




多视图的理解及多视图聚类算法
前言

这里主要讲解的是多视图的相关理解及多视图聚类的算法,其中部分理解的文献来源于下面的文章:
- 文章:Multi-view Clustering: A Survey
- paper link: https://ieeexplore.ieee.org/document/8336846
- publisher: IEEE2018,Big Data Mining and Analytics
- date: May 31, 2018
什么是多视图
 多视图的定义
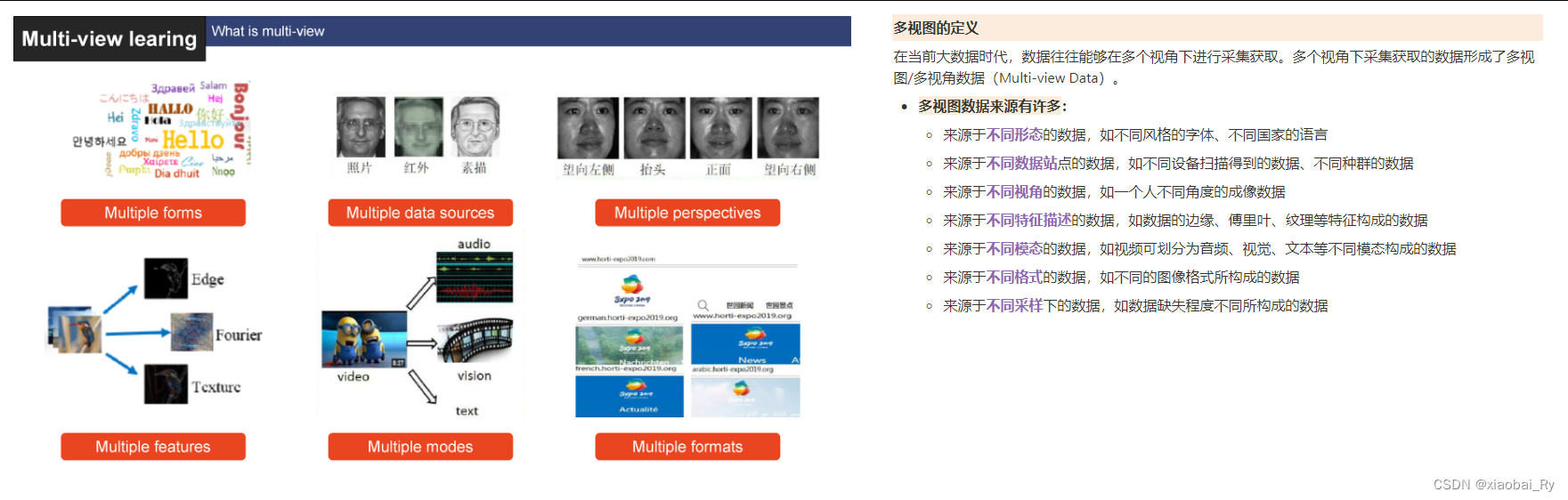
多视图的定义
在当前大数据时代,数据往往能够在多个视角下进行采集获取。多个视角下采集获取的数据形成了多视图/多视角数据(Multi-view Data)。
- 多视图数据来源有许多:
- 来源于不同形态的数据,如不同风格的字体、不同国家的语言
- 来源于不同数据站点的数据,如不同设备扫描得到的数据、不同种群的数据
- 来源于不同视角的数据,如一个人不同角度的成像数据
- 来源于不同特征描述的数据,如数据的边缘、傅里叶、纹理等特征构成的数据
- 来源于不同模态的数据,如视频可划分为音频、视觉、文本等不同模态构成的数据
- 来源于不同格式的数据,如不同的图像格式所构成的数据
- 来源于不同采样下的数据,如数据缺失程度不同所构成的数据
多视图的重要性

