hz 到 20,000Hz
数字音频是通过对声源生成的连续信号进行采样而产生的。
• 模数转换器(ADC) 获取代表声源的电信号并产生数字数据流。
• 数字信号必须先由数模转换器(DAC) 转换回模拟信号,然后才能通过扬声器听到。
采样频率
– 定期采集波形样本,以创建模式(pattern)的数字表示(digital representation)。 – 每秒采样的次数越多(采样频率越高),数字表示就越准确。
– 标准采样频率
对于声音捕获程序:11.025kHz、22.05kHz、44.1kHz – 通常,您应该选择至少是要数字化的声音频率两倍的采样频率,以便捕获声音中的全部音调。
| 11.025kHz | 22.05 kHz | 44.1kHz | |
|---|---|---|---|
| 8 bits | Lowest | Good | Very Good |
| 16 bits | Acceptable | Very Good | Highest |
音频文件大小(5分钟单声道音乐的样本文件大小)
| 11.025kHz | 22.05 kHz | 44.1kHz | |
|---|---|---|---|
| 8 bits | 3.3Mb | 6.615Mb | 13.2 Mb |
| 16 bits | 6.615Mb | 13.2Mb | 26.46Mb |
样本大小和量化
– 样本大小或每个样本的位数决定文件中存储了多少有关声音幅度的信息。
– 典型样本大小为每个样本 8 或 16 位。
– 量化误差是实际幅度与数字近似值之间的差异。 当数字表示重新转换为模拟时,大的量化误差将引入失真。
– 增加样本量将最大限度地减少量化误差。
编码
– PCM(脉冲编码调制):描述如何从一系列脉冲形成数字信号。 PCM 只是未压缩样本的序列,可用作其他编码方法的参考格式。
通道数(轨道)
– 单声道音频信号使用一个通道,立体声使用两个通道。
– 专业音频设备最多可提供32个通道。
• 交错
– 多通道音频值可以通过交错通道样本进行编码,从而更容易实现通道同步并简化存储。
– 如果未使用所有通道,则交错可能会浪费空间。

