







 本文提出RecFormer,一种两阶段自编码器网络,同步提取多视图高级语义表示并恢复丢失数据。通过Transformer架构和循环图约束,模型增强信息交互和几何结构保留,有效提升不完全多视图聚类性能。
本文提出RecFormer,一种两阶段自编码器网络,同步提取多视图高级语义表示并恢复丢失数据。通过Transformer架构和循环图约束,模型增强信息交互和几何结构保留,有效提升不完全多视图聚类性能。
Information Recovery-Driven Deep Incomplete Multiview Clustering Network
现有的不完全多视图聚类方法通常根据先验缺失信息绕过不可用视图,是一种基于回避的次优方案。其他试图恢复丢失信息的方法大多适用于特定的双视图数据集。
基于上述问题,提出了一种信息恢复驱动的深度不完全多视图聚类网络,称为RecFormer
具体而言,构建了一个具有自关注结构的两阶段自编码器网络,以同步提取多个视图的高级语义表示并恢复丢失的数据。此外,开发了一种循环图重建机制,巧妙地利用恢复的视图来促进表示学习和进一步的数据重建。
结合多头自注意机制和多视图学习的特点,设计了Transformer式跨视图自编码器网络。与简单的线性编码器相比,它可以提取高级语义特征,并支持跨视图信息交互,有利于挖掘多视图的互补性。同时,巧妙地将多视图融合表示学习和缺失视图恢复集成到一个统一的框架中。更重要的是,提出了一个结构感知模块(循环图约束),将重构的数据反向推动到表示学习过程中,并允许它们相互协作以实现更好的聚类。
本文符号注记