-
互补性
互补性原则是指多视图数据的每一个视图都可能包含其他视图所不具备的信息或知识,使用多个视图可以获得更加全面而准确的数据描述。
不同的视图通常包含不同的信息,但是也包含彼此互补的信息。不同视图之间的互补性可带来更多的特征信息,有利于信息的充分利用,使模型能更加准确、全面的描述原始数据。因此,有必要利用这些基于多个视图的相互补充的信息来描述这些数据对象,以便对内部信息进行深入挖掘,提高聚类质量。
-
一致性(共识性)
一致性原则旨在最大化多个视图之间的一致性,如多个视图应具有相同的类别结构。简单来说,就是不同视图中的同一数据点应该具有相同的簇分配信息,即不同视图均为同一对象的描述,在下游任务如分类任务上,不同视图的分类结果即标签应该也是一致的
相关理论:保证不同视图视图之间一致性最大化实际上就等同于最小化每个视图出错的概率
多视图的聚类方法的概览

多视图的聚类算法主要分为以下5种:
- 协调训练方法(Co-training)
- 多核学习方法(Multi-kernel)
- 多视图图形聚类方法(Multi-view graph)
- 多视图子空间聚类方法(Multi-view subspace)
- 多任务多视图聚类方法(Multi-task Multi-view)
算法1:协调训练方法与

-
方法
Co-training实际上就是利用先验知识或互相学习知识来使不同视图之间的一致性达到最大化。
如上图,标准协同训练算法的步骤为:
输入:标记数据集L,未标记数据集U。
输出:分类器f1和f2。
- 用L1训练视图X1上的分类器f1,用L2训练视图X2上的分类器f2;
- 用f1和f2分别对未标记数据U进行分类;
- 把f1对U的分类结果中,前k个最置信的数据(正例p个反例n个)及其分类结果加入L2;把f2对U的分类结果中,前k个最置信的数据及其分类结果加入L1;把这2(p+n)个数据从U中移除;
- 重复上述过程,直到U为空集。
-
种类
协同训练的几种扩展版本,例如协同期望最大化(co-EM)、协同正则化(co-regularization)和协同聚类(co-clustering)。 -
优劣势总结
总之,基于协同训练的聚类算法基于共识性原则,通过视图间彼此交换信息交互式地引导不同视图的聚类结果,使不同视图间的聚类结果相互接近,趋于彼此。但是,对于协同训练方法当视图数量超过三个时,问题就会变得棘手。此外,算法的有效性依赖于视图的充分性、兼容性和条件独立性 3个条件,在一定程度上限制了其在复杂多视图数据上的应用。
算法2:多核学习方法
核函数是实现映射关系内积的一种方法,将低维特征空间映射到高维空间,使得低维特征空间线性不可分的数据在高维空间可能实现线性可分。多视图数据由于每个视图都有其特有的分布信息。多核学习需要对不同的视图构造不同的基核,并通过线性、非线性等方式找出视图间的结构关联,有效融合多视图信息得到一致性核,最终达到提高聚类性能的目的。多核学习存在两个关键问题:一是如何选择合适的核函数;二是如何有效地组合多个核函数。
-
方法
首先预先定义多个内核,以对数据进行映射计算。然后以线性或非线性的核学习方式组合这些内核,并为每个内核都会赋予一个权重,以衡量每个内核的贡献,权重越大表示其贡献越大,得到一个共识内核。最后会将学习到的共识核输入到 k-均值聚类算法中,得到最后的聚类结果。 -
优劣势总结
基于多核的多视图聚类算法通过将样本映射到可再生希尔伯特空间实现了数据的非线性映射,核方法通过利用优化组合算法进一步提高聚类性能,但存在时间复杂度较高,内存消耗较大,可扩展性较差等问题。 -
多核学习的一个例子
如上图中,多核学习在每个视图上采用核主成分分析(KPCA)以降低原始数据的维度,并产生低维的多视图数据。然后,将设计的加权高斯核应用于低维多视图数据。这一步决定了每个视图和聚类中心的权重。经过有限次迭代后,它得到最终的聚类结果。
算法3:多视图图形聚类方法