媒体类型 音乐(了解)
表示
- 操作性与象征性
- Musical Instrument Digital Interface, MIDI(乐器数字界面)
- Standard Music Description Language, SMDL(标准音乐描述)
不同的操作
- 回放与合成
- 时机
- 编辑与创作

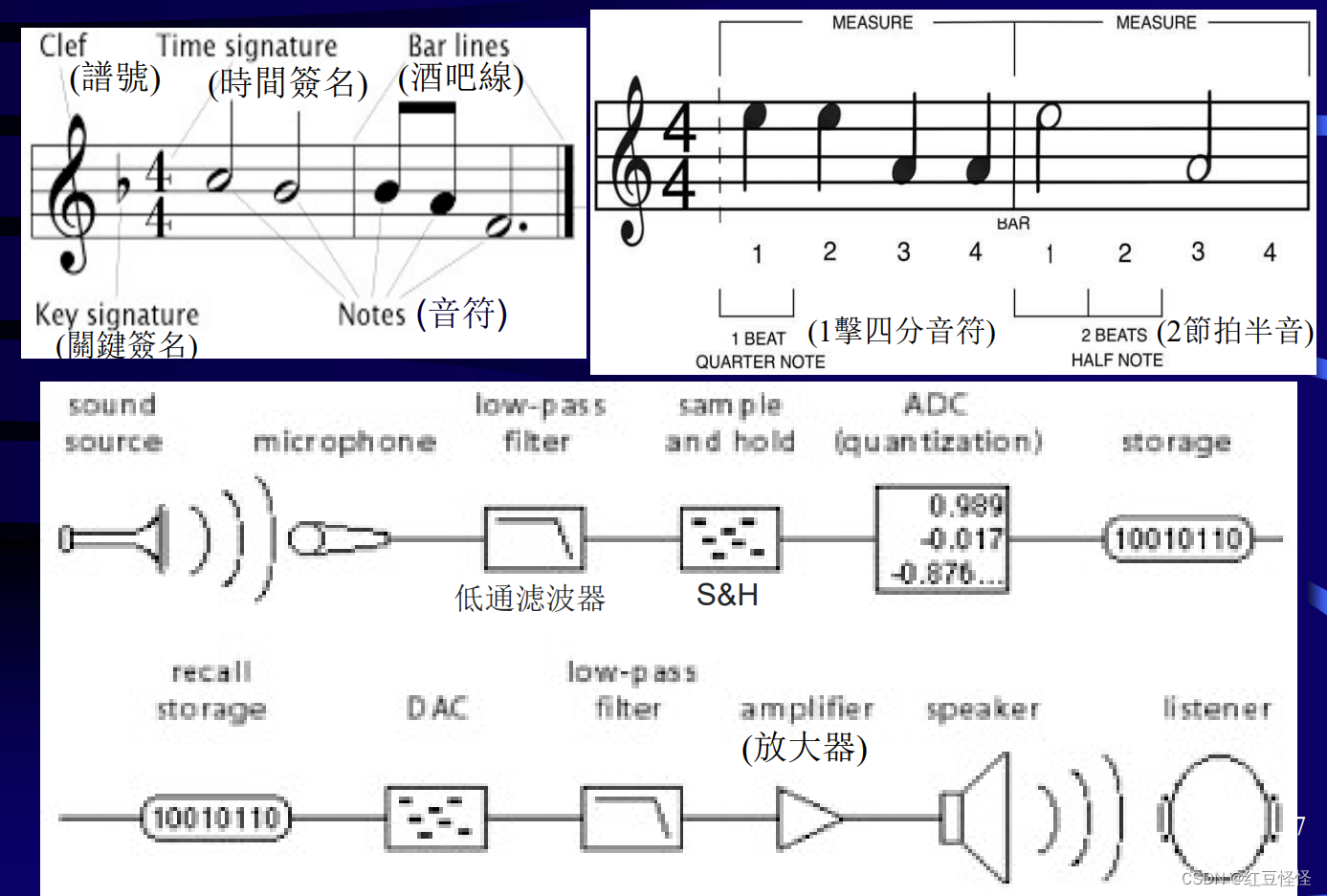
音节(note)
定义:
乐谱中用来表示声音的相对持续时间和音高的符号
音节命名约定
Do-Re-Mi-Fa-Sol-La-Si
拉丁字母A-B-C-D-E-F-G的前7个字母

音高(pitch)
定义
- 声音的听觉属性
- 根据该属性,声音可以按从低到高的顺序排列。
人类将基频比例为2:1(一个倍频程)的两个信号视为高度相似(有时称为“倍频程等效”)。

和弦(chord)
定义
同时演奏的三个或更多音符的任何和声组
和弦 – 时频分析

