







 文章介绍了一种新的深度多视图子空间聚类方法TRUST,它通过三粒度对比学习捕捉跨视图一致性,并考虑实例表示、特定亲和关系和共识亲和关系。实验结果显示,这种方法在多视图聚类任务中表现出色。
文章介绍了一种新的深度多视图子空间聚类方法TRUST,它通过三粒度对比学习捕捉跨视图一致性,并考虑实例表示、特定亲和关系和共识亲和关系。实验结果显示,这种方法在多视图聚类任务中表现出色。
Triple-Granularity Contrastive Learning for Deep Multi-View Subspace Clustering
原文链接
以往的多视图一致性研究只关注实例表示层次或亲和关系层次的跨视图一致性信息,无法对多层次的多视图一致性进行联合研究。
为此,提出了一种深度多视图子空间聚类(TRUST)的三粒度对比学习框架,该框架受益于从实例、特定亲和关系和共识亲和关系三个层次全面发现有价值的信息。
具体来说,使用多个特定于视图的自编码器将原始多视图数据投影到噪声鲁棒的实例表示中,并将其分别作为视图共享MLP层和特定于视图的自表示层的输入,以获得相应的高级实例表示和特定于视图的亲和矩阵。然后,对高级实例表示和特定于视图的亲和矩阵进行实例和特定亲和关系的对比约束,使它们专注于挖掘跨不同视图的一致信息。进一步,将多个特定于视图的关联矩阵融合为一个一致性关联矩阵,并构造一个编码高级实例表示的关联关系的𝑘-nearest邻居图,在一致性关联关系对比正则化约束下,将结构关系嵌入到一致性关联矩阵中。最后,利用一致亲和矩阵进行谱聚类,生成最终聚类结果。
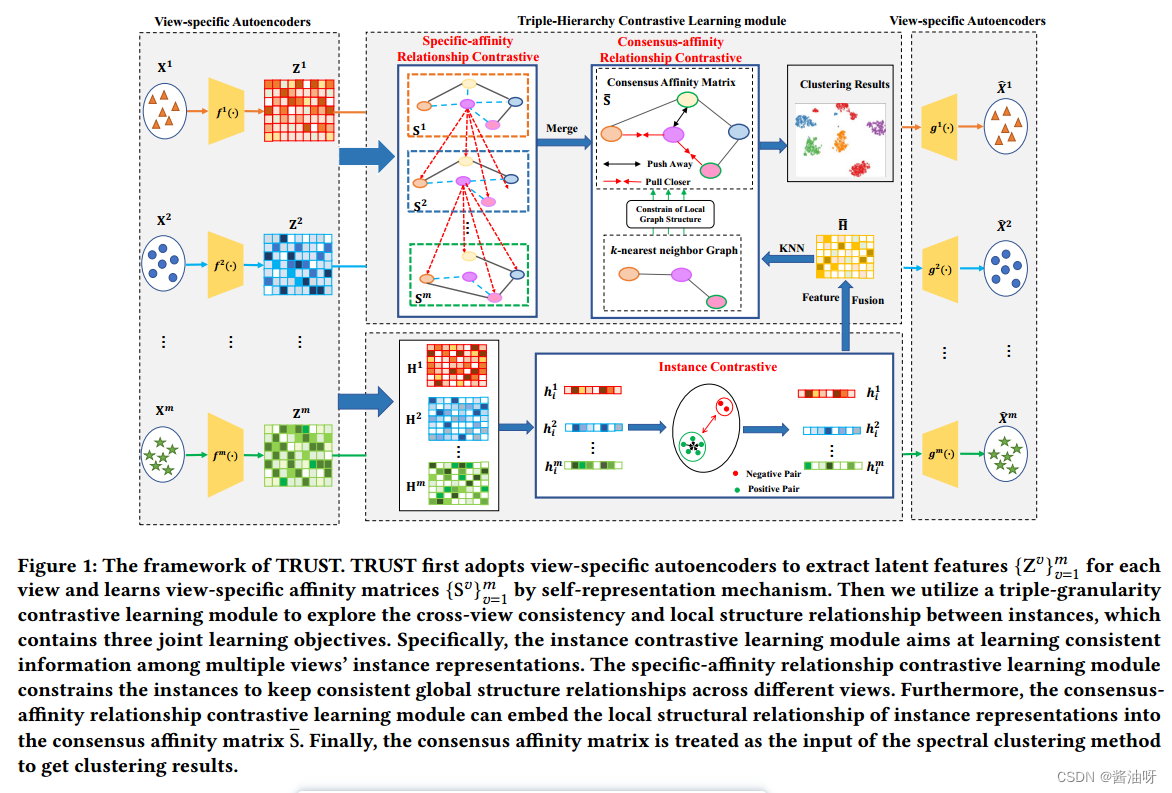
Fig1:TRUST的框架。TRUST首先采用特定于视图的自编码器提取每个视图的潜在特征{Z𝑣}𝑚𝑣=1,并通过自表示机制学习特定于视图的亲和矩阵{S𝑣}𝑚𝑣=1。然后,利用三粒度对比学习模块来探索实例之间的跨视图一致性和局部结构关系,其中包含三个共同的学习目标。具体来说,实例对比学习模块旨在学习多个视图的实例表示之间的一致信息。特定亲和关系对比学习模块约束实例在不同视图之间保持一致的全局结构关系。此外,共识亲和关系对比学习模块可以将实例表示的局部结构关系嵌入到共识亲和矩阵s中。最后,将共识亲和矩阵作为谱聚类方法的输入,得到聚类结果。
METHODOLOGY
深度多视图子空间聚类
该方法由三个部分组成,包括多个特定视图的自编码器网络、多个特定视图的自表示层和光谱聚类。
特定于视图的自动编码器网络
数据重建损失:
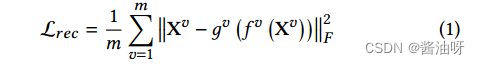
自表示层