- 方法
主要分为三个关键步骤:(1)基于单视图分别构造初始图;(2)学习融合全部视图拓扑结构的一致图;(3)将聚类问题转化成图分割问题。
-
种类
(1)基于图学习
(2)基于网络学习
(3)基于谱聚类 -
优劣势
由于图结构具有可解释性强的特点,该类方法在聚类结果的解释方面具有一定优势。然 而,基于图模型的多视图聚类算法的性能大多依赖于图的初始化,而初始图的质量通常难以得到保障。 -
一个例子
对于上图的数据,首先分别提取每张图像的数据特征(如LBP、HOG、GIST等),在不同特征空间下,分别计算图像之间的相关性,然后在每个特征空间下,将图像特征视为数据节点,将图像相关性作为边来构建对应的单视图Graph;基于此,学习融合全部视图拓扑结构的一致图,从而将聚类问题转为图切割问题。
算法4:多视图子空间聚类方法

-
概述
多视图子空间聚类是对所有视图数据,从多个子空间或潜在空间学习一种新的、统一的表示,最后对该统一表示执行聚类。多视图子空间学习的核心思想在于尽可能保留每个视图特有分布信息的情况下,寻找多个视图共享的表示空间。多视图子空间聚类通过以下两种方式获得统一的特征表示:①直接从多个子空间中获取单一表示;②首先学习一个潜在空间,然后到达该统一表示。最后,这种统一表示被输入到现成的聚类模型中,以产生聚类结果。
-
种类
经典的子空间学习方法有典型相关分析 、矩阵分解 、自表示 、主题模型和字典学习等。-
矩阵分解法: 尽管基于矩阵分解方法可以挖掘到多视图数据中隐含的聚类结构,具有一定的稳定性和鲁棒性,但是产生的低维潜在表示存在难以解释的问题 ,这也限制了该类方法在实际中的应用。
-
自表示方法: 基于自表示的子空间学习方法能够在实现数据降维的同时保留数据的流形结构,但是该类方法往往涉及较多参数、计算复杂度较高,难以适应计算资源受限的环境。
-
-
基于矩阵分解的多视图学习理解

对基于矩阵分解的多视图学习的约束(损失函数)的理解,基于非负矩阵分解和成对协同正则的多视图聚类方法的目的在于通过 NMF 得到每个视图对应的非负系数矩阵,并分别利用视图间的相似性约束项和视图内的相似性约束项,使得所有视图对应的系数矩阵都尽可能的相似,同时保持特征空间中的内在几何结构信息,再对得到的最优系数矩阵进行 K-means 聚类,得到多视图数据的聚类结果。(1)多视图数据对应的非负矩阵分解重构误差项为:

(2)视图间的相似性约束项为:

(3)视图内的相似性约束项(保持每个视图所在数据空间中的局部几何结构信息)