• 中音C (262 HZ)、E (330 HZ) 和G (392 HZ) 构成C 大调三和弦,这是西方音乐中常见的和声单元。
A C 大调
旋律(Melody)
定义
- 以富有音乐表现力或独特的顺序排列的一系列单个音符
- 它创造了我们认为是歌曲的形状
音量(volume)
• 音乐家用来识别声音的响度
• 科学家称之为振幅,以分贝(decibel) 为单位测量
音乐与情感
- 音乐与情感的关系
- 音乐传达情感,音乐唤起人类的情感。
音乐 表示
• 音乐表示是一种指定制作一首音乐所需信息的方法。
• 操作表示指定确切的结构、时间和要产生的声音。
• 符号表示描述了音乐的形式并允许解释
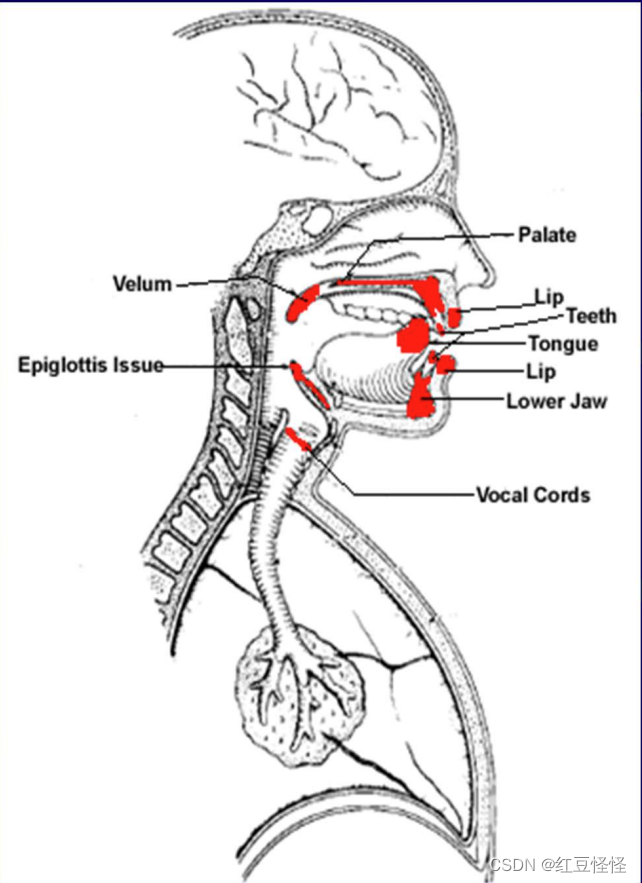
声音是由通过声道(vocal tracts)的声门脉冲(glottal pulses)产生的,包括会厌(epiglottis)、下颌(lower jaw)、舌头(tongue)、软腭(velum)、上颚(palate)、牙齿(teeth)和嘴唇(lips)
