






软硬总归是不能分家。上一章简单介绍了CUDA的编程模型,本章学习主要关于CUDA的相关硬件架构、线程执行的本质,以及CUDA在线程级并行的一些优化方法,比如规约问题。话不多数,开始学习。
GPU实际上是由多个流式多处理器构建的处理器阵列(可以这样理解,当然所有SM会由GPU管理,并非完全独立)。先上一张经典Fermi架构的GPU的SM示意图。需要注意的是,以下结构实际上只是 GPU的compute部分,不包含图形渲染、3d等结构。
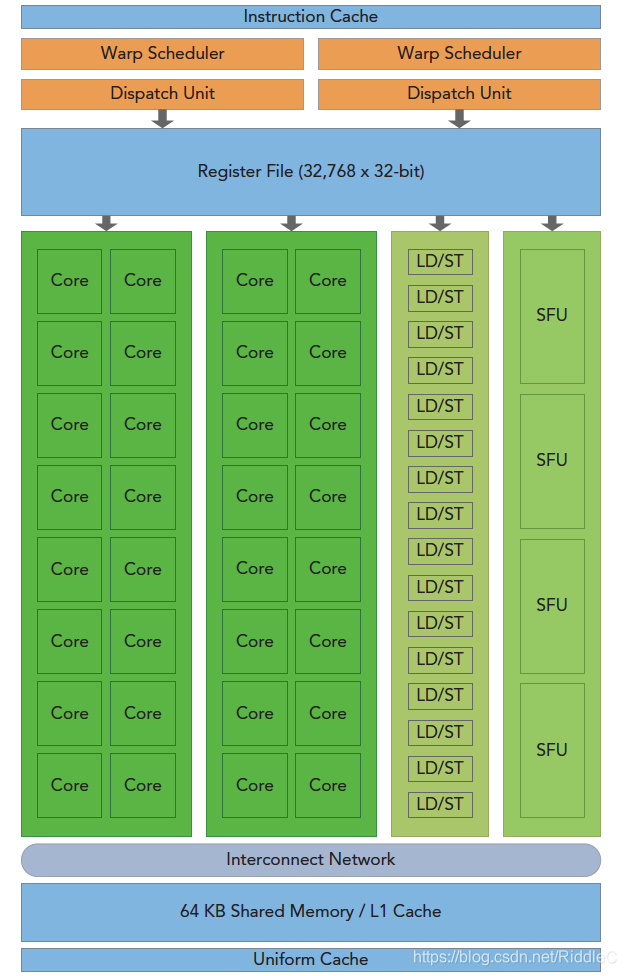
由图可以知道,一个SM主要包括以下构成部分:
1、CUDA核心:又称为SP(stream processor),加速器核心
2、线程束调度器
3、寄存器文件
4、共享内存/一级缓存
5、加载/存储单元(LD/ST)
6、特殊功能单元(SFU)
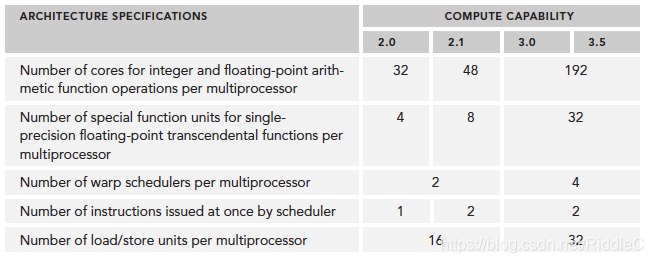
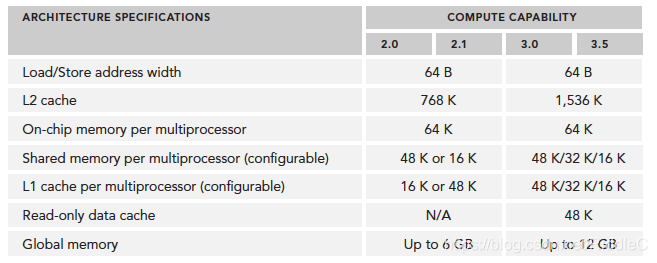
CUDA核心有一个全流水线的整数运算逻辑单元(ALU)和一个浮点运算逻辑单元(FPU),每个时钟周期执行一个整数或浮点数指令。CUDA核心被组织到SM中,在开普勒架构中,一个SM有32个CUDA核心。当然不同的显卡会有差异,如博主所用的GT 820M老爷机,Fermi架构,只有2个SM,但每个SM有48个CUDA核心,共计96个(实际上少的可怜,还没有嵌入式的TX系列多)。