







Reptilien 03: analyse Von daten
正则表达式

一、正则表达式的简介
1、 概念
- 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、特定字符的组个,自称一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种逻辑过滤。
2、正则表达式的应用场景
- 表单验证(如:手机号、邮箱、身份证…)
- 爬虫
二、正则表达式对python的支持
1、普通字符
- 字母、数字、汉字、下划线、以及没有特殊定义的符号,都是"普通字符"。正则表达式中的普通字符,在匹配的时候,只匹配与自身相同的一个字符。
- 例如:表达式c,在匹配字符串abcde时,匹配结果是:成功;匹配到的内容是c;匹配到的位置开始于2,结束于3。(注:下标从0开始还是从1开始,因当前编程语言的不同而可能不同)
2、match()函数
- 语法:
match(pattern, string, flags=0) - 第一个参数是正则表达式,如果匹配成功,则返回一个match对象,否则返回一个None。
- 第二个参数表示要匹配的字符串。
- 第三个参数是标致位用于控制正则表达式的匹配方式 如: 是否区分大小写,多行匹配等等。
扩展:标识位
| 修饰符 | 描述 |
|---|---|
| re.I | 忽略大小写 ( IGNORE CASE ) |
| re.L | 做本地化识别(locale-aware)匹配 ( LOCALE ) |
| re.M | 多行模式(MULTILINE ) |
| re.S | 使’.'特殊字符匹配任何字符,包括换行 ;如果没有此标志, '.'将匹配任何内容除换行符。( DOTALL ) |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. ( UNICODE ) |
| re.X | 标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 ( VERBOSE ) |
代码演示:
import re
'''
pattern--->正则表达式:如果匹配成功,则返回一个match对象,否则返回一个None
string--->需要匹配的数据
flags=0--->标致位:控制正则表达式的匹配方式(是否需要换行匹配,是否区分大小写......)
# match函数只能从开头匹配,不能从其他位置匹配
'''
# re.match(pattern, string, flags=0)
s = 'python and java'
pattern = 'python' # 正则表达式
result = re.match(pattern, s)
if result:
# print(result) # 返沪:<re.Match object; span=(0, 6), match='python'>
print(result.group()) # 返沪:python
else:
print('没有匹配!')
3、元字符
- 正则表达式中使用了很多元字符,用来表示一些特殊的含义或功能。

- 一些无法书写或者具有特殊功能的字符,采用在前面加斜杠” / “的方法。

- 尚未列出的还有问号” ? “、星号” * “和括号”()“等其他的符号。所有正则表达式中具有特殊含义的字符在匹配自身的时候,都要使用斜杠进行转义。这些转义字符的匹配用法与普通字符类似,也是匹配与之相同的一个字符。
4、预定义匹配字符集
- 正则表达式中的一些表示方法,可以同时匹配某个预定义字符集中的任意一个字符。比如,表达式\d可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,而不是多个

代码演示:
import re
'''
01:\d--表示匹配0-9当中的任意一个字符
'''
result1 = re.match(r'\d', '123').group()
print(result1)
'''
02:\w--表示匹配任意一个字母或数字或下划线,即0-9、a-z、A-Z
'''
result2 = re.match(r'\w', '123').group()
print(result2)
result3 = re.match(r'\w', 'a123').group()
print(result3)
result4 = re.match(r'\w', 'A123').group()
print(result4)
'''
03:\s--表示匹配空格、制表符、其他的一些空白
'''
result5 = re.match(r'\s', ' ').group()
print(result5)
'''
04:\D(\d的反集--表示非数字当中的任意一个
'''
result6 = re.match(r'速度与激情\D', '速度与激情a').group()
print(result6)
'''
05:\W(\w的反集)--表示匹配一些特殊符号
'''
result7 = re.match(r'\W', '&^%%').group()
print(result7)
'''
06:\S(\s的反集)--表示匹配除了空格、制表符、其他的一些空白的任意字符
'''
result8 = re.match(r'\S', 'sdsdfasd').group()
print(result8)
result9 = re.match(r'\S', '158532').group()
print(result9)
5、重复匹配
- 前面的表达式,无论是只能匹配一种字符的表达式,还是可以匹配多种字符其中任意一个的表达式,都只能匹配一次。但是有时候我们需要对某个字段进行重复匹配,例如手机号码13666666666,一般的新手可能会写成\d\d\d\d\d\d\d\d\d\d\d(注意,这不是一个恰当的表达式),不但写着费劲,看着也累,还不⼀定准确恰当。
- 这种情况可以使用表达式再加上修饰匹配次数的特殊符号{},不但重复书写表达式就可以重复匹配。例如[abcd][abcd]可以写成[abcd]{2}