• 人类可以非常有效地调整自己以适应不同的说话者及其言语习惯(语音识别)
• 人耳在600 Hz 至6,000 Hz 范围内最敏感。
• 语音信号的属性 – 有声语音信号在某些时间间隔内表现出几乎周期性的行为。 – 音频信号的频谱显示出特征最大值,大多是3-5个频段。
语音(speech)
语音生成
– 重要要求:实时信号生成
• 语音采集
– 语音由麦克风等设备捕获。
– 该设备将用户的声波转换为模拟信号。
– 模拟信号通过模数 (A/D) 转换器转换为数字信号
语音分析
– 识别说话者的身份和验证
– 分析说过的话以及某个陈述是如何说的
两个说话者说出相同元音“A”时的模型差异:
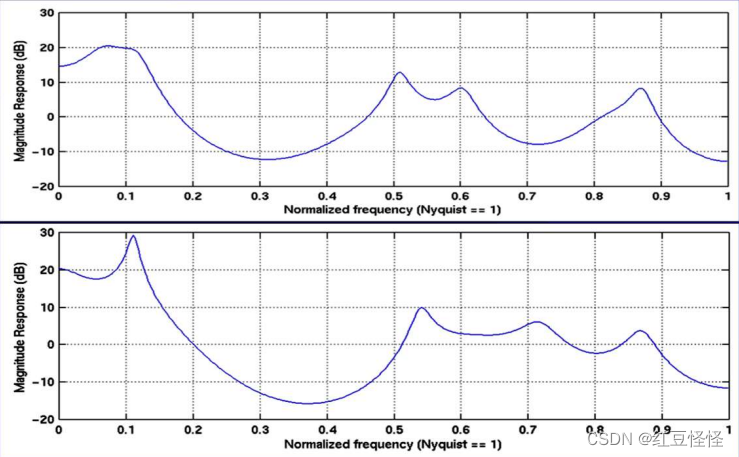
不同的元音可能有不同的波形。

语音识别
- 说话人相关系统:它是为单个说话人操作而开发的。 这些系统通常更容易开发、购买更便宜并且更准确。 与说话人相关的软件通过学习单个人声音的独特特征来工作,其方式类似于语音识别