Fermi架构最多支持6GB的全局内存。CPU与GPU通过PCIe总线连接。Fermi上支持同时并发执行内核。并发执行内核允许执行一些小的内核程序来充分利用GPU,最多允许16个kernel同时运行,当然具体数量要与硬件资源、数据量相匹配,个人理解,若是数据量足够大或者kernel操作足够占用所有硬件资源,同时开辟的内核只能串行执行。
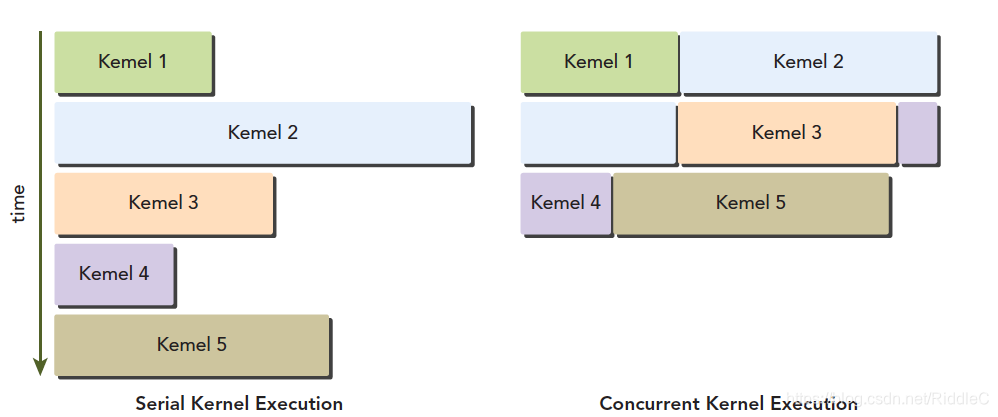
当启动一个线程网格时,线程块被分配在可用的SM上来执行。当一个block被调度到一个SM上,其所有线程都在此SM上执行。多个线程块可以被分配到同一个SM上,由调度器根据硬件资源分配。GPU有全局调度器,将block分配,各SM有2个warp调度器和指令分派单元。同一线程中的指令利用指令级并行进行流水线化。注意:各thread的并行为线程级并行。
CUDA采用单指令多线程模式来管理、执行线程,每32个线程为一组,即一个warp(因此一个block的维度最好为32或16的倍数,为为什么是16?一个SM有16个LD/ST单元,每个时钟周期计算半个warp的源地址和目的地址)。SIMT与SIMD的不同在于,虽然两者都广播指令,但SIMT允许属于一个warp的thread独立执行,因为每一个线程有自己的指令地址计数器(PC)和寄存器状态。
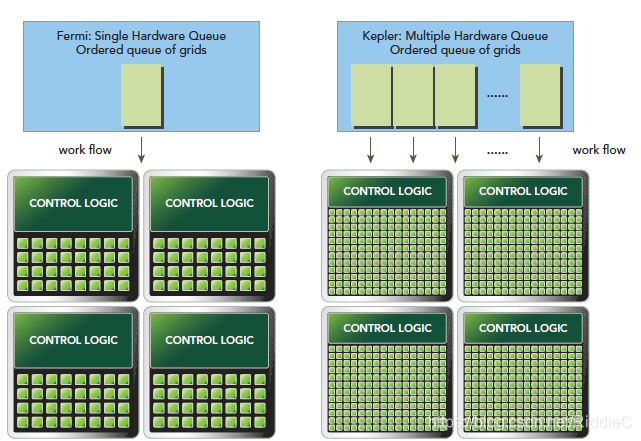