从自编码器网络中获得𝑚特定视图的潜在表示后,引入自表示层来提取每个视图下样本的全局结构亲和关系。
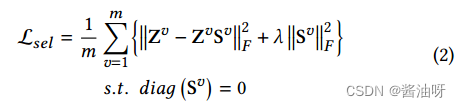
S𝑣∈R𝑛×𝑛表示𝑣-th视图亲和矩阵,Z𝑣∈R𝑙𝑣×𝑛表示潜在表示矩阵,并且为权衡参数。∥Z𝑣−Z𝑣S𝑣∥2 和∥S𝑣∥2 分别表示亲和矩阵的重构损失和结构惩罚
谱聚类
根据自表示层得到特定于视图的关联矩阵S𝑣,并通过以下式子构造了一致关联矩阵:
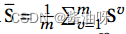
可以对一致亲和矩阵S进行谱聚类,得到最终聚类结果。
三粒度对比模块
现有的深度多视图子空间聚类方法仍然存在一些严重的缺陷需要解决:
(1)现有的DMSVC方法通常使用特定于视图的深度神经网络来学习每个视图的实例表示和相应的亲和矩阵。然而,它们不能共同探索实例表示和特定关联矩阵的一致信息,导致错误的特定于视图的信息影响了公共语义的学习。
(2)以往的方法直接对一致亲和矩阵进行谱聚类,忽略了进一步挖掘一致亲和矩阵的局部结构信息。
为了缓解上述问题,引入了三粒度对比学习模块,利用实例、特定亲和关系和共识-亲和关系对比正则化项共同探索跨视图一致性信息,并对共识亲和矩阵的局部结构信息进行建模,进一步提高了最终聚类的性能。
实例对比学习
实例级对比学习,根据特定于视图的潜在表示{z𝑣}𝑚𝑣=1来学习判别性实例表示{h𝑣}𝑚𝑣=1。这种学习范式鼓励不同视图中的每个实例表示{h𝑣}𝑚𝑣=1是一致的,同时****要求不同实例的表示是不同的。因此,正对包含来自不同视图的同一实例的表示,而负对包含不同实例的表示。
为此,首先采用一个视图共享的项目头(·),它将潜在的特定于视图的表示Z𝑣映射到高级表示H𝑣∈R𝑛×𝑘,即H𝑣= (Z𝑣)。随后,将实例对比损失应用于该高级表示空间。
具体地说,给定一个视点数据集包括𝑛实例𝑚视图,每个高层表示h𝑣𝑖形式(𝑛𝑚−1)表示对,{(h𝑣𝑖,h𝑞𝑖),𝑣≠𝑞}作为𝑚−1正对剩下的𝑚(𝑛−1)表示对构成负对。
实例级对比学习的目的是通过使正对更接近而使负对更远来捕获跨视图一致性,其表述为:
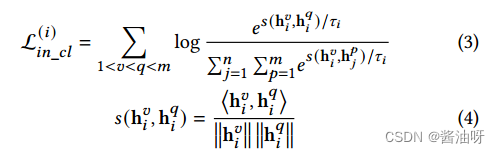
其中𝑠(·,·)是由连续距离测量的h𝑣和h𝑞之间的相似性,⟨·,·⟩是点积算子,而是softmax温度的可调超参数。
所有样本的整个实例级对比损失可以通过平均来表示:
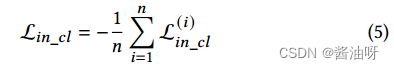
特定亲和关系对比学习
通过多个特定于视图的自表示层,学习相应的亲和矩阵。由于每个特定于视图的关联矩阵同时编码来自多个视图的一致和互补信息,因此不可避免地会接收到不正确的信息。