- 与说话者无关的系统:它是为任何特定类型的说话者(例如美式英语)操作而开发的。 与说话者无关的软件旨在识别任何人的声音,因此不需要任何培训。
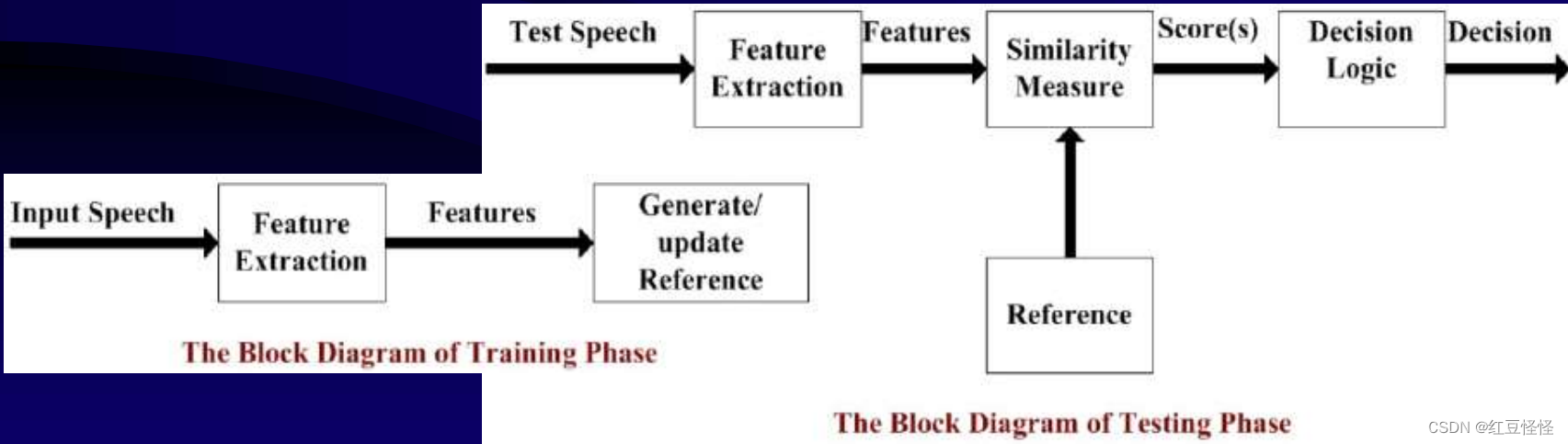
语音识别系统
– “通过属性提取减少数据”
• 语音预处理
• 特征提取
• 匹配与决策
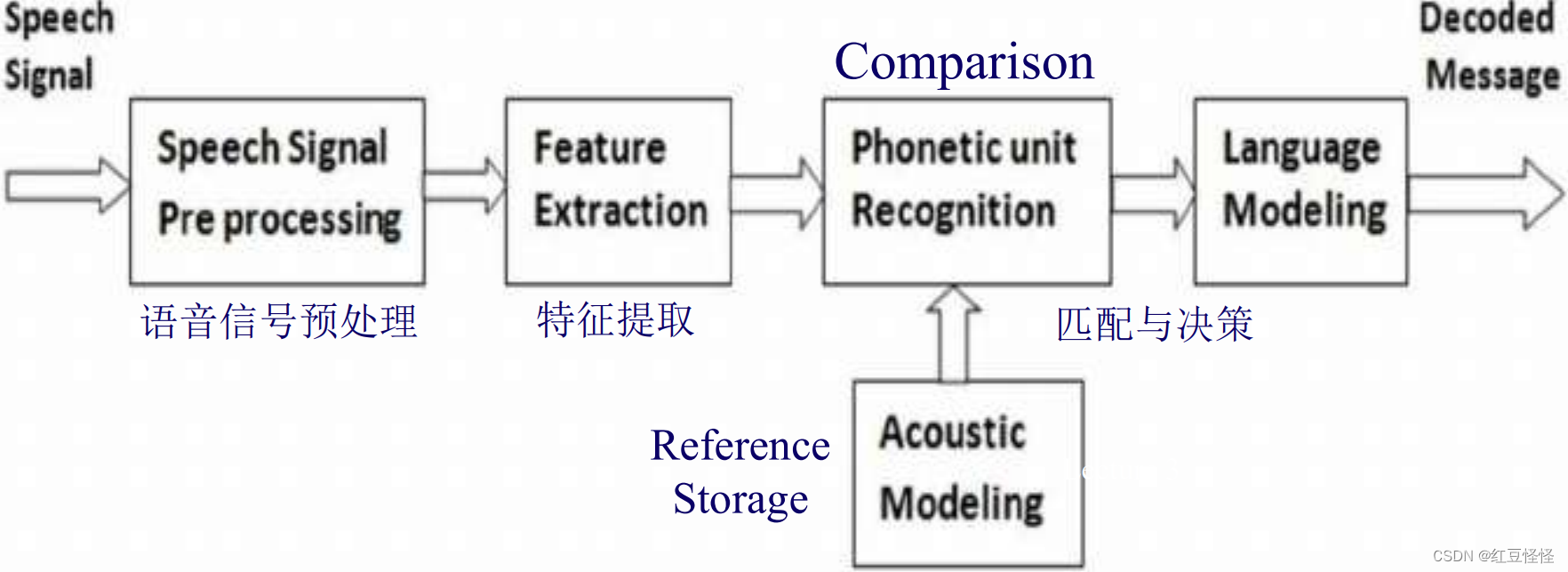
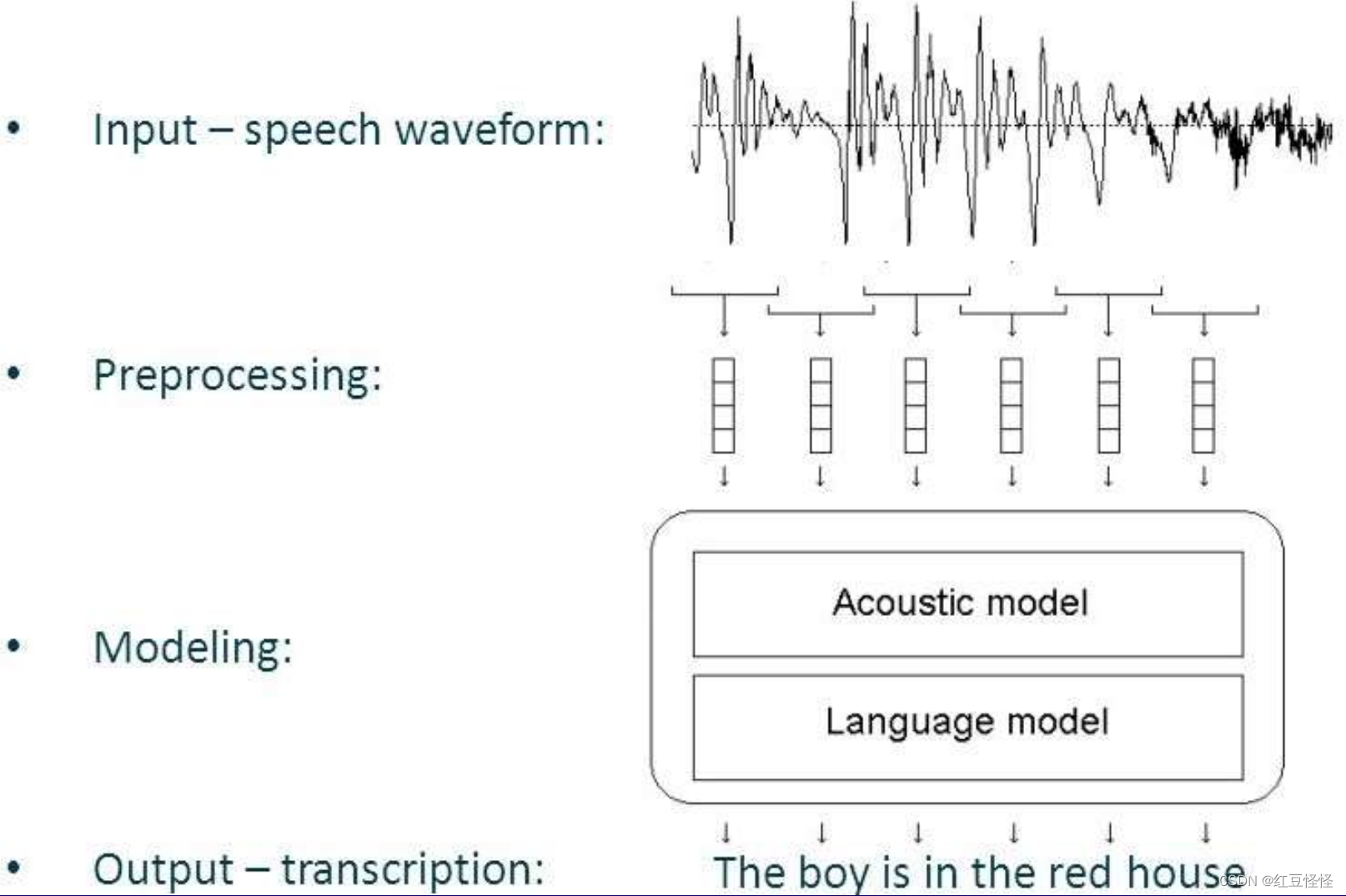
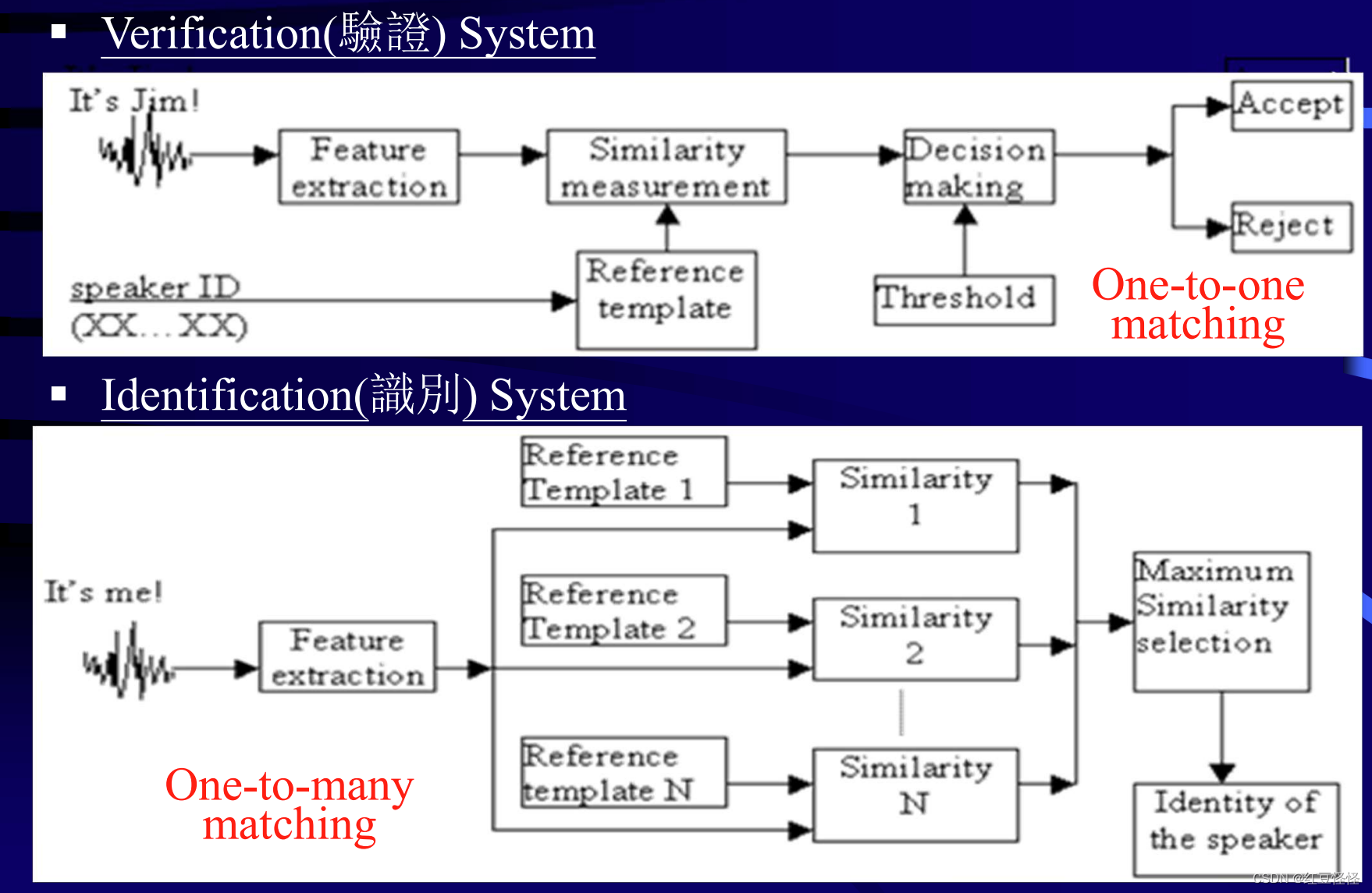
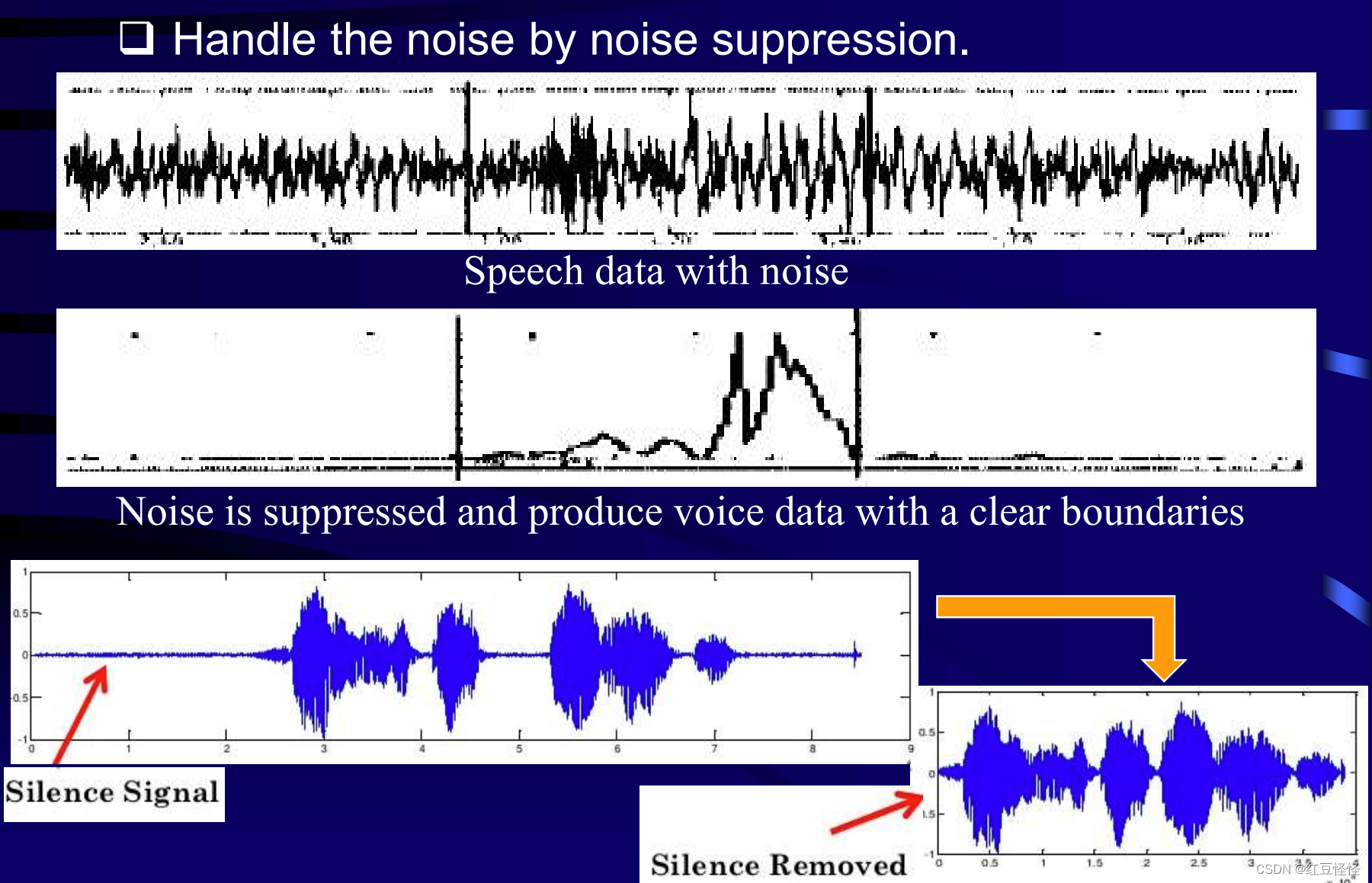
语音特征提取
特征提取是变量的估计,
称为特征向量。
下面对一些功能进行简单总结,在实际系统中可能会结合使用。
- 禁频分析(frequency ban analysis)
- 从频谱图识别
- 协同发音的使用
- 共振峰频率
- 螺距轮廓
- 源自线性预测的特征
- 特点一:禁频
滤波器频带系统用于频带分析。 对输出进行采样并产生频谱信息以供比较。