在Fermi架构之后,英伟达发布了Kepler架构。因为不同的GPU的SM数量、CUDA都有差异,这里不再总结Kepler的数量(也可能是博主没有理解这一块内容)。
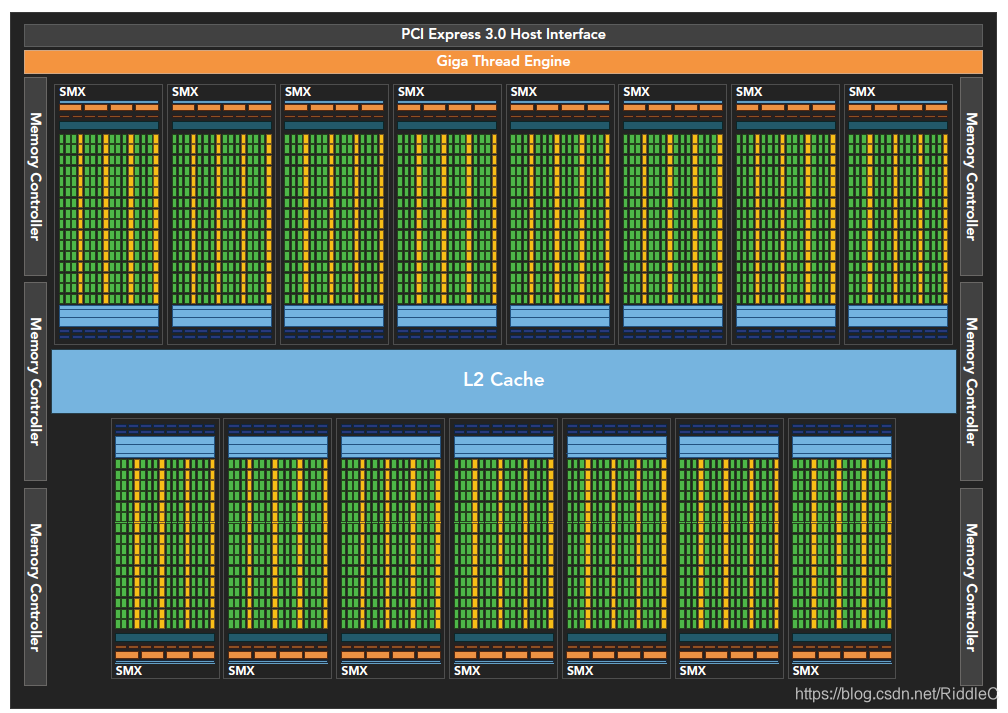
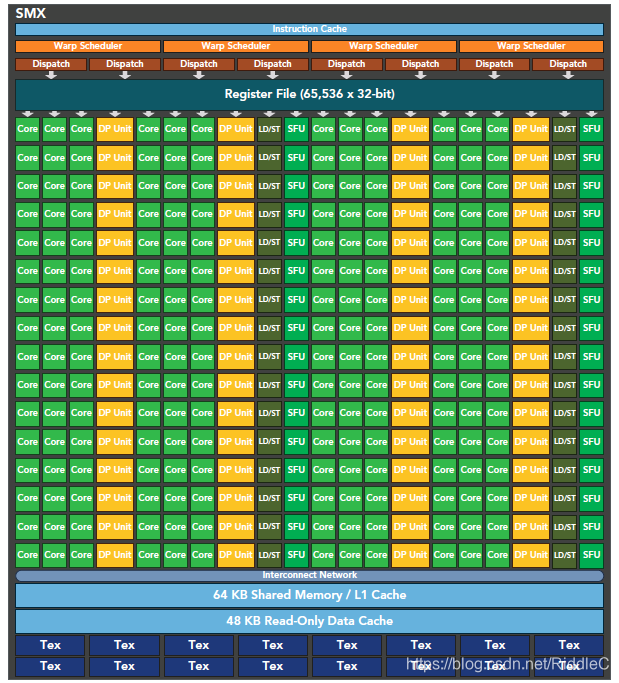
由硬件图示,每个SM的线程束调度器增加为4个,指令调度器增加为8个。此时在单一的SM上可以同时发送和执行4个线程束。寄存器文件的大小也增加为64k。
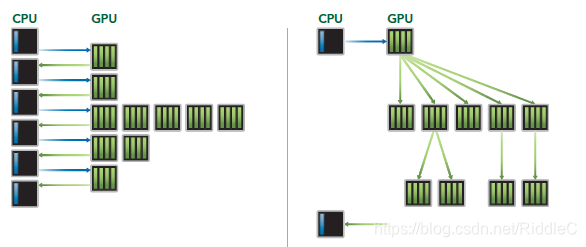
除了硬件上的不同造成的线程级并行性能差异,Kepler架构还提出了动态并行技术(Hyper-Q),简单的说,支持从kernel中调用其他kernel,实现类似递归算法的效果,形成工作队列,增加GPU的利用率,也减少CPU的空闲时间。这一技术会与流中的i相关技术相关,后面会详细介绍。前文提到Fermi架构允许多个内核同时存在,实际上是类似串行的工作队列,而在Kepler上可以实现更多的工作队列并行,类似任务级的并行。
值得一提的是,限制CUDA内核性能主要有3个方面:
1、存储带宽
2、计算资源
3、指令和内存延迟
这将是我们优化性能的重点方向。下一篇我们将跟随书本来介绍线程束的本质和分化造成的延迟。大家加油学习呀,CUDA能成!Fighting!














 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









