




 本文介绍了如何利用Python爬虫抓取游民星空趣图网站的文章链接。通过分析网站的ajax请求,发现可以通过改变jsondata中的page参数获取不同页面的数据。每个页面上,使用XPath定位到文章链接和标题。最后,模拟访问时添加User-Agent头,并生成xls文件存储结果。
本文介绍了如何利用Python爬虫抓取游民星空趣图网站的文章链接。通过分析网站的ajax请求,发现可以通过改变jsondata中的page参数获取不同页面的数据。每个页面上,使用XPath定位到文章链接和标题。最后,模拟访问时添加User-Agent头,并生成xls文件存储结果。
一、分析网站
游民星空的趣图网站为:http://www.gamersky.com/ent/qw/
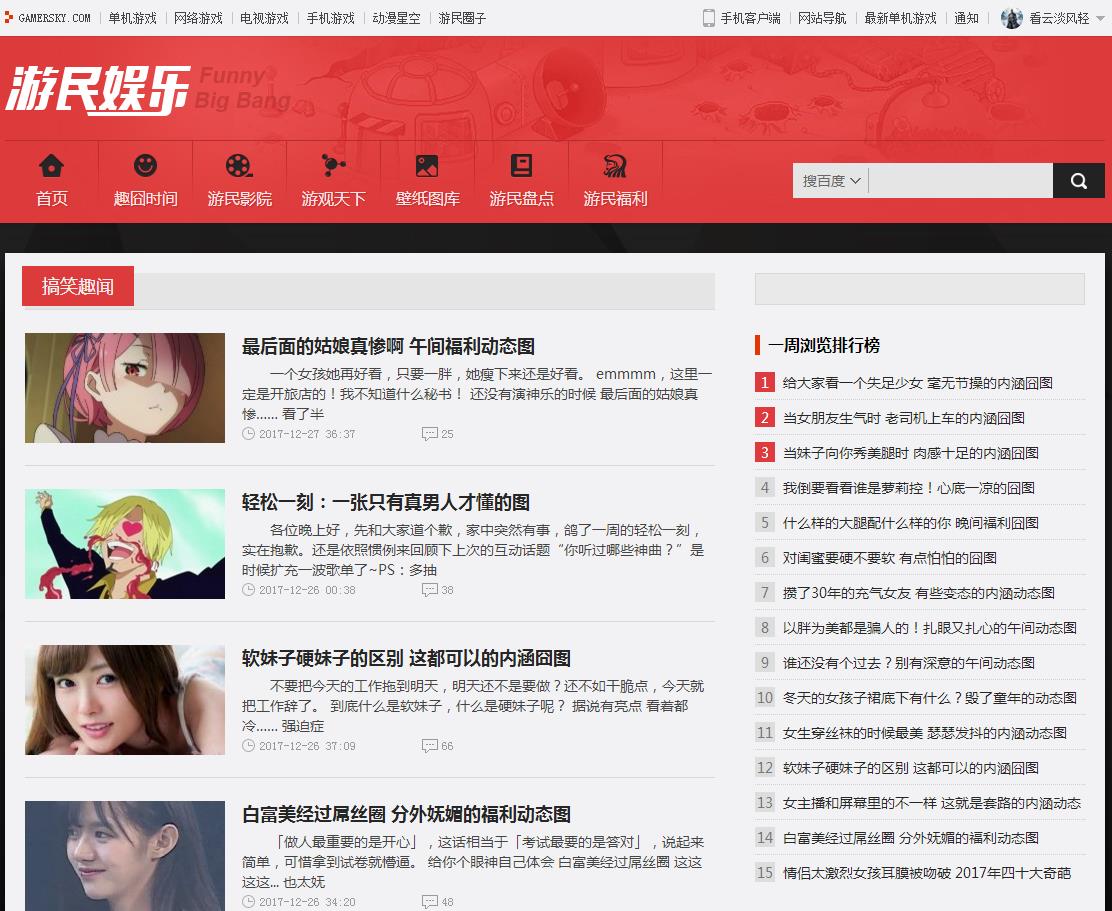
点击下一页可以拉取到数据,但是网址未发生变化,查看Network标签,可以看到实际上进行了ajax请求,
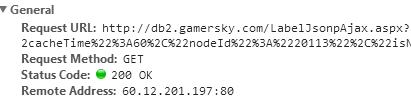
可以看到url地址是另外一个,而且get方法传递了参数:
游民星空的趣图网站为:http://www.gamersky.com/ent/qw/
点击下一页可以拉取到数据,但是网址未发生变化,查看Network标签,可以看到实际上进行了ajax请求,
可以看到url地址是另外一个,而且get方法传递了参数:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