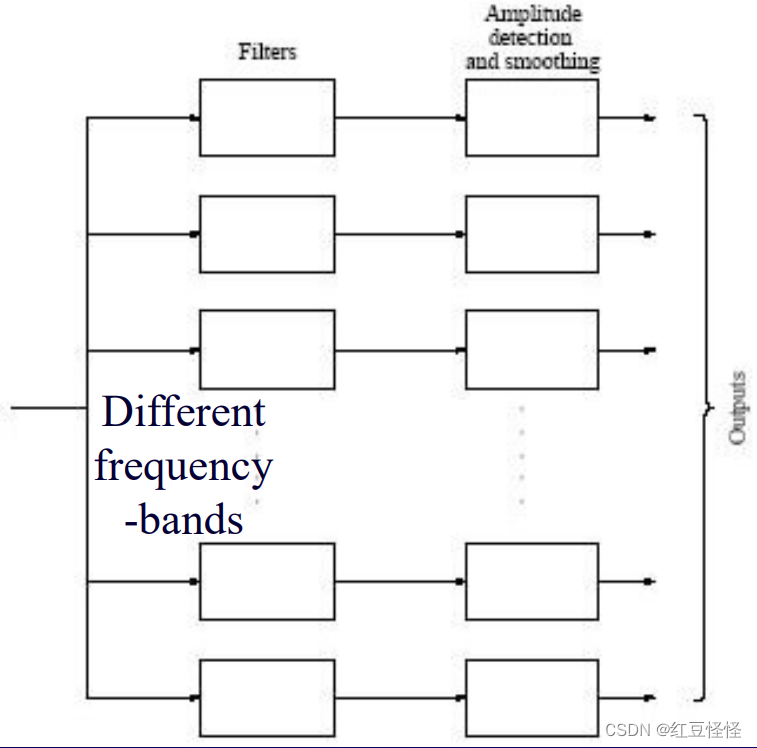
- 特征2:频谱图
频谱(spectrogram) 是随时间变化的音频谱表示(形成图像),显示信号的频谱密度如何随时间变化。
声谱图
- 语音信号的能量分布
- 声谱图的视觉比较以识别说话者
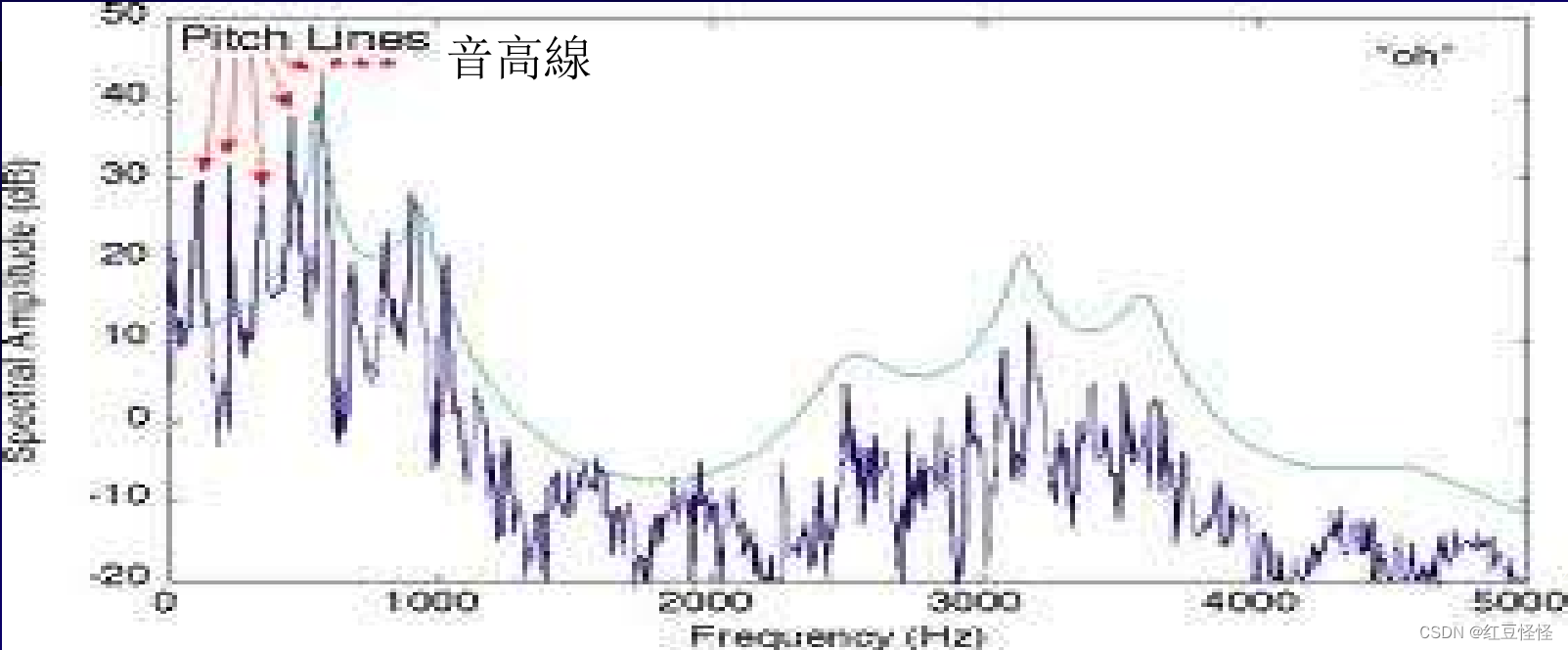
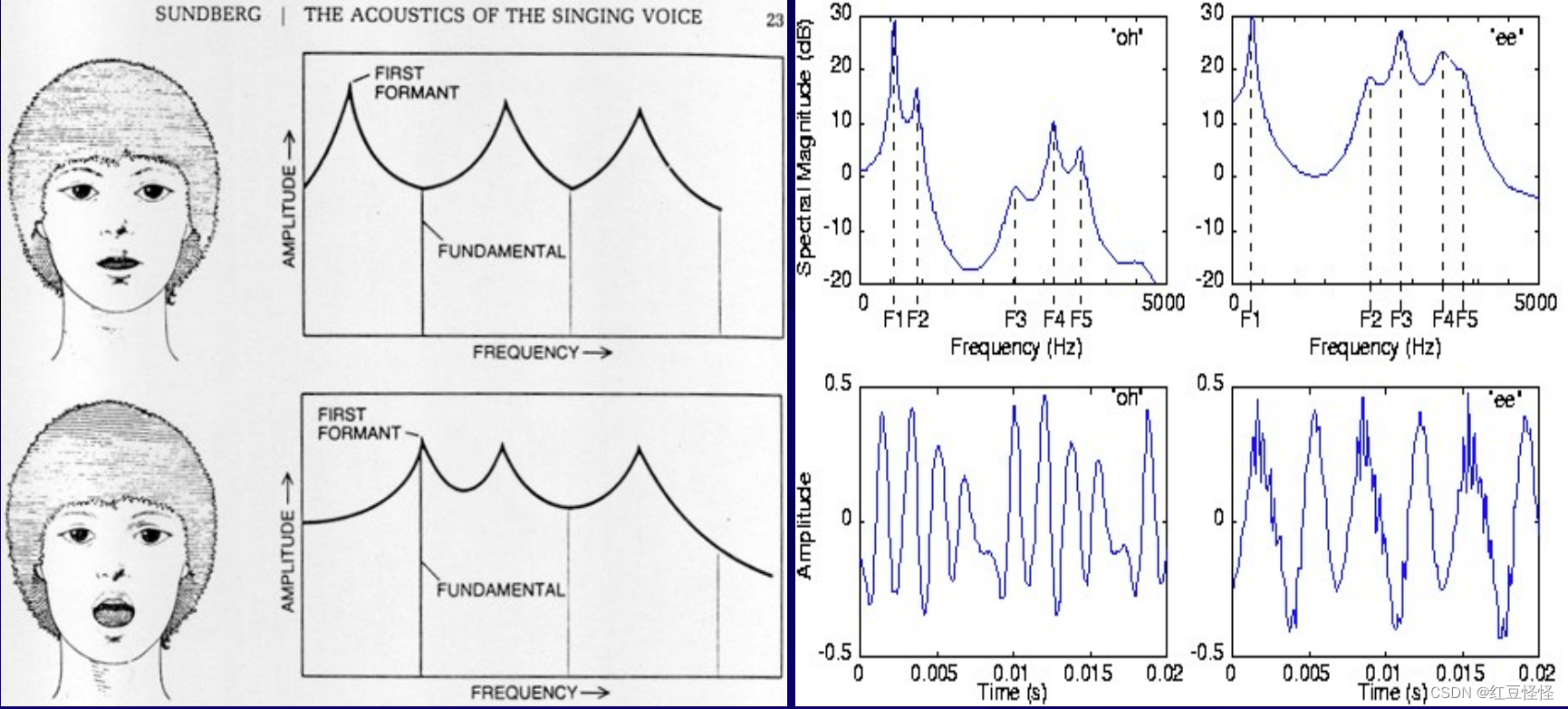
- 特征 3:共振峰频率
频谱中的共振被称为共振峰(焦点峰)。 不同的发音器官产生不同的共振区域。 共振的位置可以确定说话者之间的差异。
- 特征4:协同发音
- 在从一种声音过渡到另一种声音的过程中,发音器官准备发出新的声音,同时旧声音的一些痕迹仍会保留。 这就是所谓的协同发音。
- 通过分析声谱仪上发生协同发音的点来识别说话人。
- 特征 5:音高轮廓
说话期间音调(基频)的变化给出了可用作说话人识别特征的“轮廓”