算法5:多任务多视图聚类方法
(1)多任务的理解
-
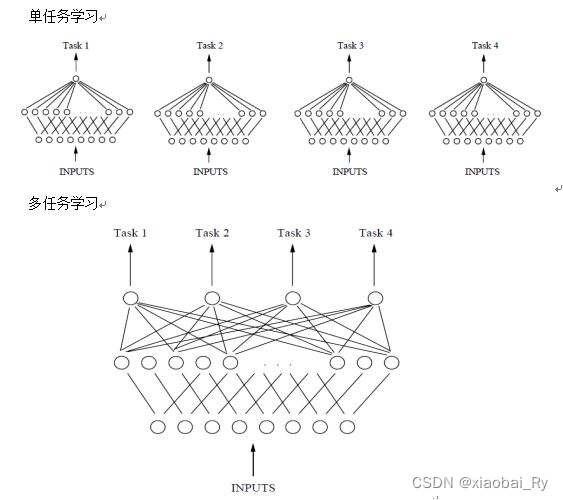
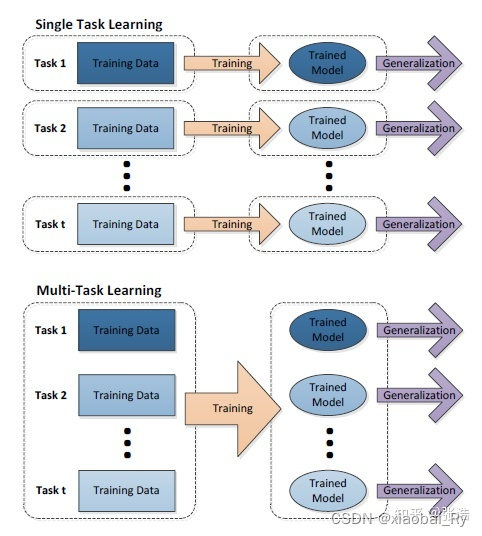
什么是多任务学习?
如果有n个任务(传统的深度学习方法旨在使用一种特定模型仅解决一项任务),而这n个任务或它们的一个子集彼此相关但不完全相同,则称为多任务学习(MTL) 通过使用所有n个任务中包含的知识,将有助于改善特定模型的学习。- 单任务学习:一次只学习一个任务(task),大部分的机器学习任务都属于单任务学习。
- 多任务学习:把多个相关(related)的任务放在一起学习,同时学习多个任务。
-
多任务学习为什么可以提高泛化能力?
多任务学习是一种归纳迁移方法,充分利用隐含在多个相关任务训练信号中的特定领域信息。在后向传播过程中,多任务学习允许共享隐层中专用于某个任务的特征被其他任务使用;多任务学习将可以学习到可适用于几个不同任务的特征,这样的特征在单任务学习网络中往往不容易学到。归纳迁移的目标是利用额外的信息来源来提高当前任务的学习性能,包括提高泛化准确率、学习速度和学习的模型的可理解性。提供更强的归纳偏向是迁移提高泛化能力的一种方法,可以在固定的训练集上产生更好的泛化能力,或者减少达到同等性能水平所需要的训练样本数量。归纳偏向会导致一个归纳学习器更偏好一些假设,多任务学习正是利用隐含在相关任务训练信号中的信息作为一个归纳偏向来提高泛化能力。
-
多任务学习的数据种类?
多任务数据主要可分为以下三类:①同域的多任务数据:多个任务的数据来自于同一领域,例如不同任务的数据是在同一数据库不同时间点收集到的数据。②多域的多任务数据:不同任务中的数据来自于不同的领域,例如不同任务的网页数据来自于不同大学的网站。③多视角的多任务数据:每个任务中的数据包含来自多个视角的特征,例如每个任务中的数据既包含文本特征又包含图像特征。 -
多任务学习数据集的一个示例
WebKB数据集包含从4所大学的计算机科学系网站收集的网页:康奈尔大学、德克萨斯大学、华盛顿大学和威斯康辛州。他们被分为7个类别,我们选择四个人口最多的类别,如课程、教师、项目和学生进行聚集。该数据集有四个任务,每个任务都是集群一个大学的网页。每个任务都有三个观点:四所大学的主要文本中的单词构成了共同的观点,因为任务从主要文本中共享大量的单词;指向本大学网页的超链接和本大学网页标题中的单词分别构成了两个任务特定视图,因为任务从超链接视图和标题视图中共享的单词很少。