提出了特定亲和关系对比模块,旨在确保跨视图结构的一致性。
具体来说,对于每一个相似性表示s𝑣𝑖,构建的正对{(s𝑣𝑖,s𝑞𝑖),𝑣≠𝑞},负对{(s𝑣𝑖,s𝑝𝑗),𝑖≠𝑗},s𝑣𝑖、sq𝑖在s𝑣𝑖和s𝑞𝑖亲和矩阵s𝑣和s𝑞的𝑖-th列,s𝑝𝑗为其他实例的相似度表示。
则样本的特定亲和关系对比损失表述为:
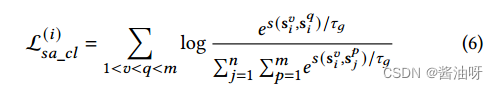
通过遍历所有样本,计算整个比亲和关系的对比损失:
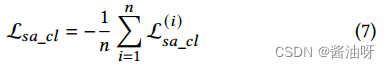
共识-亲和关系对比学习
在上述两个对比模块中侧重于从多个视图学习一致的信息,而忽略了实例之间的局部结构关系。
在本节中,引入了一个监督一致性关联对比模块来对局部结构信息进行建模,从而使一致性关联矩阵更适合聚类。
与以往基于对比学习的多视图聚类方法(将同一实例的视图视为正对,将不同实例的视图视为负对)不同,提出的共识-亲和关系对比模块将每个实例及其𝑘-nearest邻居视为正对,将所有其他实例视为负对。采用共识-亲和关系对比模块,将近邻之间的距离最小化,非近邻之间的距离最大化,增加了类之间的距离,减小了类内的距离。
具体来说,采用𝑘-nearest邻居算法构造邻居指标矩阵M∈{0,1}𝑛×𝑛。
M i 表示每个高级表示的最近邻居
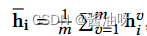
其中M𝑖𝑗=1表示𝑗-th样本是𝑖-th样本的最上层𝑘邻居之一,否则M𝑖𝑗= 0。
由于𝑘-nearest邻居被认为是正对,利用共识内图对比损失来最大化正对之间的相关系数,最小化负对之间的相关系数,可以表示为:
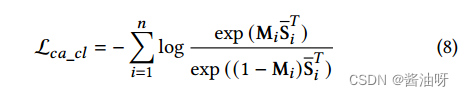
总体损失函数与聚类
总体损失函数如下:
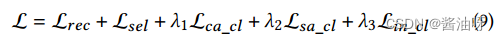
最后,得到一个理想的一致亲和矩阵S,并将其传递给谱聚类算法,得到最终的聚类结果。
为了学习多视图一致性信息,全面探索样本的结构关系,本文提出了一种深度多视图子空间聚类的三粒度对比学习框架(TRUST),这是将对比学习引入深度多视图子空间聚类的首次尝试。简而言之,本文利用三种不同粒度的对比学习模块来学习一致的实例表示、一致的实例相似表示和一个表示样本局部结构的期望的一致亲和矩阵。实验结果表明,本文提出的信任算法比现有的算法性能更好















 3076
3076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