相关工作:UEAF
文章链接
UEAF的目标是学习所有观点的共识表示(在本工作中为P)。为了做到这一点,Wen等人开发了一个复杂的框架,将视图恢复、共识学习和两个图约束项集成到一个模型中:
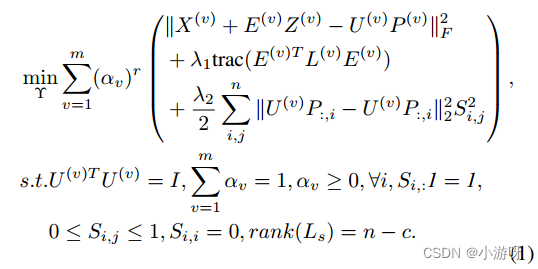
E(v)是用于对缺失实例建模的误差矩阵,Z (v)是转移矩阵从缺少实例到完整视图,U (v)和P (v)是视图v的基矩阵和低维表示。αv是总体中第v个视图的权重,r是平滑参数。Trac(·)表示迹操作符。两个拉普拉斯约束项,即引入了由最近邻图构造的拉普拉斯矩阵L (v)来约束缺失视图的推理,并反向利用另一个最近邻图S来对齐所有恢复的不完整视图。Υ为上述变量的优化目标。
提出的UEAF主要由共识表示学习、反向图正则化和自适应加权不完全多视图学习三个子模型组成。
第一部分是对缺失实例进行补充和学习一致表示P,第二三部分的正则化进行约束。
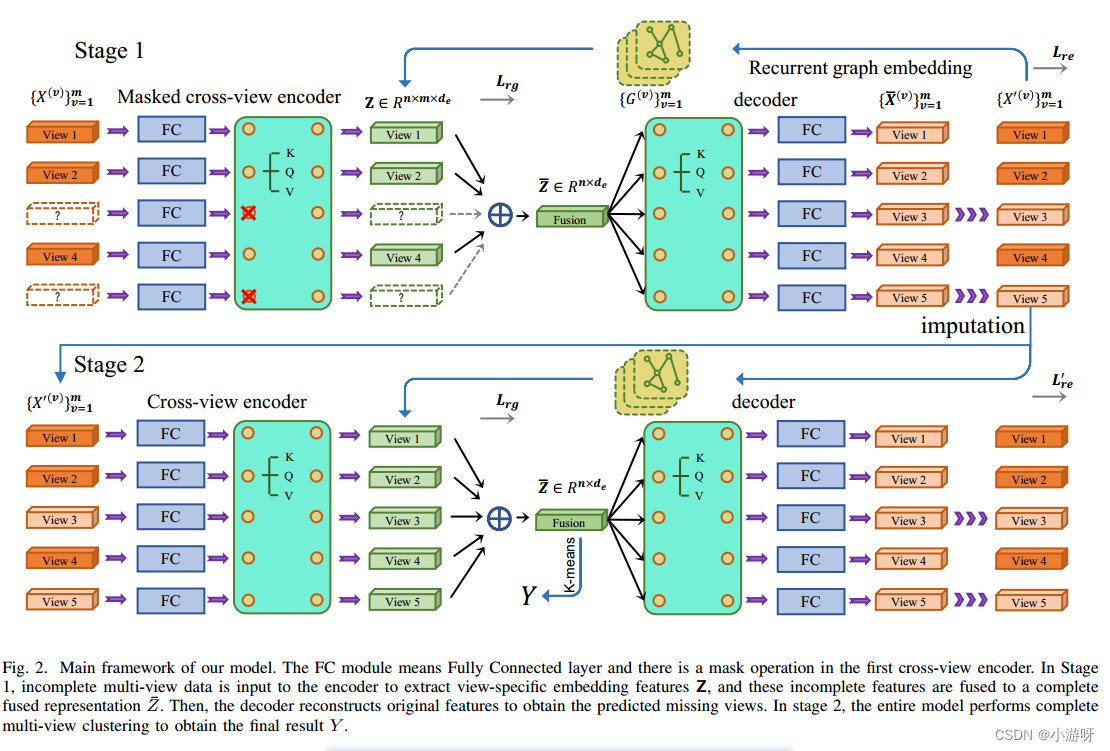
FC模块意味着完全连接层,并且在第一个交叉视图编码器中有一个掩码操作。在第一阶段,将不完整的多视图数据输入到编码器中以提取特定于视图的嵌入特征Z,这些不完整的特征被融合到一个完整的融合表示Z¯。然后,对原始特征进行重构,得到预测的缺失视图。在第二阶段,整个模型执行完整的多视图聚类,得到最终结果Y。
方法
恢复丢失的数据必须基于现有的信息。不同的视图在聚类任务中具有相同的高层语义信息,即它们是对同一个抽象目标的不同描述。缺失数据推理可以看作是一个生成任务,通常通过自编码器网络来实现。设计了一个跨视图自动编码器作为主要框架,其编码器学习高级语义表示,解码器尝试从融合表示中恢复缺失的视图。在统一的自编码器框架中融合近似图构建和缺失视图恢复。
两阶段的训练策略:
阶段1:缺失视图恢复。
阶段2:学习基于恢复数据的多视图聚类表示。
由阶段1中恢复的视图和原始不完整数据组成的新输入数据(近似完整数据)作为阶段2的输入
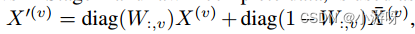
Cross-view编码器
如何利用互补信息??
设计了一个具有多视图信息聚合的Transformer样式的跨视图编码器。首先,需要一组底层的特征提取器来将不同的视图投影到一个公共的特征空间中,这使得后续模块可以并行地处理所有视图的表示。为了简单起见,选择m个完全连接层作为底层特征提取器。
Transformer-style view aggregation module 定义如下:

St∈R m×m表示阶段2中使用的完整视图,阶段1中的注意力屏蔽分数:
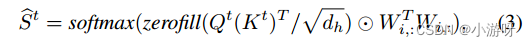
零填充表示用-1e9填充零值的操作,⊙是哈达玛积。这样做的目的是为了在计算交叉视图关注时忽略缺失视图。
At∈R m×dh为头t信息交互的新嵌入特征
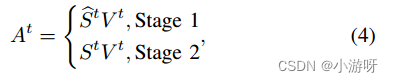
m个视图的最终嵌入特征可计算为A = Concat(A1, A2,…, Ah)∈R m×de。依次将A输入到线性层、层范数模块和多层感知器中,得到每个样本的最终嵌入特征Z∈R m×de
基于受控编码的视图恢复
多视图加权融合,以获得所有视图的共同表示,该方法有望全面表征跨视图的样本。阶段1的加权公式如下:
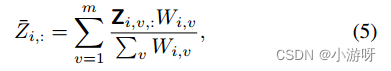
阶段2的加权公式即视图的平均。
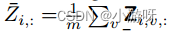
利用现有的原始数据进行部分重构约束,阶段1加权重构损失如下:
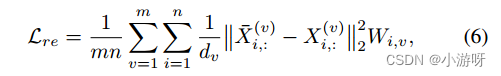
阶段2加权重构损失如下:
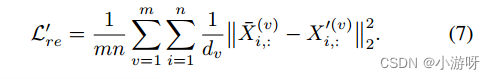
循环图约束
在传统的多视图学习方法中加入图约束,通过构造一个先验邻接矩阵来保持数据的原始内在结构.
一方面,期望得到一个近似完整的邻接图来指导编码器提取高级语义特征。另一方面,更多的判别性语义特征也可以促进缺失视图的恢复,从而有助于构建更真实的图。
循环图约束如下:
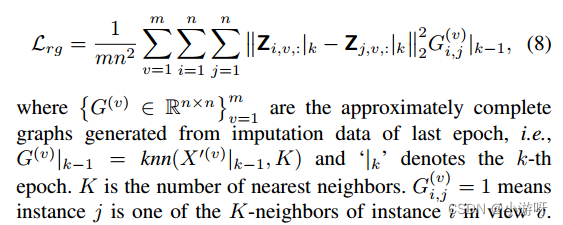
在小批量迭代中训练的,以减少内存开销。邻居图只包含一小批样本,这意味着图约束是局部的而不是全局的。为了平衡小批量训练方法和完整图约束,将小批量训练情况下的Eq.(8)重写为:

在阶段2中,来自阶段1的图G是固定的,而不是由最后一个输出更新的,即G(v) |k−1 = G(v) |k。
阶段1的损失函数:
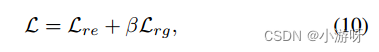
阶段2的损失函数:
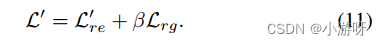
在第二阶段进行了完整的多视图聚类,将第二阶段得到的融合嵌入特征¯Z∈R n×de作为聚类指标矩阵。对¯Z执行K-means,得到最终聚类结果P∈R n×c。需要说明的是,恢复的数据仅用于更新下一个epoch的近似完整图,而不是作为阶段1的输入特征馈送到网络中。复原的数据,在第一阶段的最后阶段输出作为整个第二阶段模型的输入。
在本文中,提出了一种称为RecFormer的新型IMC模型,该模型使用两阶段训练方法来处理各种类型的随机缺失数据。与大多数现有方法不同,方法侧重于巧妙地恢复缺失视图并执行完整的多视图聚类。为了实现这一点,开发了一个Transformer风格的跨视图自动编码器来增强信息交互,并且提出了一个结构感知的循环图约束,该约束促进了不完整视图的恢复和视图内几何结构的保存。这有助于获得更具判别性的语义融合信息。模型的关键创新是利用已知数据和数据固有的几何结构来完成缺失的视图。充分的实验结果证实了RecFormer与其他顶级方法相比具有明显的优势。此外,模型可以很容易地扩展到其他多视图分类或回归模型,通过将一致的表示输入到分类器或回归层中,为不完全多视图学习提供更强大的数据支持。在未来的工作中,计划纳入完整可靠性的度量,使模型能够根据恢复的质量有选择地将恢复的数据填充到缺失的位置。

















 7677
7677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