(2)多视图多任务

-
概述
多任务多视图聚类实际上是一种联合聚类,即多任务聚类与多视图聚类的联合。多任务多视角聚类需要既充分利用每个任务中数据在多个视角下的特征信息,又利用到不同任务之间的相关知识。而联合聚类是一种同时聚类数据和特征的方法。联合聚类很自然地将多个视角的特征和数据联系起来,即它可以利用多个视角下的特征聚类一起为每个任务学习一个一致的数据聚类结果其次联合聚类在多个任务的共有视角下,对共享特征的聚类过程就是为多个任务学习一个共享子空间的过程。 -
经典架构
包含三个组件:单任务单视角聚类、多视角关系学习和多任务关系学习。- (1)单任务单视角聚类: 该部分通过联合聚类来对每个任务的每个视角下的数据进行聚类,即使用联合聚类处理每个任务的每个视图中的样本和特征,从而完成了整个算法的关键部分,并确保按顺序保存每个任务的每个视图上本地可用的信息,避免负向转移。
- (2)多视角关系学习: 该部分通过多视角数据的一致性假设,即不同视角下的同一数据集会有一致的聚类结果,从而利用多视角下的特征信息提高每个任务的聚类性能。也就是说利用不同视图之间的一致性来提高聚类性能,它可以最大程度地减少每个任务中每对视图下的簇之间的分歧。
- (3)多任务关系学习: 该部分在多个任务的共有视角下,通过联合聚类为这些任务的共享特征进行聚类来学习一个共享子空间,来在多个任务之间迁移特征信息,从而提高每个任务的聚类性能。【通过假设相关任务应共享某些公共或相关特征,使用共聚以便在每个公共视图下的相关任务之间驱动共享子空间。】
总结概括

-
一些说明
上面所提及的子空间分解不仅有基于非负矩阵的构建与分解、还有基于KL散度的构建,而基于多任务多视图的方法不仅有非负矩阵的三因素分解也有二分图匹配方法。总而言之,这里的笔记只记录了一些部分方法,主要是关注矩阵的分解,更多的在参考文献中的论文都可以看到。
多视图聚类的关键问题在于如何有效地利用多个视图中的信息,充分发挥每个视图各自的优势,规避各自的局限,从而获得准确且稳健的聚类性能。一致性原则和互补性原则是多视图学习中的两个重要理论依据,其中,一致性原则旨在最大化多个视图之间的一致性,如多个视图应具有相同的类别结构;互补性原则是指多视图数据的每一个视图都可能包含其他视图所不具备的信息或知识,使用多个视图可以获得更加全面而准确的数据描述。通过调研现有多视角聚类算法可以发现,互补性原则和一致性原则是两个应用在每一个算法中的基本原则。每一个多视角聚类算法几乎都应用了其中的一个原则或者同时应用了这两个原则。因此,如何合理地利用互补性原则和一致性原则是多视角聚类的关键问题。尽管这两个原则保障了多视角聚类算法的有效性,并且多视角聚类也已经取得一些研究进展,但是现有的模型和算法仍然有许多不足。例如,由于协同学习的协同训练机制,基于协同学习的多视角聚类算法在三个视角以上的数据中往往会陷入困境。多核学习算法由于需要进行核函数的运算,因此表现出计算量大的特点。现有的基于图的多视角聚类性能往往依赖于每个视角下的初始图,并且通常需要借助额外的聚类算法输出最终聚类结果。基于子空间的多视角聚类也有初始化依赖现象。另外,多视角聚类算法表现出的计算开销大的问题也鲜有相关的研究。
参考文献
- Multi-view clustering: A survey
- A Survey on Multi-View Clustering[IEEE transactions on artificial intelligence, 2021]
- 多视角数据聚类研究_王浩
- 多视图聚类算法研究_张田田
- 多视图聚类算法综述_何雪梅
- 基于多视图矩阵分解的聚类分析_张祎
- Multi-View Clustering via Concept Factorization with Local Manifold Regularization[• IEEE International Conference on Data Mining (ICDM2016)]
- GOMES: A GROUP-AWARE MULTI-VIEW FUSION APPROACH TOWARDS REAL-WORLD IMAGE CLUSTERING[2015 IEEE INTERNATIONAL CONFERENCE ON MULTIMEDIA & EXPO (ICME)]
- 基于非负矩阵分解的多视图聚类方法研究_张天真
- Multi-Task Multi-View Clustering[IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, 2016]
- 基于非负矩阵分解的大规模异构数据联合聚类
- 基于多视图聚类的疾病分类方法研究_闫佳伟
- 基于子空间学习的多视图聚类方法研究_张越美
- 多任务聚类研究_张晓彤


















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