import re
'''
# {n}:表达式重复n次。
'''
# 代码演示
result1 = re.match(r'\d{3}', '123').group()
print(result1)
result2 = re.match(r'^1[345678]\d{9}$', '15840039263').group()
print(result2)
'''
# {m,n}:表达式至少重复m次,最多重复n次。
'''
# 代码演示
result3 = re.match(r'\d{3,4}-\d{7,8}', '0123-1234567').group()
print(result3)
'''
# {m,}:表达式至少重复m次。
'''
# 代码演示
result4 = re.match(r'\d{3,}-\d{7,8}', '012-1234567').group()
print(result4)
'''
# ?:匹配表达式0次或者1次
'''
# 代码演示
result9 = re.match(r'w[a-z]?', 'wa').group()
print(result9)
result10 = re.match(r'w[a-z]?', 'wae').group()
print(result10)
'''
# +:表达式匹配至少出现1次
'''
# 代码演示
result7 = re.match(r'w[a-z]+', 'weasd').group()
print(result7)
# result8 = re.match(r'w[a-z]+', 'w').group()
# print(result8) # 报错
'''
# *:表达式出现0次到任意次,相当于{0,}
'''
# 代码演示
result5 = re.match(r'w[a-z]*', 'wfadasd').group()
print(result5)
result6 = re.match(r'w[a-z]*', 'w').group()
print(result6)
6、位置匹配与非贪婪模式
①、位置匹配
- 有时候,我们对匹配出现的位置有要求,比如开头、结尾、单词之间等等

②、贪婪与非贪婪模式
- 在重复匹配时,正则表达式默认总是尽可能多的匹配,这被称为贪婪模式。例如,针对文本dxxxdxxxd,表达式(d)(\w+)(d)中的\w+将匹配第一个d和最后一个d之间的所有字符xxxdxxx。可见,\w+在匹配的时候,总是尽可能多的匹配符合它规则的字符。同理,带有?、*和{m,n}的重复匹配表达式都是尽可能地多匹配。
- 校验数字的相关表达式:

- 特使场景的表达式:

代码演示01:贪婪与非贪婪模式
import re
'''
# 贪婪匹配:以最长的结果做为返回,在python当中是默认贪婪的,总是尝试去匹配尽可能多的字符
'''
s = '<div>abc</div><div>bcd</div>'
# '''
# 需求:<div>abc</div>
# '''
ptn = '<div>.*</div>'
r = re.match(ptn, s)
print(r.group()) # <div>abc</div><div>bcd</div>
'''
# 非贪婪模式:总是尝试去匹配尽可能少的字符
# 怎么使用非贪婪模式:在.*加上?,在.+加上?或者{m, n}
'''
s = '<div>abc</div><div>bcd</div>'
'''
需求:<div>abc</div>
'''
ptn = '<div>.*?</div>'
r = re.match(ptn, s)
print(r.group())
打印输出结果:
C:\python\python.exe D:/PycharmProjects/Python大神班/day-06/01-非贪婪匹配.py
<div>abc</div><div>bcd</div>
<div>abc</div>
Process finished with exit code 0
代码演示02:正则表达式练习
import re
def fn(ptn, list):
for x in list:
result = re.match(ptn, x)
if result:
print('匹配成功!', '匹配结果是:', result.group())
else:
print(x, '匹配失败!')
# . :表示匹配除了换行符的任意字符
list = ['abc1', 'ab', 'aba', 'abbcd', 'other', 'another']
ptn = 'ab.'
fn(ptn, list)
# [] : 匹配中括号中列举的字符
list = ['man', 'mbn', 'mcn', 'mdn', 'mon', 'nba']
ptn = 'm[abcd]n'
fn(ptn, list)
# \d :匹配数字【0-9】
list = ['py9', 'py3', 'other', 'pyxx']
ptn = 'py\d'
fn(ptn, list)
# \D :匹配非数字的字符
list = ['py9', 'py3', 'other', 'pyxx']
ptn = 'py\D'
fn(ptn, list)
# \s :匹配空白字符
list= ['hello world', 'helloxxx', 'hello,world']
ptn = 'hello\sworld'
fn(ptn, list)
# \w :匹配单词、字母、下划线
list = ['1-age', 'a-age', '#-age', '_-age']
ptn = '\w-age'
fn(ptn, list)
# * :表示匹配出现0次或任意次
list = ['hello', 'abc', 'xxx', 'h']
ptn = 'h[a-z]*'
fn(ptn, list)
# {m} :表示匹配至少m次
list = ['hello', 'python', '^%%&%^#^$%', '123456']
ptn = '\w{6}'
fn(ptn, list)
# {m, n} :表示至少匹配m次,最多匹配n次
list = {
'abcd', 'python', '*&%%*&*&', '_xxx211', '65465465'}
ptn = '\w{3, 5}'
fn(ptn, list)
# $ : 表示匹配带该字符(¥)结束
list = ['123@qq.com', 'abc@yy.com', 'bcd@qq.com.cm']
ptn = '\w+@qq.com$'
fn(ptn, list)
打印输出结果:
C:\python\python.exe D:/PycharmProjects/Python大神班/day-06/02-正则表达式练习.py
匹配成功! 匹配结果是: abc
ab 匹配失败!
匹配成功! 匹配结果是: aba
匹配成功! 匹配结果是: abb
other 匹配失败!
another 匹配失败!
匹配成功! 匹配结果是: man
匹配成功! 匹配结果是: mbn
匹配成功! 匹配结果是: mcn
匹配成功! 匹配结果是: mdn
mon 匹配失败!
nba 匹配失败!
匹配成功! 匹配结果是: py9
匹配成功! 匹配结果是: py3
other 匹配失败!
pyxx 匹配失败!
py9 匹配失败!
py3 匹配失败!
other 匹配失败!
匹配成功! 匹配结果是: pyx
匹配成功! 匹配结果是: hello world
helloxxx 匹配失败!
hello,world 匹配失败!
匹配成功! 匹配结果是: 1-age
匹配成功! 匹配结果是: a-age
#-age 匹配失败!
匹配成功! 匹配结果是: _-age
匹配成功! 匹配结果是: hello
abc 匹配失败!
xxx 匹配失败!
匹配成功! 匹配结果是: h
hello 匹配失败!
匹配成功! 匹配结果是: python
^%%&%^#^$% 匹配失败!
匹配成功! 匹配结果是: 123456
python 匹配失败!
abcd 匹配失败!
*&%%*&*& 匹配失败!
_xxx211 匹配失败!
65465465 匹配失败!
匹配成功! 匹配结果是: 123@qq.com
abc@yy.com 匹配失败!
bcd@qq.com.cm 匹配失败!
Process finished with exit code 0
三、re模块的常用方法