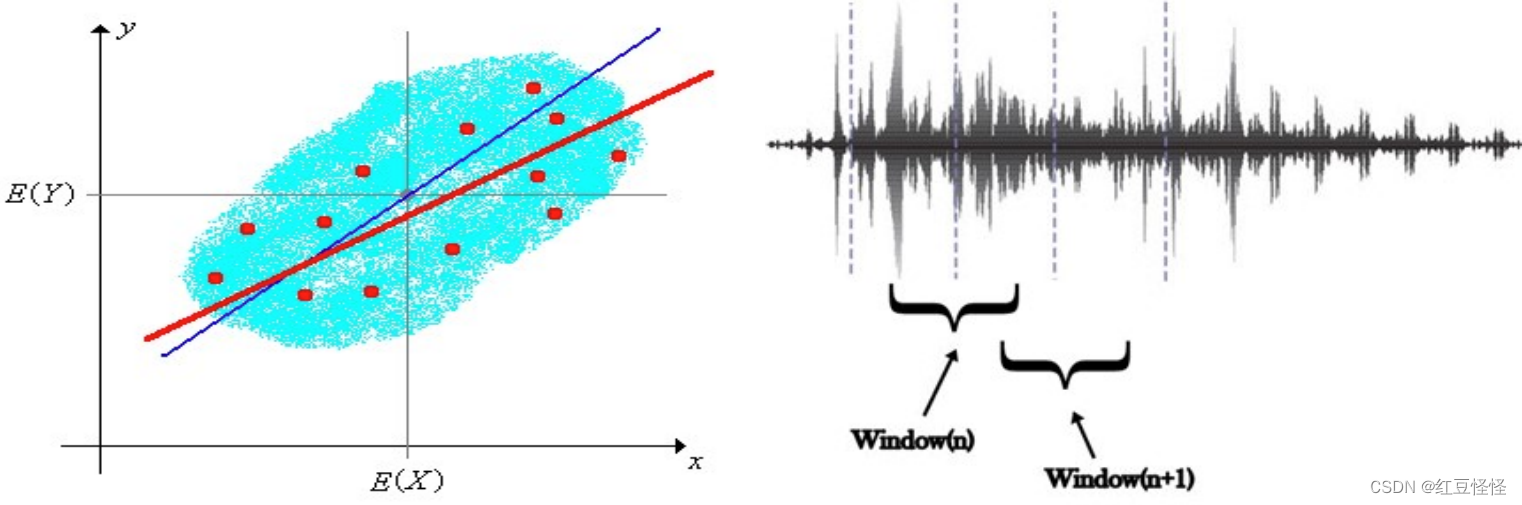
- 线性预测的特征 6
线性预测由两个方程得出:

这两个方程生成每个语音的线性预测系数,可用于确定两个或多个语音之间的差异。
- 表现评估
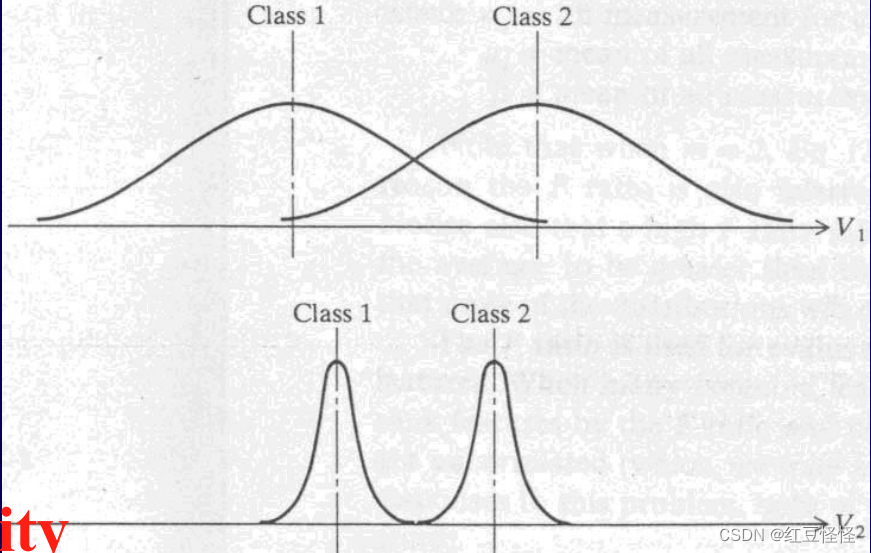
选择特征后,我们需要看看它们如何区分不同的类别
– 测量功能的性能
性能评估:
类内变异性
– 一个人的声音可能不同
方法:更多地训练个人声音,记住这个人的主要特征
类间相似度
– 两个人可能有相似的音调、音调或频率
方法:去除所有与他人匹配的特征,留下的特征就是一个人的独特特征
概括
音频的基本特性
– 音频A/D转换
– 采样率以及如何确定
– 数字音频 – 表示
• 音乐:表现和操作
• 演讲
– 语音生成和分析
– 语音识别:特征提取
– 类内变异性和类间相似性















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











