









一、分析页码
在http://www.gamersky.com/ent/201712/995687.shtml ,中点击下一页,可以发现页面url地址发生了变化:
为http://www.gamersky.com/ent/201712/995687_2.shtml,多了一个下划线加页面数字。
尝试将2改为1:http://www.gamersky.com/ent/201712/995687_1.shtml ,无法打开
二、分析xpath
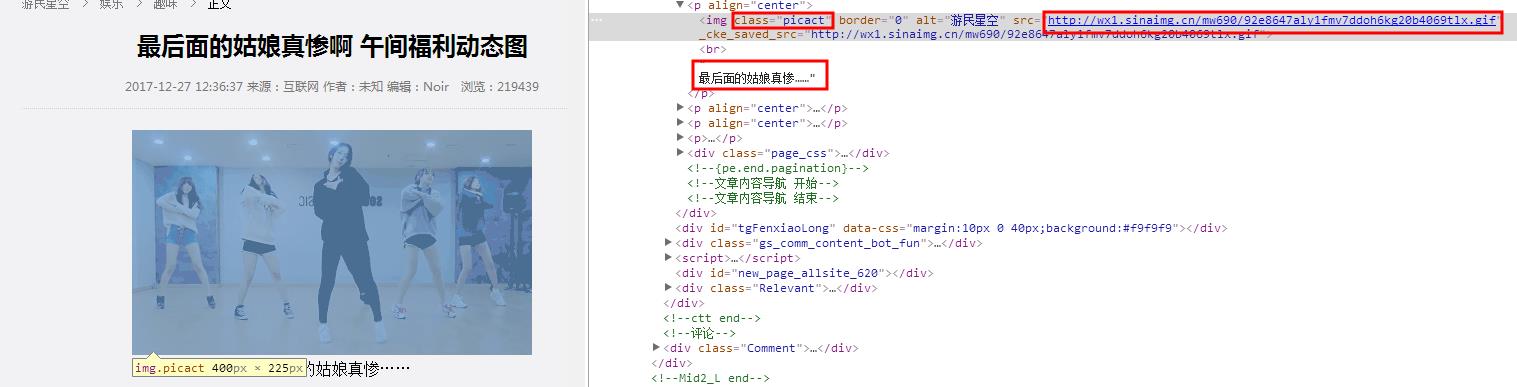
使用xpath("//*[@class='picact']")即可获取当前图片标签,使用(“..”)获取图片标签的父节点,然后获取文本内容即可
三、代码
import requests
from lxml import html
import os
import re
def catch_images(url):
current_page = 1
image_list = []
index = url.index('.shtml')
# 修改页码url
url = "%s%%s%s" % (url[:index], url[index:])
while True:
try:
page = ('_%d' % (current_page,)) if current_page > 1 else ""
respond = requests.get(url=url % (page,))
html_text = respond.content.decode("utf-8")
document = html.fromstring(html_text)
imgs = document.xpath("//*[@class='picact']")
if len(imgs) < 1:
break
for img in imgs:
parent = img.getparent()
src = img.attrib['src'].strip()
_txt = parent.text_content().strip()
txt = src[src.rfind('/') + 1:] if len(_txt) == 0 else _txt
image = {
'url': src,
'txt': txt
}
image_list.append(image)
current_page += 1
except Exception:
break
return image_list
if __name__ == '__main__':
url = "http://www.gamersky.com/ent/201712/995239.shtml"
_list = catch_images(url)
for l in _list:
print(l)
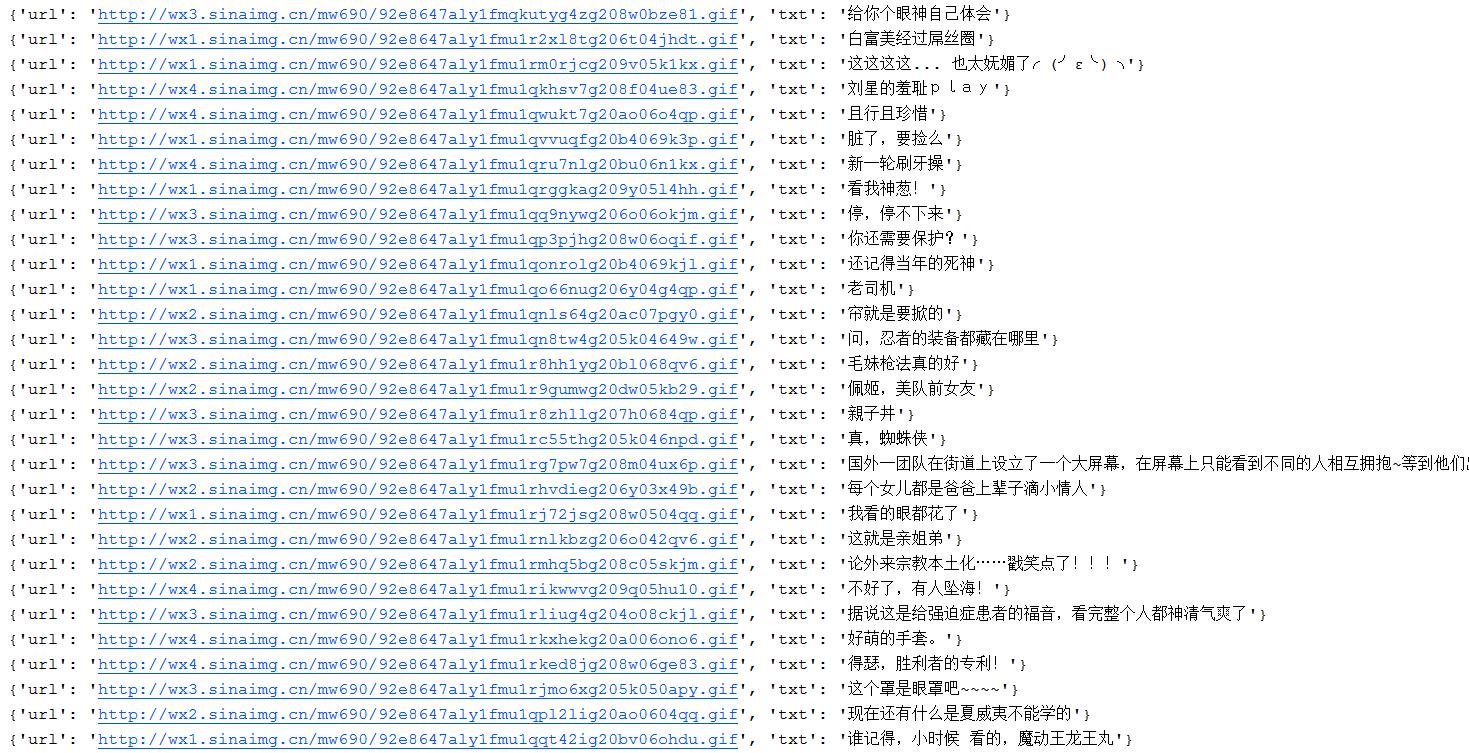
可看到如下输出:
四、额外
保存图片可以用如下代码:
# 获得一个合法文件名
def check_name_valid(name=None):
if name is None:
print("name is None!")
return
reg = re.compile(r'[\\/:*?"<>|\r\n]+')
valid_name = reg.findall(name)
if valid_name:
for nv in valid_name:
name = name.replace(nv, "_")
return name
# 保存图片
# _dir 路径名:"xxxxxx"
# _name 图片名:"xx.gif"
# _url 图片网络地址
def save_image(_dir, _name, _url):
# 创建指定目录路径,在当前路径\images\xx
dir_path = os.path.join("images", _dir)
# 不存在则创建
if not os.path.exists(dir_path):
os.makedirs(dir_path)
# 文件名合法化
_name = check_name_valid(_name)
# 获得文件后缀
ext = _url[_url.rfind('.'):]
file_path = os.path.join(dir_path, _name + ext)
if os.path.exists(file_path):
return True
with open(file_path, 'wb') as file:
# content获取二级制格式
respond = requests.get(_url).content
#保存图片
file.write(respond)
print("image save in %s", file_path)
return True至此,只需要将上一节中抓取的所有文章链接传递给 catch_images 然后将获取到的图片url进行下载即可:

最后一步的代码:
import gamesky_fun as gf # 该模块中仅包含本页面中的三个方法
import xlrd
import xlwt
import os
from xlutils3 import copy
DOWN_LIST_FILE = 'gamesky_fun_down_list.xls'
LIST_FILE = 'gamesky_fun_list.xls'
SHEET_NAME = "list"
def down():
mod_book = None
mod_sheet = None
if not (os.path.exists(DOWN_LIST_FILE)):
mod_book = xlwt.Workbook(encoding='utf-8')
mod_sheet = mod_book.add_sheet(SHEET_NAME, cell_overwrite_ok=True)
else:
read_book = xlrd.open_workbook(DOWN_LIST_FILE)
mod_book = copy.copy(read_book)
mod_sheet = mod_book.get_sheet(SHEET_NAME)
list_book = xlrd.open_workbook(LIST_FILE)
table = list_book.sheet_by_name(SHEET_NAME)
table_len = table.nrows
try:
for i in range(table_len - 1, 0, -1):
url, title = check_down(i)
if url is None:
url = table.cell(i, 0).value
title = table.cell(i, 1).value
print(url, title)
print("Catching Image Url")
images = gf.catch_images(url)
_dir = title
for img in images:
print(img)
ret = gf.save_image(_dir, img['txt'], img['url'])
print("save:%s" % (ret,))
else:
print("continue")
mod_sheet.write(i, 0, url)
mod_sheet.write(i, 1, title)
mod_sheet.write(i, 2, i)
mod_book.save(DOWN_LIST_FILE)
print("ok :%d" % (i,))
finally:
mod_book.save(DOWN_LIST_FILE) # 保存文件
def check_down(_id):
if not (os.path.exists(DOWN_LIST_FILE)):
return False
wordbookrd = xlrd.open_workbook(DOWN_LIST_FILE)
table = wordbookrd.sheet_by_name(SHEET_NAME)
table_len = table.nrows
for i in range(table_len):
if table.cell(i, 2).value == _id:
return table.cell(i, 0).value, table.cell(i, 1).value
return None, None
if __name__ == "__main__":
down()

















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