- compile(pattern, flags=0)
这个⽅法是re模块的工厂法,⽤于将字符串形式的正则表达式编译为Pattern模式对象,可以实现更加效率的匹配。第二个参数flag是匹配模式 使用compile()完成一次转换后,再次使用该匹配模式的时候就不能进行转换了。经过compile()转换的正则表达式对象也能使用普通的re⽅法
1、flag匹配模式
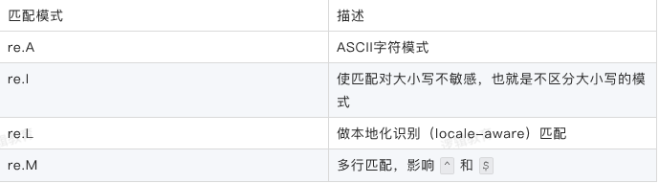
2、search(pattern, string, flags=0)函数
- 在文本内查找,返回第一个匹配到的字符串。它的返回值类型和使用方法与match()是一样的,唯一的区别就是查找的位置不用固定在文本的开头
3、findall(pattern, string, flags=0)函数
- 作为re模块的三大搜索函数之一,findall()和match()、search()的不同之处在于,前两者都是单值匹配,找到一个就忽略后面,直接返回不再查找了。而findall是全文查找,它的返回值是一个匹配到的字符串的列表。这个列表没有group()方法,没有start、end、span,更不是一个匹配对象,仅仅是个列表!如果一项都没有匹配到那么返回一个空列表。
4、split(pattern, string, maxsplit=0, flags=0)函数
- re模块的split()方法和字符串的split()方法很相似,都是利用特定的字符去分割字符串。但是re模块的split()可以使用正则表达式,因此更灵活,更强大。
5、sub(pattern, repl, string, count=0, flags=0)函数
- sub()方法类似字符串的replace()方法,用指定的内容替换匹配到的字符,可以指定替换次数
代码演示:
import re
# compile()--根据包含的正则表达式的字符串创建模式对象,返回正则表达式对象(re对象)
pat = re.compile(r'abc')
res = pat.match('abc123').group()
print(res)
# re.I-->表示不区分大小写匹配
pat = re.compile(r'abc', re 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2060
2060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









